Das könnte Ihnen auch gefallen
- Lec 16 - Directional StatisticsDokument44 SeitenLec 16 - Directional StatisticsAPPURV GUPTANoch keine Bewertungen
- MRUV (Recuperado Automaticamente)Dokument2 SeitenMRUV (Recuperado Automaticamente)michelroNoch keine Bewertungen
- Ibuprofen analysis in Neofen tablets by UV-Vis spectroscopyDokument1 SeiteIbuprofen analysis in Neofen tablets by UV-Vis spectroscopysaraahNoch keine Bewertungen
- ME2113-2 Torsion of Circular Shafts Lab ReportDokument6 SeitenME2113-2 Torsion of Circular Shafts Lab ReportStuart TangNoch keine Bewertungen
- CalcuDokument4 SeitenCalcumarkNoch keine Bewertungen
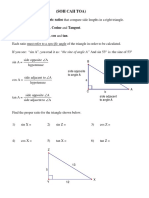
- Trigonometry TopicsDokument7 SeitenTrigonometry TopicsAsad AliNoch keine Bewertungen
- Tugas 2Dokument8 SeitenTugas 2ISRENNA RATU REZKY SUCINoch keine Bewertungen
- Bela JarDokument6 SeitenBela JarVidita ImroatusNoch keine Bewertungen
- Interaction Diagrams - ECP 203-2007 - Mohammed AtaDokument11 SeitenInteraction Diagrams - ECP 203-2007 - Mohammed Atasherif mahmoudNoch keine Bewertungen
- Graph of Temperature Against x1, Y2Dokument2 SeitenGraph of Temperature Against x1, Y2markNoch keine Bewertungen
- LAB MEC424-Slider CrankDokument7 SeitenLAB MEC424-Slider CrankAhmad Fadzlan93% (15)
- Instituto Politecnico Nacional Escuela Superior de Ingenieria Mecanica Y ElectricaDokument7 SeitenInstituto Politecnico Nacional Escuela Superior de Ingenieria Mecanica Y ElectricaLuis Fernando GonzálezNoch keine Bewertungen
- MATRICESDokument4 SeitenMATRICESberenice hernandezNoch keine Bewertungen
- CSE29357 Tut4 - Horizontal Alignment 2Dokument5 SeitenCSE29357 Tut4 - Horizontal Alignment 2HL KNoch keine Bewertungen
- Use Upwind Scheme and Btain Sol. For Three Time StepsDokument8 SeitenUse Upwind Scheme and Btain Sol. For Three Time StepskajalNoch keine Bewertungen
- Grafico Practica 4Dokument2 SeitenGrafico Practica 4alexandracuero20Noch keine Bewertungen
- Equation Solving ExamplesDokument10 SeitenEquation Solving Examplesalif08042012Noch keine Bewertungen
- Equation Solving ExamplesDokument10 SeitenEquation Solving Examplesalif08042012Noch keine Bewertungen
- Moment Influence Line ReportDokument13 SeitenMoment Influence Line Reporthaziq khairudin33% (3)
- Data Pesawat 1Dokument3 SeitenData Pesawat 1Irma RohmatillahNoch keine Bewertungen
- Analysis of SDOF Systems: Numerical MethodsDokument22 SeitenAnalysis of SDOF Systems: Numerical MethodsFernanda LagoNoch keine Bewertungen
- Free Vibration Analysis of Undamped and Damped StructuresDokument12 SeitenFree Vibration Analysis of Undamped and Damped StructuresTommy LapudoohNoch keine Bewertungen
- Trabajo FinalDokument420 SeitenTrabajo FinalvickyNoch keine Bewertungen
- Maths Theoretical DistributionDokument2 SeitenMaths Theoretical DistributionAmirdavarshiniNoch keine Bewertungen
- LABORATORIODokument2 SeitenLABORATORIOAnonymous EhlFEGBNoch keine Bewertungen
- Cartografie: Lucrarea 3Dokument4 SeitenCartografie: Lucrarea 3sadxNoch keine Bewertungen
- Margules Uniquac2Dokument12 SeitenMargules Uniquac2Tias Faizatul MunirohNoch keine Bewertungen
- CIVL335 SolutionsManualChapter 7Dokument27 SeitenCIVL335 SolutionsManualChapter 7ghanmaNoch keine Bewertungen
- Diketahui: AB XAB AX AC AB BAC AB ACDokument24 SeitenDiketahui: AB XAB AX AC AB BAC AB ACAti RahayuNoch keine Bewertungen
- Z Tables PDFDokument4 SeitenZ Tables PDFMersadČoboNoch keine Bewertungen
- Experimental CalculationsDokument5 SeitenExperimental CalculationsmomenNoch keine Bewertungen
- Snell's Law Experiment: Lab Report 1 Part 1: No. 2Dokument8 SeitenSnell's Law Experiment: Lab Report 1 Part 1: No. 2AINA TATYANANoch keine Bewertungen
- Finding Best Solar Panel Angle for Ocean Data BuoyDokument11 SeitenFinding Best Solar Panel Angle for Ocean Data BuoyJosh GirgisNoch keine Bewertungen
- Trapezoidal (Equally Spaced) and Simpsons RuleDokument6 SeitenTrapezoidal (Equally Spaced) and Simpsons RuleRushane MirandaNoch keine Bewertungen
- 3D Structural Analysis Using Stiffness MethodDokument10 Seiten3D Structural Analysis Using Stiffness MethodCarlos Prada TorresNoch keine Bewertungen
- Tugas: Menentukan Nilai B Dan K Hasil PercobaanDokument2 SeitenTugas: Menentukan Nilai B Dan K Hasil PercobaanMuhammad IkramullahNoch keine Bewertungen
- Coord Angle and BearingDokument17 SeitenCoord Angle and BearingyuritabascoNoch keine Bewertungen
- Valores y Vectores CaracterísticosDokument27 SeitenValores y Vectores CaracterísticosAnderson sanchezNoch keine Bewertungen
- ParabolaDokument2 SeitenParabolaBriyith MondragonNoch keine Bewertungen
- Perubahan Bobot: Perlakuan Ulangan Awal Akhir Selisih SD (%)Dokument9 SeitenPerubahan Bobot: Perlakuan Ulangan Awal Akhir Selisih SD (%)efendiNoch keine Bewertungen
- HW2 Solution Batuhan Aydogan 2261956Dokument10 SeitenHW2 Solution Batuhan Aydogan 2261956Batuhan AydoganNoch keine Bewertungen
- 1-Bisection Method: Equation Number One (3 X+sin (X) - Exp (X) )Dokument4 Seiten1-Bisection Method: Equation Number One (3 X+sin (X) - Exp (X) )seraj sersawiNoch keine Bewertungen
- RF ImpedanceDokument7 SeitenRF ImpedancesrybsantosNoch keine Bewertungen
- Set-I AnswerDokument9 SeitenSet-I Answershivansh gandhiNoch keine Bewertungen
- Sistema: Metanol (1) / Acetonidrilo (2) Modelo UNIFAC: Ganma 1Dokument5 SeitenSistema: Metanol (1) / Acetonidrilo (2) Modelo UNIFAC: Ganma 1Carlos Coronado LezmaNoch keine Bewertungen
- Homework 1 MDokument4 SeitenHomework 1 Mt8ktwrcvj4Noch keine Bewertungen
- Formulário: C' ' .Tan 'Dokument7 SeitenFormulário: C' ' .Tan 'LUISATEIXNoch keine Bewertungen
- Hubungan Porositas Dan K: Nama: Dwisthi Satiti NIM: 113160126 Kelas: E (Metode Numerik)Dokument2 SeitenHubungan Porositas Dan K: Nama: Dwisthi Satiti NIM: 113160126 Kelas: E (Metode Numerik)Dwisthi SatitiNoch keine Bewertungen
- Inclined Bar Element AnalysisDokument17 SeitenInclined Bar Element AnalysisMiguel Ángel AltamiranoNoch keine Bewertungen
- Interaction Diagrams - ECP 203-2007 - Mohammed AtaDokument9 SeitenInteraction Diagrams - ECP 203-2007 - Mohammed AtaSantiago GutierrezNoch keine Bewertungen
- Truss (HW)Dokument19 SeitenTruss (HW)Anonymous FkXPJWvpuNoch keine Bewertungen
- Freundlich y LangmuirDokument9 SeitenFreundlich y LangmuirNora EdthNoch keine Bewertungen
- Tarea 2Dokument11 SeitenTarea 2Carlos RodriguezNoch keine Bewertungen
- Andat Perc. 5Dokument2 SeitenAndat Perc. 520 011 Sarah hapritasya LauendeNoch keine Bewertungen
- Confidence Ellipse For Bivariate Normal Data: LPGA Driving Distance and Fairway Percent - 2008 SeasonDokument8 SeitenConfidence Ellipse For Bivariate Normal Data: LPGA Driving Distance and Fairway Percent - 2008 Seasonبا قرNoch keine Bewertungen
- E. F.Dokument29 SeitenE. F.Ana HerreroNoch keine Bewertungen
- Calculating seismic forces for buildings in EgyptDokument26 SeitenCalculating seismic forces for buildings in EgyptzaidNoch keine Bewertungen
- Modul Hal 69Dokument2 SeitenModul Hal 69Ningrum WijayantiNoch keine Bewertungen
- Assignment 8 6331 PDFDokument11 SeitenAssignment 8 6331 PDFALIKNFNoch keine Bewertungen
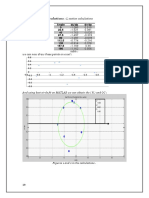
- Circular Data Analysis: NCSS Statistical SoftwareDokument28 SeitenCircular Data Analysis: NCSS Statistical SoftwareDevita MayasariNoch keine Bewertungen
- A Four Parameter Generalized Logistic Distribution PDFDokument18 SeitenA Four Parameter Generalized Logistic Distribution PDFDevita MayasariNoch keine Bewertungen
- JournalDokument19 SeitenJournalDevita MayasariNoch keine Bewertungen
- Penyuluhan Bangunan Rumah Tahan Gempa Sebagai Optimalisasi Mitigasi Gempa BumiDokument7 SeitenPenyuluhan Bangunan Rumah Tahan Gempa Sebagai Optimalisasi Mitigasi Gempa BumiYudha MarlinNoch keine Bewertungen
- Model Temporal Curah Hujan Dan Debit Sungai Citarum Berbasis ANFIS PDFDokument17 SeitenModel Temporal Curah Hujan Dan Debit Sungai Citarum Berbasis ANFIS PDFDevita MayasariNoch keine Bewertungen
- Numerical Modelling of Water Levels On Pavements Under Extreme RainfallDokument9 SeitenNumerical Modelling of Water Levels On Pavements Under Extreme RainfallDevita MayasariNoch keine Bewertungen
- An Improved Method of Extreme Value AnalysisDokument7 SeitenAn Improved Method of Extreme Value AnalysisDevita MayasariNoch keine Bewertungen
- 1829 6459 1 PBDokument10 Seiten1829 6459 1 PBmurniNoch keine Bewertungen
- Analysis of Extremes in A Changing ClimateDokument55 SeitenAnalysis of Extremes in A Changing ClimateA S VermaNoch keine Bewertungen
- Hosking 81Dokument13 SeitenHosking 81Devita MayasariNoch keine Bewertungen
- Penyuluhan Bangunan Rumah Tahan Gempa Sebagai Optimalisasi Mitigasi Gempa BumiDokument7 SeitenPenyuluhan Bangunan Rumah Tahan Gempa Sebagai Optimalisasi Mitigasi Gempa BumiYudha MarlinNoch keine Bewertungen
- Pemilihan Metode Intensitas Hujan Yang Sesuai Dengan Karakteristik Stasiun PekanbaruDokument12 SeitenPemilihan Metode Intensitas Hujan Yang Sesuai Dengan Karakteristik Stasiun PekanbaruDevita MayasariNoch keine Bewertungen
- A General Numerical Model For Surface Waves Generated by Granular Material IntrudingDokument46 SeitenA General Numerical Model For Surface Waves Generated by Granular Material IntrudingDevita MayasariNoch keine Bewertungen
- Pemilihan Metode Intensitas Hujan Yang Sesuai Dengan Karakteristik Stasiun PekanbaruDokument12 SeitenPemilihan Metode Intensitas Hujan Yang Sesuai Dengan Karakteristik Stasiun PekanbaruDevita MayasariNoch keine Bewertungen
- Journal of Hydrology: J.R. Thompson, A.J. Green, D.G. KingstonDokument21 SeitenJournal of Hydrology: J.R. Thompson, A.J. Green, D.G. KingstonDevita MayasariNoch keine Bewertungen
- Extreme Rainfall For Africa and Other Developing AreasDokument10 SeitenExtreme Rainfall For Africa and Other Developing AreasDevita MayasariNoch keine Bewertungen
- On Selection of Probability For Representing Annual Extreme Rainfall SeriesDokument10 SeitenOn Selection of Probability For Representing Annual Extreme Rainfall SeriesDevita MayasariNoch keine Bewertungen
- Fundamentals of Trigonometry in 38 CharactersDokument35 SeitenFundamentals of Trigonometry in 38 CharactersChristina Corazon GoNoch keine Bewertungen
- Bec198 2 TrigonometryDokument4 SeitenBec198 2 TrigonometryJohn Patrick DagleNoch keine Bewertungen
- Math 04Dokument2 SeitenMath 04Rodney Lemuel FortunaNoch keine Bewertungen
- Radial Gate Thrust Calculations for Kutehr HEPDokument3 SeitenRadial Gate Thrust Calculations for Kutehr HEPAkshay DuggalNoch keine Bewertungen
- Revision Question MoreDokument12 SeitenRevision Question MoreFiedDinieNoch keine Bewertungen
- 2067 SLC For 2072 Kins SchoolDokument2 Seiten2067 SLC For 2072 Kins SchoolSantosh AryalNoch keine Bewertungen
- CSEC Mathematics 2003 Specimen P2 SolutionDokument16 SeitenCSEC Mathematics 2003 Specimen P2 SolutionShaffick Mustafa AliNoch keine Bewertungen
- Chapter 6Dokument26 SeitenChapter 6Mohammad SaabNoch keine Bewertungen
- Keph 104Dokument24 SeitenKeph 104Ninad PNoch keine Bewertungen
- VTU NOTES ON BALANCING OF ROTATING MASSESDokument46 SeitenVTU NOTES ON BALANCING OF ROTATING MASSESRichard Mortimer100% (2)
- TECHNOLOGY AND LIVELIHOOD EDUCATION: AREA AND PERIMETERDokument2 SeitenTECHNOLOGY AND LIVELIHOOD EDUCATION: AREA AND PERIMETERMatoy Gab'zNoch keine Bewertungen
- Basic Mechanical Engineering: Module-I Module-IIDokument77 SeitenBasic Mechanical Engineering: Module-I Module-IIKunal AgrawalNoch keine Bewertungen
- Circumference and Area of Circles and Real-World Problems NotesDokument14 SeitenCircumference and Area of Circles and Real-World Problems Notesapi-310102170Noch keine Bewertungen
- Trigonometric Ratios and Identities ExplainedDokument12 SeitenTrigonometric Ratios and Identities ExplainedSantosh SinghNoch keine Bewertungen
- Worksheet With Answer KeyDokument8 SeitenWorksheet With Answer Keyapi-213604106Noch keine Bewertungen
- D1C C1Dokument6 SeitenD1C C1Sudhir SinghNoch keine Bewertungen
- Chapter IVDokument49 SeitenChapter IVFiraolNoch keine Bewertungen
- HWK 12Dokument24 SeitenHWK 12Arron Vetus SablanNoch keine Bewertungen
- How Many Angle Point in CubeDokument3 SeitenHow Many Angle Point in CubeTaufiqur RohmanNoch keine Bewertungen
- Tuto 78 Vol of Rev WasherDokument4 SeitenTuto 78 Vol of Rev WasherAZRI FIRDAUS이광수Noch keine Bewertungen
- Physics Chapter 10 AnswersDokument40 SeitenPhysics Chapter 10 AnswersAbovethesystem100% (14)
- Surface Area & Volume ClssDokument3 SeitenSurface Area & Volume ClssBrijesh pratap singhNoch keine Bewertungen
- General Physics 1: Learning Activity Sheets TorqueDokument66 SeitenGeneral Physics 1: Learning Activity Sheets TorqueUser IhmnidaNoch keine Bewertungen
- CHAPTER 4 - Measurement of Angles and DirectionsDokument20 SeitenCHAPTER 4 - Measurement of Angles and DirectionsRemielle Ednilao LaguismaNoch keine Bewertungen
- Chapter 12 - Surface Areas and Volumes NCERT Exemplar - Class 10Dokument30 SeitenChapter 12 - Surface Areas and Volumes NCERT Exemplar - Class 10Nitin BeniwalNoch keine Bewertungen
- Fomulas Page 1 To 29Dokument30 SeitenFomulas Page 1 To 29Khalid KhokharNoch keine Bewertungen
- Exercises On Statics and Rotational DynamicsDokument30 SeitenExercises On Statics and Rotational Dynamicselty TanNoch keine Bewertungen
- Arc Length, Linear Velocity, and Angular Velocity FormulasDokument2 SeitenArc Length, Linear Velocity, and Angular Velocity FormulasherminiNoch keine Bewertungen
- IntegrationDokument104 SeitenIntegrationPratham MalhotraNoch keine Bewertungen
- Finding the Area of a Circle FormulaDokument2 SeitenFinding the Area of a Circle FormulaRiza Pearl LlonaNoch keine Bewertungen