Das könnte Ihnen auch gefallen
- The Color of God: America, the Church, and the Politics of RaceVon EverandThe Color of God: America, the Church, and the Politics of RaceNoch keine Bewertungen
- PvsystDokument44 SeitenPvsystSgfvv100% (1)
- The Secrets of Distinction: Volume 1 the 08 Keys of DistinctionVon EverandThe Secrets of Distinction: Volume 1 the 08 Keys of DistinctionNoch keine Bewertungen
- The Impact of Artificial Intelligence On InnovationDokument4 SeitenThe Impact of Artificial Intelligence On InnovationInternational Journal of Innovative Science and Research Technology100% (1)
- Charles Finney - Experiencing The Presence of God: Spiritual GrowthDokument1 SeiteCharles Finney - Experiencing The Presence of God: Spiritual GrowthGodwin Ariwodo0% (1)
- Huawei Final Written Exam 2.2 AttemptsDokument19 SeitenHuawei Final Written Exam 2.2 AttemptsJonafe PiamonteNoch keine Bewertungen
- Hcia Ai Aug2Dokument5 SeitenHcia Ai Aug2Jonafe PiamonteNoch keine Bewertungen
- The God of My Man of God: the Spirit Behind the Mantle!Von EverandThe God of My Man of God: the Spirit Behind the Mantle!Noch keine Bewertungen
- How to Shake the Unshakable by the True Anointing: The True MannaVon EverandHow to Shake the Unshakable by the True Anointing: The True MannaNoch keine Bewertungen
- Rails 4 in Action: Revised Edition of Rails 3 in ActionVon EverandRails 4 in Action: Revised Edition of Rails 3 in ActionNoch keine Bewertungen
- A Blessing in the Storm... Muscular Dystrophy messed up my life and made me whole: Volume TwoVon EverandA Blessing in the Storm... Muscular Dystrophy messed up my life and made me whole: Volume TwoNoch keine Bewertungen
- Trouble Shooting On Internet Connection ProblemsDokument6 SeitenTrouble Shooting On Internet Connection ProblemsSalam Alecu0% (1)
- Nav2013 Enus Csintro 02Dokument50 SeitenNav2013 Enus Csintro 02Cesar Alexander Gutierez RuedaNoch keine Bewertungen
- Without Faith, You Cannot Please GodDokument13 SeitenWithout Faith, You Cannot Please GodGrace Church ModestoNoch keine Bewertungen
- Jan-12 Sep-13 Jun-13 Mar-13 Jan-13 Sep-14 Jun-14 Mar-14 Dec-14 Sep-15 Jun-15 Mar-15 Dec-13 Oct-16 Jun-16 Mar-17 Jan-18 Jun-18 Dec-18 YearDokument4 SeitenJan-12 Sep-13 Jun-13 Mar-13 Jan-13 Sep-14 Jun-14 Mar-14 Dec-14 Sep-15 Jun-15 Mar-15 Dec-13 Oct-16 Jun-16 Mar-17 Jan-18 Jun-18 Dec-18 YearsyedNoch keine Bewertungen
- Atalonia The Difficult Path Towards Independence: Sebastian D. Baglioni Carleton University March 11, 2015Dokument16 SeitenAtalonia The Difficult Path Towards Independence: Sebastian D. Baglioni Carleton University March 11, 2015Haeshan NiyarepolaNoch keine Bewertungen
- Indian Stock Market AnalysisDokument36 SeitenIndian Stock Market AnalysisTushar GangolyNoch keine Bewertungen
- 2014 Deepa Puthran Forecasting Global Turbocharger Market A Mixed Method ApproachDokument5 Seiten2014 Deepa Puthran Forecasting Global Turbocharger Market A Mixed Method ApproachShiv PrasadNoch keine Bewertungen
- Manpower Detail - Sanction Vs ActualDokument6 SeitenManpower Detail - Sanction Vs ActualscribdyogeshNoch keine Bewertungen
- Multivariate Time Series Forecasting of Crude PalmDokument10 SeitenMultivariate Time Series Forecasting of Crude PalmJose FerreiraNoch keine Bewertungen
- Eclectica Absolute Macro Fund: Manager CommentDokument3 SeitenEclectica Absolute Macro Fund: Manager Commentfreemind3682Noch keine Bewertungen
- Loan E.M.I. Calculator: Data To EnterDokument10 SeitenLoan E.M.I. Calculator: Data To EnterNanjunda SwamyNoch keine Bewertungen
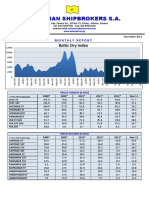
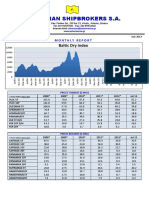
- Athenian Shipbrokers S.A.: Baltic Dry IndexDokument17 SeitenAthenian Shipbrokers S.A.: Baltic Dry IndexgeorgevarsasNoch keine Bewertungen
- Solr and Lucene Search RevolutionDokument27 SeitenSolr and Lucene Search RevolutionErvin MillerNoch keine Bewertungen
- Athenian Shipbrokers - Monthy Report - 14.08.15Dokument17 SeitenAthenian Shipbrokers - Monthy Report - 14.08.15georgevarsasNoch keine Bewertungen
- MEF Analysis UI Claims - March 2020Dokument2 SeitenMEF Analysis UI Claims - March 2020Dave AllenNoch keine Bewertungen
- Inflation Rates: The Cost of LivingDokument6 SeitenInflation Rates: The Cost of LivingAnonymous QKHeLscy2kNoch keine Bewertungen
- SageOne Investor Memo May 2018Dokument10 SeitenSageOne Investor Memo May 2018Akhil ParekhNoch keine Bewertungen
- Forecasting Seasonal Time Series DecompositionDokument32 SeitenForecasting Seasonal Time Series DecompositionManuel Alejandro Sanabria AmayaNoch keine Bewertungen
- Outlook For The SMSF SectorDokument13 SeitenOutlook For The SMSF SectorRomeoNoch keine Bewertungen
- Presentation FY2014Dokument26 SeitenPresentation FY2014Vlad KremerNoch keine Bewertungen
- Copyright and The Evolving Learning Materials Market - Campus Stores CanadaDokument6 SeitenCopyright and The Evolving Learning Materials Market - Campus Stores CanadaAn Michael Powell100% (2)
- TAKAFUL IKHLAS March - 2020 - EngDokument6 SeitenTAKAFUL IKHLAS March - 2020 - EngEncik ArifNoch keine Bewertungen
- Athenian-Shipbrokers-May 2016Dokument17 SeitenAthenian-Shipbrokers-May 2016Nguyen Le Thu HaNoch keine Bewertungen
- UQ-II - Summer 2021-Class ReportDokument1 SeiteUQ-II - Summer 2021-Class ReportdaudNoch keine Bewertungen
- 95 - Emerging India Portfolio-March2019 - Final Email VersionDokument22 Seiten95 - Emerging India Portfolio-March2019 - Final Email VersionTarunAnandaniNoch keine Bewertungen
- Athenian Shipbrokers - Monthy Report - 13.11.15 PDFDokument20 SeitenAthenian Shipbrokers - Monthy Report - 13.11.15 PDFgeorgevarsas0% (1)
- Athenian-Shipbrokers-April 2013Dokument18 SeitenAthenian-Shipbrokers-April 2013Nguyen Le Thu HaNoch keine Bewertungen
- ExchangeRateForecasts 0914 PDFDokument5 SeitenExchangeRateForecasts 0914 PDFPavala AyyanarNoch keine Bewertungen
- Athenian-Shipbrokers-July 2013Dokument18 SeitenAthenian-Shipbrokers-July 2013Nguyen Le Thu HaNoch keine Bewertungen
- Urea Plant Safety PDFDokument14 SeitenUrea Plant Safety PDFashwaniNoch keine Bewertungen
- Using Big Data To Improve Clinical CareDokument32 SeitenUsing Big Data To Improve Clinical CareXiaodong WangNoch keine Bewertungen
- Rama East Rama Office Building East Rama East Rama Office Building EastDokument1 SeiteRama East Rama Office Building East Rama East Rama Office Building EastAlex WoodwickNoch keine Bewertungen
- Kcaa Mlolongo-GamojiDokument1 SeiteKcaa Mlolongo-GamojisatejaNoch keine Bewertungen
- Expense BookDokument18 SeitenExpense BookAjay Kumar DNoch keine Bewertungen
- Athenian-Shipbrokers-March 2013Dokument19 SeitenAthenian-Shipbrokers-March 2013Nguyen Le Thu HaNoch keine Bewertungen
- 100% RT Line: RT Shooting Result (By JGCS)Dokument9 Seiten100% RT Line: RT Shooting Result (By JGCS)tranvando1986Noch keine Bewertungen
- Baicells IntroductionDokument31 SeitenBaicells IntroductionKyaw HtutNoch keine Bewertungen
- 2019-06 Monthly Housing Market OutlookDokument39 Seiten2019-06 Monthly Housing Market OutlookC.A.R. Research & EconomicsNoch keine Bewertungen
- Ambit Good and Clean India PMSDokument22 SeitenAmbit Good and Clean India PMSAnkurNoch keine Bewertungen
- Grantt Chart Template 04Dokument6 SeitenGrantt Chart Template 04Vijay ReddyNoch keine Bewertungen
- 2019-05 Monthly Housing Market OutlookDokument35 Seiten2019-05 Monthly Housing Market OutlookC.A.R. Research & EconomicsNoch keine Bewertungen
- 2017 08 16 - ID Finance Presentation PDFDokument12 Seiten2017 08 16 - ID Finance Presentation PDFJuan Daniel Garcia VeigaNoch keine Bewertungen
- 100% RT Line: RT Shooting Result (By JGCS)Dokument8 Seiten100% RT Line: RT Shooting Result (By JGCS)tranvando1986Noch keine Bewertungen
- Libro 4Dokument2 SeitenLibro 4Mayra CastroNoch keine Bewertungen
- Project TrackingDokument16 SeitenProject TrackingAnonymous EEGMVukXdBNoch keine Bewertungen
- November 2019 Monthly Housing Market OutlookDokument47 SeitenNovember 2019 Monthly Housing Market OutlookC.A.R. Research & EconomicsNoch keine Bewertungen
- Knowledge Representation and Reasoning: University "Politehnica" of Bucharest Department of Computer ScienceDokument23 SeitenKnowledge Representation and Reasoning: University "Politehnica" of Bucharest Department of Computer ScienceZaracirNoch keine Bewertungen
- IDIR Imane ThesisDokument82 SeitenIDIR Imane ThesiszaroureNoch keine Bewertungen
- Real Time Human Activity Recognition On Smartphones Using LSTM NetworksDokument6 SeitenReal Time Human Activity Recognition On Smartphones Using LSTM NetworksAditi DoraNoch keine Bewertungen
- IV Year CSE 2022 23Dokument53 SeitenIV Year CSE 2022 23811 Anusha RaibagiNoch keine Bewertungen
- Tutorial Instruction Answer The Following QuestionsDokument3 SeitenTutorial Instruction Answer The Following QuestionsKatoon GhodeNoch keine Bewertungen
- Parallels ComputingDokument871 SeitenParallels Computingagustin carstens100% (1)
- Parcial Sem 8 InglesDokument5 SeitenParcial Sem 8 InglesDIANA50% (2)
- Artificial Intelligence and Machine Learning in Satellite CommunicationDokument13 SeitenArtificial Intelligence and Machine Learning in Satellite CommunicationSalahuddinKhanNoch keine Bewertungen
- What Is The Digital EconomyDokument15 SeitenWhat Is The Digital EconomyHamza Tahir GhauriNoch keine Bewertungen
- 06 Cse PDFDokument165 Seiten06 Cse PDFClaudio Alberto Manquirre50% (2)
- Azure Cognitive ServicesDokument340 SeitenAzure Cognitive Servicespepsiholic dreamNoch keine Bewertungen
- ETHICS Long QuizDokument7 SeitenETHICS Long QuizMiguel KabigtingNoch keine Bewertungen
- Fuzzy C-Means Algorithm For Medical Image Segmentation: M.C.Jobin Christ Dr.R.M.S.ParvathiDokument4 SeitenFuzzy C-Means Algorithm For Medical Image Segmentation: M.C.Jobin Christ Dr.R.M.S.ParvathiAsmi SinhaNoch keine Bewertungen
- Incorporating AI-Driven Strategies in DevSecOps For Robust Cloud SecurityDokument7 SeitenIncorporating AI-Driven Strategies in DevSecOps For Robust Cloud SecurityInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Appendix Survey QuestionnaireDokument2 SeitenAppendix Survey QuestionnaireManish OjhaNoch keine Bewertungen
- Guide GPDokument35 SeitenGuide GPStick NoobNoch keine Bewertungen
- Artificial Intelligence (CSC 477)Dokument116 SeitenArtificial Intelligence (CSC 477)abu aduNoch keine Bewertungen
- Electrical Design A Problem For Artificial Intelligence Research Gerald Jay SueeaanDokument7 SeitenElectrical Design A Problem For Artificial Intelligence Research Gerald Jay SueeaanAdityaBeheraNoch keine Bewertungen
- Week 9, Day 1Dokument16 SeitenWeek 9, Day 1Goharik AdamyanNoch keine Bewertungen
- 745 NullDokument5 Seiten745 Nullhoney arguellesNoch keine Bewertungen
- Next Word Prediction Using Machine Learning Techniques: Cybersecurity November 2022Dokument12 SeitenNext Word Prediction Using Machine Learning Techniques: Cybersecurity November 2022Ahmed IndrisNoch keine Bewertungen
- Keeping It Real - Using Real-World Problems To Teach AI To Diverse AudiencesDokument14 SeitenKeeping It Real - Using Real-World Problems To Teach AI To Diverse AudiencesjaneNoch keine Bewertungen
- Evaluating Models Based On Explainable Ai: Keywords: Gradcam, Explainability, Xai, Artificial IntelligenceDokument22 SeitenEvaluating Models Based On Explainable Ai: Keywords: Gradcam, Explainability, Xai, Artificial IntelligenceSports Science and Analytics CoENoch keine Bewertungen
- IIT Guwahati ProcessDokument21 SeitenIIT Guwahati Processprashant0609Noch keine Bewertungen
- Benefits and Costs of The Database To Its StakeholdersDokument5 SeitenBenefits and Costs of The Database To Its Stakeholdersbhuvnesh khatriNoch keine Bewertungen
- Rohan Thesis PresentationDokument13 SeitenRohan Thesis Presentationfabian plettNoch keine Bewertungen
- IBM Brands Overview 2023Dokument45 SeitenIBM Brands Overview 2023Fazdlan FazNoch keine Bewertungen