Das könnte Ihnen auch gefallen
- Webdynpro Interview Questions and AnswersDokument10 SeitenWebdynpro Interview Questions and AnswersNaveen KumarNoch keine Bewertungen
- Create A Simple Editable ALV GridDokument6 SeitenCreate A Simple Editable ALV GridRam PraneethNoch keine Bewertungen
- Field SymbolsDokument7 SeitenField SymbolsAndrés GómezNoch keine Bewertungen
- SAP Table RelationsDokument16 SeitenSAP Table Relationsanon_173235067Noch keine Bewertungen
- AbapDokument49 SeitenAbapgauravNoch keine Bewertungen
- Abap Hana 1Dokument3 SeitenAbap Hana 1Nagesh reddyNoch keine Bewertungen
- ABAP Data DictionaryDokument7 SeitenABAP Data DictionaryNikhil MalpeNoch keine Bewertungen
- Migrating Material Master Data Into Sap PDFDokument9 SeitenMigrating Material Master Data Into Sap PDFsksk1911Noch keine Bewertungen
- ABAPDokument11 SeitenABAPdilipkumarrajuNoch keine Bewertungen
- Varaint ConfigurationDokument12 SeitenVaraint ConfigurationSivaVasireddyNoch keine Bewertungen
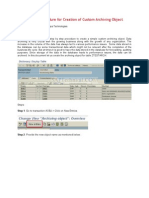
- Sap Data Archive StepDokument7 SeitenSap Data Archive Stepnaren6299Noch keine Bewertungen
- Manage Supply Chain Event Management mySAP SCM 4.1Dokument19 SeitenManage Supply Chain Event Management mySAP SCM 4.1naveentondurNoch keine Bewertungen
- Sap Apo DP NutsellDokument53 SeitenSap Apo DP NutsellSundaran NairNoch keine Bewertungen
- Sappress Abap Objects ApplicationDokument56 SeitenSappress Abap Objects Applicationswap0lovein0% (1)
- SAP Query IntroductionDokument7 SeitenSAP Query Introductionkashram2001Noch keine Bewertungen
- TCODESDokument47 SeitenTCODESgangusandeepkumarNoch keine Bewertungen
- Bapi Step by Step ExampleDokument31 SeitenBapi Step by Step ExampleSunil Dutt SharmaNoch keine Bewertungen
- Trucos & Técnicas AvanzadasDokument66 SeitenTrucos & Técnicas AvanzadasSergio LopezNoch keine Bewertungen
- CDS ExtensionDokument22 SeitenCDS ExtensionRaghubir SinghNoch keine Bewertungen
- Training UI5Dokument39 SeitenTraining UI5Yoppie AriesthioNoch keine Bewertungen
- Abap Course ContentDokument12 SeitenAbap Course ContentbandistechnologyNoch keine Bewertungen
- ALV and Fuzzy SearchDokument4 SeitenALV and Fuzzy SearchKaran ChopraNoch keine Bewertungen
- SapDokument363 SeitenSapYugandhar BabuNoch keine Bewertungen
- SAP ABAP - Sample Report Program On WRITE, COLOR, HOTSPOT KeywordsDokument37 SeitenSAP ABAP - Sample Report Program On WRITE, COLOR, HOTSPOT Keywordsapraju403Noch keine Bewertungen
- SAP ABAP - MM & SD Module Introduction (Technical Prospective)Dokument3 SeitenSAP ABAP - MM & SD Module Introduction (Technical Prospective)Anonymous zzw4hoFvHNNoch keine Bewertungen
- Extending Extending - SRM - Web - Dynpro - ViewSRM Web Dynpro ViewDokument19 SeitenExtending Extending - SRM - Web - Dynpro - ViewSRM Web Dynpro Viewmostafaelbarbary100% (3)
- SAP Query - User Group Creation: SQ03Dokument21 SeitenSAP Query - User Group Creation: SQ03Rahul pawadeNoch keine Bewertungen
- Difference Between BDC and BAPIDokument1 SeiteDifference Between BDC and BAPIbeema1977100% (1)
- SAP EWM Agenda NewDokument4 SeitenSAP EWM Agenda NewShashidhar KNoch keine Bewertungen
- Sap SD Total Study MaterialDokument66 SeitenSap SD Total Study MaterialrameshprustyNoch keine Bewertungen
- An SAP Consultant - ABAP - Infotype Record Creation - HR - INFOTYPE - OPERATIONDokument2 SeitenAn SAP Consultant - ABAP - Infotype Record Creation - HR - INFOTYPE - OPERATIONarunNoch keine Bewertungen
- Creating Selection Profiles For The Planning Book Use: Transaction Code SAP SCM MenuDokument2 SeitenCreating Selection Profiles For The Planning Book Use: Transaction Code SAP SCM MenuddukemNoch keine Bewertungen
- Sap Master Data in Materials ManagementDokument13 SeitenSap Master Data in Materials Managementedmondo77Noch keine Bewertungen
- IdocDokument137 SeitenIdocRajesh KumarNoch keine Bewertungen
- Steps To Create A Simple LSMW Using Batch Input RecordingDokument18 SeitenSteps To Create A Simple LSMW Using Batch Input RecordingSharad TiwariNoch keine Bewertungen
- Batch MGMTDokument2 SeitenBatch MGMTapi-3718223Noch keine Bewertungen
- Sample CV For SAP ABAP ConsultantDokument3 SeitenSample CV For SAP ABAP ConsultantSahil MalhotraNoch keine Bewertungen
- Ricef Sap AbapDokument18 SeitenRicef Sap AbapAdaikalam Alexander RayappaNoch keine Bewertungen
- BDC Call Transaction MethodDokument9 SeitenBDC Call Transaction MethodAnonymous 0wXXmp1Noch keine Bewertungen
- BADI ExampleDokument4 SeitenBADI ExampleSaurabh GuptaNoch keine Bewertungen
- Debugger Runtime Analysis Coverage Analyzer Runtime Monitor Memory InspectorDokument101 SeitenDebugger Runtime Analysis Coverage Analyzer Runtime Monitor Memory InspectorUmasankar_ReddyNoch keine Bewertungen
- Understanding Sap Work FlowsDokument15 SeitenUnderstanding Sap Work FlowsAnil KumarNoch keine Bewertungen
- Beginner'S Guide To Ale and Idocs - A Step-By-Step ApproachDokument9 SeitenBeginner'S Guide To Ale and Idocs - A Step-By-Step ApproachLokamNoch keine Bewertungen
- Vertical Display of TextDokument11 SeitenVertical Display of TextSukanta BrahmaNoch keine Bewertungen
- RAP Unit TestDokument5 SeitenRAP Unit Testnamratha sureshNoch keine Bewertungen
- Adobe Forms - OverviewDokument10 SeitenAdobe Forms - OverviewdaroorisrinivasuNoch keine Bewertungen
- Inbound Email Configuration For Offline ApprovalsDokument10 SeitenInbound Email Configuration For Offline Approvalssarin.kane8423100% (1)
- BADIDokument8 SeitenBADIJosif LalNoch keine Bewertungen
- Sapui5 Tutorial With Webide. Part Ix. Alternative To Omodel - SetsizelimitDokument16 SeitenSapui5 Tutorial With Webide. Part Ix. Alternative To Omodel - Setsizelimitnatus consultoriaNoch keine Bewertungen
- Production Planning-Process Industries: Training On in SAP R/3Dokument25 SeitenProduction Planning-Process Industries: Training On in SAP R/3Vinod NagarahalliNoch keine Bewertungen
- SAP Interactive Forms by AdobeDokument3 SeitenSAP Interactive Forms by AdobeKishore ReddyNoch keine Bewertungen
- Sizing Guide For SAP MII 15.4Dokument20 SeitenSizing Guide For SAP MII 15.4RahulNoch keine Bewertungen
- ABAP - Row Level Locking of Database TableDokument9 SeitenABAP - Row Level Locking of Database TableKIRANNoch keine Bewertungen
- Implementing Integrated Business Planning: A Guide Exemplified With Process Context and SAP IBP Use CasesVon EverandImplementing Integrated Business Planning: A Guide Exemplified With Process Context and SAP IBP Use CasesNoch keine Bewertungen
- Two-Tier ERP Strategy A Clear and Concise ReferenceVon EverandTwo-Tier ERP Strategy A Clear and Concise ReferenceNoch keine Bewertungen
- Custom Fiori Applications in SAP HANA: Design, Develop, and Deploy Fiori Applications for the EnterpriseVon EverandCustom Fiori Applications in SAP HANA: Design, Develop, and Deploy Fiori Applications for the EnterpriseNoch keine Bewertungen
- BW CLassDokument2 SeitenBW CLassSai BodduNoch keine Bewertungen
- Select Case When Then When Then When Then Else End From OrderbyDokument21 SeitenSelect Case When Then When Then When Then Else End From OrderbySai BodduNoch keine Bewertungen
- Complete Slides For Module 10 PDFDokument35 SeitenComplete Slides For Module 10 PDFhiryanizamNoch keine Bewertungen
- Source SQL or Hana or BW Ms Acess DB (Motors)Dokument2 SeitenSource SQL or Hana or BW Ms Acess DB (Motors)Sai BodduNoch keine Bewertungen
- Validation INPUTDokument1 SeiteValidation INPUTSai BodduNoch keine Bewertungen
- Notes HereDokument1 SeiteNotes HereSai BodduNoch keine Bewertungen
- How To Model A Gateway Service Based On CDS View For ABAP Using SADLDokument3 SeitenHow To Model A Gateway Service Based On CDS View For ABAP Using SADLSai BodduNoch keine Bewertungen
- Consonant Tongue Twisters Exercise Twisters With "T" and "TH"Dokument9 SeitenConsonant Tongue Twisters Exercise Twisters With "T" and "TH"Sai BodduNoch keine Bewertungen
- One Syllable: Stressed: PAY Drive GoodDokument4 SeitenOne Syllable: Stressed: PAY Drive GoodboddulNoch keine Bewertungen
- Vocal Cord Strengthening Exercises: X26029 (05/11) ©AHC VoiceDokument1 SeiteVocal Cord Strengthening Exercises: X26029 (05/11) ©AHC VoiceSai BodduNoch keine Bewertungen
- Consonant Tongue Twisters Exercise Twisters With "T" and "TH"Dokument9 SeitenConsonant Tongue Twisters Exercise Twisters With "T" and "TH"Sai BodduNoch keine Bewertungen
- List of Suffixes and Their Influence On Word Stress: Suffix - Ade - Aire - Ee - Eer - Ese - Ette - Oo - Que - Sce - OonDokument4 SeitenList of Suffixes and Their Influence On Word Stress: Suffix - Ade - Aire - Ee - Eer - Ese - Ette - Oo - Que - Sce - OongaladrielinNoch keine Bewertungen
- Phonics Rules and Spelling RulesDokument6 SeitenPhonics Rules and Spelling RulesZakir UllahNoch keine Bewertungen
- Deep VoiceDokument1 SeiteDeep VoiceSai BodduNoch keine Bewertungen
- Articulation Exercises (AKA - Tongue Twisters)Dokument52 SeitenArticulation Exercises (AKA - Tongue Twisters)Sai BodduNoch keine Bewertungen
- AnteDokument1 SeiteAnteRoshan DalanjaNoch keine Bewertungen
- AnteDokument1 SeiteAnteRoshan DalanjaNoch keine Bewertungen
- Voice Projection ExercisesDokument10 SeitenVoice Projection ExercisesSai BodduNoch keine Bewertungen
- 1617 Robertson ShariDokument10 Seiten1617 Robertson ShariSai BodduNoch keine Bewertungen
- Eng WordsDokument91 SeitenEng WordsSai Boddu100% (1)
- Soundz Tongue TwistersDokument27 SeitenSoundz Tongue TwistersSai BodduNoch keine Bewertungen
- Voice Projection ExercisesDokument10 SeitenVoice Projection ExercisesSai BodduNoch keine Bewertungen
- Soundz Tongue TwistersDokument27 SeitenSoundz Tongue TwistersSai BodduNoch keine Bewertungen
- !!!!!!!pronunciationDokument54 Seiten!!!!!!!pronunciationSai BodduNoch keine Bewertungen
- Raushanah N. Butler, MBA, MPMDokument12 SeitenRaushanah N. Butler, MBA, MPMSai BodduNoch keine Bewertungen
- 8 Unique Ways To Practice EnglDokument6 Seiten8 Unique Ways To Practice EnglSai BodduNoch keine Bewertungen
- "A Person's A Person, No Matter How Small": 10 Dr. Seuss Quotes To Frame Your Online Marketing StrategyDokument12 Seiten"A Person's A Person, No Matter How Small": 10 Dr. Seuss Quotes To Frame Your Online Marketing StrategyboddulNoch keine Bewertungen
- 22 SongsDokument14 Seiten22 SongsSai BodduNoch keine Bewertungen
- Tongue Twister, Students' Pronunciation Ability, and Learning StylesDokument20 SeitenTongue Twister, Students' Pronunciation Ability, and Learning StylesSai BodduNoch keine Bewertungen
- ABAP Chapter 3: Open SQL Internal TableDokument101 SeitenABAP Chapter 3: Open SQL Internal TableArun Varshney (MULAYAM)Noch keine Bewertungen
- SAP ABAP Interview Question - SAP Consultancy at SCDokument32 SeitenSAP ABAP Interview Question - SAP Consultancy at SCAnonymous ivLFRV100% (1)
- DS Manual 2019 20 - RVITM - AfterReviewDokument90 SeitenDS Manual 2019 20 - RVITM - AfterReviewanonymous anonymousNoch keine Bewertungen
- List of MysqlDokument67 SeitenList of MysqlMark Jan LadesmaNoch keine Bewertungen
- Acquiring Hardware RAID Configuration Data From Disks: Sebastian Carlier (Sebastian - Carlier@os3.nl) January, 2014Dokument26 SeitenAcquiring Hardware RAID Configuration Data From Disks: Sebastian Carlier (Sebastian - Carlier@os3.nl) January, 2014Shaani AliNoch keine Bewertungen
- Oracle Database 11g: SQL Fundamentals I: D49996GC11 Edition 1.1 April 2009 D59982Dokument58 SeitenOracle Database 11g: SQL Fundamentals I: D49996GC11 Edition 1.1 April 2009 D59982Christian Yache EstrellaNoch keine Bewertungen
- Multiboot UsbDokument27 SeitenMultiboot UsbJason SheffieldNoch keine Bewertungen
- Nagios Oracle CheckDokument3 SeitenNagios Oracle Checkkcchong100% (1)
- Full LDM TemplateDokument32 SeitenFull LDM TemplateMarìa Puga CastroNoch keine Bewertungen
- Indexes - Best Practices For SAP HANADokument7 SeitenIndexes - Best Practices For SAP HANAtdeazucarNoch keine Bewertungen
- Restore CommandDokument6 SeitenRestore CommandRajeshNoch keine Bewertungen
- Anh NguyenDokument4 SeitenAnh NguyenQuoc Anh NguyenNoch keine Bewertungen
- Super Retro-Cade V1.1 00README1STDokument3 SeitenSuper Retro-Cade V1.1 00README1STjwashleyNoch keine Bewertungen
- Disks and Cloud StorageDokument12 SeitenDisks and Cloud StoragePradeepKumarMandavaNoch keine Bewertungen
- Oracle® Fusion Middleware: Installing and Configuring Oracle Goldengate For Db2 LuwDokument54 SeitenOracle® Fusion Middleware: Installing and Configuring Oracle Goldengate For Db2 Luwpush5Noch keine Bewertungen
- Etl Tools PDFDokument2 SeitenEtl Tools PDFJessicaNoch keine Bewertungen
- DATOMDokument2 SeitenDATOMsri100% (1)
- My NotesDokument2 SeitenMy NotesMohamed MuradNoch keine Bewertungen
- Mysql WorkshopDokument197 SeitenMysql WorkshopNaser NaseerNoch keine Bewertungen
- Linux Fundamentals: Chapter 3: The Command LineDokument126 SeitenLinux Fundamentals: Chapter 3: The Command Linedyake04Noch keine Bewertungen
- SQL NotesDokument85 SeitenSQL NotesAbhishek Kumar SinghNoch keine Bewertungen
- 51 - SRVCTL & CRSCTL CommandsDokument3 Seiten51 - SRVCTL & CRSCTL CommandsThirumal ReddyNoch keine Bewertungen
- CREATE TABLE "Table - Name" ("Column 1" "Data - Type - For - Column - 1", "Column 2" "Data - Type - For - Column - 2", ... )Dokument14 SeitenCREATE TABLE "Table - Name" ("Column 1" "Data - Type - For - Column - 1", "Column 2" "Data - Type - For - Column - 2", ... )vinay dahiya84100% (1)
- Bangladesh Census of Population 1974 Bulletin 1 Provisional ResultsDokument81 SeitenBangladesh Census of Population 1974 Bulletin 1 Provisional ResultsAlamgir HossenNoch keine Bewertungen
- Obia 796 InstallationDokument76 SeitenObia 796 Installationshahed3052100% (1)
- Smart Data Cloud Security AllianceDokument49 SeitenSmart Data Cloud Security AlliancefewdiscNoch keine Bewertungen
- 408Dokument32 Seiten408Ashwin RamankuttyNoch keine Bewertungen
- Data Stage Scenarios: Scenario1. Cummilative SumDokument13 SeitenData Stage Scenarios: Scenario1. Cummilative Sumabreddy2003Noch keine Bewertungen
- Address With Error Not UploadedDokument43 SeitenAddress With Error Not UploadedFaizan KhalidNoch keine Bewertungen
- CentOS 7 InstallationDokument6 SeitenCentOS 7 InstallationShivaraj P PNoch keine Bewertungen
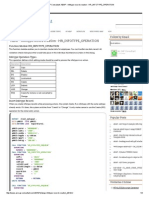
- Custom TopDokument4 SeitenCustom TopmaleemNoch keine Bewertungen