Das könnte Ihnen auch gefallen
- Econometrics Cheat Sheet Stock and WatsonDokument2 SeitenEconometrics Cheat Sheet Stock and Watsonpeathepeanut100% (5)
- Advanced Macroeconomic Theory (Lecture Notes) (Guner 2006) PDFDokument205 SeitenAdvanced Macroeconomic Theory (Lecture Notes) (Guner 2006) PDFbizjim20067960100% (1)
- Econometric S Cheat SheetDokument3 SeitenEconometric S Cheat SheetVaneNoch keine Bewertungen
- Cheat Sheet EconometricsDokument4 SeitenCheat Sheet EconometricspatNoch keine Bewertungen
- Econometrics CheatDokument3 SeitenEconometrics CheatLaurence TyrrellNoch keine Bewertungen
- Harvard Economics 2020a Problem Set 4Dokument4 SeitenHarvard Economics 2020a Problem Set 4J100% (1)
- Stochastic Calculus Notes 4/5Dokument22 SeitenStochastic Calculus Notes 4/5tburiNoch keine Bewertungen
- Cheat SheetDokument1 SeiteCheat SheetahmadNoch keine Bewertungen
- Formula Sheet Econometrics PDFDokument2 SeitenFormula Sheet Econometrics PDFJustin Huynh100% (2)
- LADokument138 SeitenLAasdfdsakgqnkeffNoch keine Bewertungen
- Forrest Math148notesDokument199 SeitenForrest Math148notesphoebezzNoch keine Bewertungen
- Ec2065 2013Dokument70 SeitenEc2065 2013staticbitezNoch keine Bewertungen
- Assignment 5 Mathematical FinanceDokument3 SeitenAssignment 5 Mathematical FinanceYuengNoch keine Bewertungen
- Delegate Notes - Module 2 Risk Assessment v1 EvlreconvDokument30 SeitenDelegate Notes - Module 2 Risk Assessment v1 EvlreconvAngélica SilvaNoch keine Bewertungen
- I ' S M P S I: Nstructor S Olutions Anual Robability AND Tatistical NferenceDokument16 SeitenI ' S M P S I: Nstructor S Olutions Anual Robability AND Tatistical NferenceSamuel Alfonzo Gil BarcoNoch keine Bewertungen
- Econometrics Cheatsheet enDokument3 SeitenEconometrics Cheatsheet enRodina Muhammed100% (1)
- 4 - LM Test and HeteroskedasticityDokument13 Seiten4 - LM Test and HeteroskedasticityArsalan KhanNoch keine Bewertungen
- STAT 111 - 2019 Spring (51056)Dokument2 SeitenSTAT 111 - 2019 Spring (51056)Josh Man0% (1)
- Linear Algebra Course Pack PDFDokument872 SeitenLinear Algebra Course Pack PDFSwaggyVBros MNoch keine Bewertungen
- Essential Reading: Choice Under UncertaintyDokument28 SeitenEssential Reading: Choice Under UncertaintyDương DươngNoch keine Bewertungen
- Examp Formula SheetsDokument6 SeitenExamp Formula SheetsSanjay GhimireNoch keine Bewertungen
- Chuck Wilson Homogeneous FunctionsDokument7 SeitenChuck Wilson Homogeneous FunctionsdelustrousNoch keine Bewertungen
- Time Series Analysis With MATLAB and Econometrics ToolboxDokument2 SeitenTime Series Analysis With MATLAB and Econometrics ToolboxKamel RamtanNoch keine Bewertungen
- EC400 Lecture NotesDokument43 SeitenEC400 Lecture Notesscribdqwerty19Noch keine Bewertungen
- Sheetcheat EconometricsDokument1 SeiteSheetcheat EconometricsromainNoch keine Bewertungen
- Week 11 General Equilibrium (Jehle and Reny, Ch.5) : Serçin AhinDokument26 SeitenWeek 11 General Equilibrium (Jehle and Reny, Ch.5) : Serçin AhinBijita BiswasNoch keine Bewertungen
- Solutions Advanced Econometrics 1 Midterm 2013Dokument3 SeitenSolutions Advanced Econometrics 1 Midterm 2013Esmée WinnubstNoch keine Bewertungen
- FormulaDokument7 SeitenFormulaMàddìRèxxShìrshírNoch keine Bewertungen
- Non-Life Insurance Mathematics (Sumary)Dokument99 SeitenNon-Life Insurance Mathematics (Sumary)chechoNoch keine Bewertungen
- Time Series With EViews PDFDokument37 SeitenTime Series With EViews PDFashishankurNoch keine Bewertungen
- Econometrics Ch6 ApplicationsDokument49 SeitenEconometrics Ch6 ApplicationsMihaela SirițanuNoch keine Bewertungen
- MA2104 Notes PDFDokument35 SeitenMA2104 Notes PDFRobert FisherNoch keine Bewertungen
- Stochastic CalulusDokument60 SeitenStochastic CalulusDevyash JhaNoch keine Bewertungen
- Theory of Interest Kellison Solutions Chapter 011Dokument15 SeitenTheory of Interest Kellison Solutions Chapter 011Virna Cristina Lazo100% (1)
- Advanced MicroeconomicDokument70 SeitenAdvanced Microeconomicalbi_12291214100% (1)
- Exam LTAM: You Have What It Takes To PassDokument12 SeitenExam LTAM: You Have What It Takes To Passderianfg100% (1)
- Chapter 9Dokument15 SeitenChapter 9Fanny Sylvia C.Noch keine Bewertungen
- Cheat Sheet PDFDokument6 SeitenCheat Sheet PDFSonaal GuptaNoch keine Bewertungen
- MFE FormulasDokument7 SeitenMFE FormulasahpohyNoch keine Bewertungen
- Ch2 SlidesDokument80 SeitenCh2 SlidesYiLinLiNoch keine Bewertungen
- Regression Modelling With Actuarial and Financial Applications - Key NotesDokument3 SeitenRegression Modelling With Actuarial and Financial Applications - Key NotesMitchell NathanielNoch keine Bewertungen
- Lecture 5Dokument39 SeitenLecture 5Tiffany TsangNoch keine Bewertungen
- MWG Microeconomic Theory NotesDokument102 SeitenMWG Microeconomic Theory Notes胡卉然Noch keine Bewertungen
- Time Series Analysis Using e ViewsDokument131 SeitenTime Series Analysis Using e ViewsNabeel Mahdi Aljanabi100% (1)
- Cheat SHeet ECON 334Dokument2 SeitenCheat SHeet ECON 334AbhishekMaranNoch keine Bewertungen
- Lecture 10: F - Tests, ANOVA and R 1 Anova: Reg Reg ResDokument5 SeitenLecture 10: F - Tests, ANOVA and R 1 Anova: Reg Reg ResvishakhaNoch keine Bewertungen
- Lecture 2Dokument17 SeitenLecture 2李姿瑩Noch keine Bewertungen
- Generalised Linear Models and Bayesian StatisticsDokument35 SeitenGeneralised Linear Models and Bayesian StatisticsClare WalkerNoch keine Bewertungen
- Regression in Data MiningDokument15 SeitenRegression in Data MiningpoonamNoch keine Bewertungen
- Handouts CH 3 (Gujarati)Dokument5 SeitenHandouts CH 3 (Gujarati)Atiq ur Rehman QamarNoch keine Bewertungen
- MIT14 382S17 Lec7Dokument25 SeitenMIT14 382S17 Lec7jarod_kyleNoch keine Bewertungen
- Emet2007 NotesDokument6 SeitenEmet2007 NoteskowletNoch keine Bewertungen
- Econometrics (EM2008) Specification Error in The The K-Variable ModelDokument31 SeitenEconometrics (EM2008) Specification Error in The The K-Variable ModelSelMarie Nutelliina GomezNoch keine Bewertungen
- (2022-2-GEC-ê Ë ) LN 2 - Two Variable Regression ModelDokument13 Seiten(2022-2-GEC-ê Ë ) LN 2 - Two Variable Regression Model한창현Noch keine Bewertungen
- SST307 CompleteDokument72 SeitenSST307 Completebranmondi8676Noch keine Bewertungen
- Ch. 1 - EndogeneityDokument18 SeitenCh. 1 - EndogeneityVolkan VeliNoch keine Bewertungen
- RegressionDokument15 SeitenRegressionhamdoniNoch keine Bewertungen
- Bifurcation Theory: 13.1 Bifurcation From A Steady SolutionDokument13 SeitenBifurcation Theory: 13.1 Bifurcation From A Steady Solutionpriya0978Noch keine Bewertungen
- Quizlet PDFDokument2 SeitenQuizlet PDFgulzira3amirovnaNoch keine Bewertungen
- Ssss PDFDokument50 SeitenSsss PDFbitew yirgaNoch keine Bewertungen
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Von EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Noch keine Bewertungen
- Cosmology in (2 + 1) -Dimensions, Cyclic Models, and Deformations of M2,1. (AM-121), Volume 121Von EverandCosmology in (2 + 1) -Dimensions, Cyclic Models, and Deformations of M2,1. (AM-121), Volume 121Noch keine Bewertungen
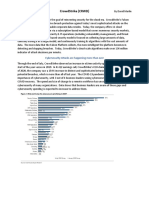
- Crowdstrike (CRWD) : Cybersecurity Attacks Are Happening More Than EverDokument6 SeitenCrowdstrike (CRWD) : Cybersecurity Attacks Are Happening More Than EverfabbeNoch keine Bewertungen
- Snap - Path To $100 Billion Underway, Upgrading To Buy (NYSE - SNAP) - Seeking AlphaDokument22 SeitenSnap - Path To $100 Billion Underway, Upgrading To Buy (NYSE - SNAP) - Seeking AlphafabbeNoch keine Bewertungen
- EBay - Valuation Attractive, But Growth Concerns Remain (NASDAQ - EBAY) - Seeking AlphaDokument14 SeitenEBay - Valuation Attractive, But Growth Concerns Remain (NASDAQ - EBAY) - Seeking AlphafabbeNoch keine Bewertungen
- Steel City Capital - EBay Inc. (NASDAQ - EBAY) - Seeking AlphaDokument6 SeitenSteel City Capital - EBay Inc. (NASDAQ - EBAY) - Seeking AlphafabbeNoch keine Bewertungen
- LiUInnovation NABC ENGDokument1 SeiteLiUInnovation NABC ENGfabbeNoch keine Bewertungen
- Econometric Theory: Module - IiDokument8 SeitenEconometric Theory: Module - IiVishnu VenugopalNoch keine Bewertungen
- HeteroskedasticityDokument30 SeitenHeteroskedasticityallswellNoch keine Bewertungen
- Operation Research Assignment 1Dokument7 SeitenOperation Research Assignment 1Vibhor JainNoch keine Bewertungen
- Quantitative Methods 1Dokument15 SeitenQuantitative Methods 1john goodpastureNoch keine Bewertungen
- ExampleDokument3 SeitenExampleWaelBazziNoch keine Bewertungen
- CS 2032 - Data Warehousing and Data Mining PDFDokument3 SeitenCS 2032 - Data Warehousing and Data Mining PDFvelkarthi92Noch keine Bewertungen
- Tests of Hypothesis: Lesson 2: Steps in Hypothesis TestingDokument28 SeitenTests of Hypothesis: Lesson 2: Steps in Hypothesis TestingNimrodBanawis0% (1)
- Stevenson 14e Chap005sDokument30 SeitenStevenson 14e Chap005sCheskaNoch keine Bewertungen
- Statistics Mcqs - Estimation Part 3: For Solved Question Bank Visit and For Free Video Lectures VisitDokument7 SeitenStatistics Mcqs - Estimation Part 3: For Solved Question Bank Visit and For Free Video Lectures VisitAbdur RazzaqeNoch keine Bewertungen
- M-I-2.Time Value of MoneyDokument26 SeitenM-I-2.Time Value of Moneymonalisha mishraNoch keine Bewertungen
- Repartit Ia Discret A Uniform A Repartit Ia Binomial A: Curs 10Dokument2 SeitenRepartit Ia Discret A Uniform A Repartit Ia Binomial A: Curs 10CodrutaNoch keine Bewertungen
- Uji Hipotesis Rata-Rata 2 PopulasiDokument4 SeitenUji Hipotesis Rata-Rata 2 PopulasitestingNoch keine Bewertungen
- Template Critical AppraisalDokument9 SeitenTemplate Critical AppraisalFarhana AmaliyahNoch keine Bewertungen
- 3 Decision Making Under UncertaintyDokument53 Seiten3 Decision Making Under UncertaintyMohammad Raihanul HasanNoch keine Bewertungen
- Purchase Incidence:: Purchase Incidence Purchase Timing Brand Choice Integrated Models of Incidence, Timing and ChoiceDokument5 SeitenPurchase Incidence:: Purchase Incidence Purchase Timing Brand Choice Integrated Models of Incidence, Timing and ChoiceVishal TomarNoch keine Bewertungen
- Statistics For Business and Economics (13e) : John LoucksDokument48 SeitenStatistics For Business and Economics (13e) : John LoucksMary Mae Arnado100% (1)
- Using Gretl For POE4Dokument501 SeitenUsing Gretl For POE4sanjitaNoch keine Bewertungen
- Q2 Module 5 - Data Analysis Using Statistics and Hypothesis TestingDokument9 SeitenQ2 Module 5 - Data Analysis Using Statistics and Hypothesis TestingJester Guballa de LeonNoch keine Bewertungen
- Rancangan Penelitian.09Dokument45 SeitenRancangan Penelitian.09Frendy GhaNoch keine Bewertungen
- Model Sum of Squares DF Mean Square F Sig. 1 Regression .456 4 .114 1.388 .252 Residual 3.942 48 .082 Total 4.398 52 A. Predictors: (Constant), LC, DEBT, TANG, EXT B. Dependent Variable: DPRDokument3 SeitenModel Sum of Squares DF Mean Square F Sig. 1 Regression .456 4 .114 1.388 .252 Residual 3.942 48 .082 Total 4.398 52 A. Predictors: (Constant), LC, DEBT, TANG, EXT B. Dependent Variable: DPRMuhammad AliNoch keine Bewertungen
- Option Theta ExplorationDokument5 SeitenOption Theta Explorationbloombm1Noch keine Bewertungen
- Student's T DistributionDokument3 SeitenStudent's T DistributionboNoch keine Bewertungen
- Disease Doesn't Occur in A Vacuum Disease Is Not Randomly Distributed - Epidemiology Uses Systematic Approach ToDokument44 SeitenDisease Doesn't Occur in A Vacuum Disease Is Not Randomly Distributed - Epidemiology Uses Systematic Approach Toاسامة محمد السيد رمضانNoch keine Bewertungen
- Statistics 2 For Chemical Engineering: Department of Mathematics and Computer ScienceDokument37 SeitenStatistics 2 For Chemical Engineering: Department of Mathematics and Computer ScienceKhuram MaqsoodNoch keine Bewertungen
- Critical Path MethodDokument7 SeitenCritical Path MethodQurban AliNoch keine Bewertungen
- Wasserman 1994Dokument4 SeitenWasserman 1994Pedro SilvaNoch keine Bewertungen
- 2nd 3rd Assignment 17MAT41Dokument2 Seiten2nd 3rd Assignment 17MAT41Ritwik guptaNoch keine Bewertungen
- How To Use Minitab 1 BasicsDokument28 SeitenHow To Use Minitab 1 Basicsserkan_apayNoch keine Bewertungen