Das könnte Ihnen auch gefallen
- Introduction To Data Science Prod Edxapp Edx CDN OrgDokument32 SeitenIntroduction To Data Science Prod Edxapp Edx CDN OrgFarhanaNoch keine Bewertungen
- The Definitive Guide to Getting Started with OpenCart 2.xVon EverandThe Definitive Guide to Getting Started with OpenCart 2.xNoch keine Bewertungen
- Lab 1 - Getting Started With Azure MLDokument16 SeitenLab 1 - Getting Started With Azure MLTuấn VuNoch keine Bewertungen
- 01 - Lab - 1- Mô phỏng ADSDokument19 Seiten01 - Lab - 1- Mô phỏng ADSNguyễn Ngọc TháiNoch keine Bewertungen
- How to Write a Bulk Emails Application in Vb.Net and Mysql: Step by Step Fully Working ProgramVon EverandHow to Write a Bulk Emails Application in Vb.Net and Mysql: Step by Step Fully Working ProgramNoch keine Bewertungen
- Tutorial Del Programa SciDAVisDokument35 SeitenTutorial Del Programa SciDAVisHect FariNoch keine Bewertungen
- Dspace Solutions For Control TutorialDokument4 SeitenDspace Solutions For Control Tutorialअभिषेक कुमार उपाध्यायNoch keine Bewertungen
- Dspace Tutorial 01172007Dokument4 SeitenDspace Tutorial 01172007hsss500Noch keine Bewertungen
- 4460 Aspen Notes 2011Dokument24 Seiten4460 Aspen Notes 2011ClauDio MaRciànoNoch keine Bewertungen
- Practical File ITDokument44 SeitenPractical File ITANANYA CHURIWALA100% (1)
- DAT263x Lab1Dokument26 SeitenDAT263x Lab1akib khanNoch keine Bewertungen
- Networks LabsDokument62 SeitenNetworks LabsGautham KannanNoch keine Bewertungen
- EViews GuideDokument14 SeitenEViews GuideAnisha Jaiswal100% (1)
- Complete File IT 402Dokument43 SeitenComplete File IT 402Chitransh RanaNoch keine Bewertungen
- IT Practical File - XDokument49 SeitenIT Practical File - XcbjpjyfcgrNoch keine Bewertungen
- Introductory Econometrics: Installing and Using The Monte Carlo Simulation Excel Add-InDokument9 SeitenIntroductory Econometrics: Installing and Using The Monte Carlo Simulation Excel Add-IningsgtrNoch keine Bewertungen
- Creating A MasterDokument100 SeitenCreating A MasterFarhan AshrafNoch keine Bewertungen
- Cadence Tutorial A: Schematic Entry and Functional SimulationDokument14 SeitenCadence Tutorial A: Schematic Entry and Functional SimulationHafiz Usman MahmoodNoch keine Bewertungen
- QPA TrainingDokument13 SeitenQPA TrainingsenthilkumarNoch keine Bewertungen
- Trian Model Using WSDokument24 SeitenTrian Model Using WSk180914Noch keine Bewertungen
- Tutorial: Working With The Xilinx Tools 14.4: Part I: Setting Up A New ProjectDokument18 SeitenTutorial: Working With The Xilinx Tools 14.4: Part I: Setting Up A New ProjectSmart ClasseNoch keine Bewertungen
- Introductory Econometrics: Installing and Using The Monte Carlo Simulation Excel Add-InDokument11 SeitenIntroductory Econometrics: Installing and Using The Monte Carlo Simulation Excel Add-InrishipathNoch keine Bewertungen
- EEE521 Lab Assignment 1Dokument12 SeitenEEE521 Lab Assignment 1Anonymous dnfePOzPlMNoch keine Bewertungen
- Introduction To Modelsim: Installation and Simulating A Decoder InstallationDokument8 SeitenIntroduction To Modelsim: Installation and Simulating A Decoder InstallationAyush ThakurNoch keine Bewertungen
- Lab 01 - Getting - StartedDokument13 SeitenLab 01 - Getting - StartedMuath AfeshatNoch keine Bewertungen
- How-To - Standard RPA Execution Reporting With KibanaDokument20 SeitenHow-To - Standard RPA Execution Reporting With KibanaUdayNoch keine Bewertungen
- Create Tests in The Open Source Tool TCExamDokument5 SeitenCreate Tests in The Open Source Tool TCExambrian DeckerNoch keine Bewertungen
- Lab 6Dokument5 SeitenLab 6ibrahim zayedNoch keine Bewertungen
- Arena TutorialDokument8 SeitenArena TutorialCoxa100NocaoNoch keine Bewertungen
- Lesson 1: Creating A Report Server Project: Business Intelligence Development StudioDokument17 SeitenLesson 1: Creating A Report Server Project: Business Intelligence Development StudioVishal SinghNoch keine Bewertungen
- Practical File X ITDokument20 SeitenPractical File X ITRohan SinghNoch keine Bewertungen
- Prediction Sas TutDokument3 SeitenPrediction Sas Tutapi-26356906Noch keine Bewertungen
- Bi Final Journal PDFDokument94 SeitenBi Final Journal PDFpariNoch keine Bewertungen
- Questa Getting StartedDokument12 SeitenQuesta Getting StartedSanjai RadhakrishnanNoch keine Bewertungen
- Uipath Kibana RPA How-To Version 1Dokument16 SeitenUipath Kibana RPA How-To Version 1williawoNoch keine Bewertungen
- Riverbed ModelerDokument11 SeitenRiverbed ModelerSamuel Lopez RuizNoch keine Bewertungen
- IT Practical File 2022 HPSDokument43 SeitenIT Practical File 2022 HPSdeathslayerz806Noch keine Bewertungen
- Cadence NCVerilog Tutorial FL21Dokument6 SeitenCadence NCVerilog Tutorial FL21Pruthvi MistryNoch keine Bewertungen
- BootstrapDokument8 SeitenBootstrapmisko007Noch keine Bewertungen
- Introductory Econometrics: Installing and Using The Monte Carlo Simulation Excel Add-InDokument12 SeitenIntroductory Econometrics: Installing and Using The Monte Carlo Simulation Excel Add-Inrogue8Noch keine Bewertungen
- Tutorial 4: Accessing Databases Using The Dataenvironment ControllDokument11 SeitenTutorial 4: Accessing Databases Using The Dataenvironment ControllPANKAJ100% (1)
- Sqltools Tutorial enDokument12 SeitenSqltools Tutorial ensasa68Noch keine Bewertungen
- Project View (Part 3 - Study Cases) : Etap T I PDokument5 SeitenProject View (Part 3 - Study Cases) : Etap T I PCharles MoncyNoch keine Bewertungen
- Centurion Data ManagmentDokument5 SeitenCenturion Data ManagmentDIEGO MARTIN MAESONoch keine Bewertungen
- DSpace Tutorial 01172007Dokument4 SeitenDSpace Tutorial 01172007Ashish RanjanNoch keine Bewertungen
- Material 3 - System Identification TutorialDokument41 SeitenMaterial 3 - System Identification TutorialJannata Savira TNoch keine Bewertungen
- Cognos Framework Manager ExampleDokument7 SeitenCognos Framework Manager ExampleMadhes Analyst100% (1)
- Getting Started With Postgis: TopicDokument30 SeitenGetting Started With Postgis: TopicSAMINA ATTARINoch keine Bewertungen
- Add SubDokument5 SeitenAdd SubJeff WillNoch keine Bewertungen
- Mslearn dp100 03Dokument3 SeitenMslearn dp100 03Emily RapaniNoch keine Bewertungen
- The Code Behind The Tool: Building Your Own Bandwidth CalculatorDokument19 SeitenThe Code Behind The Tool: Building Your Own Bandwidth CalculatorABCDNoch keine Bewertungen
- Modelsim Short TutorialDokument14 SeitenModelsim Short TutorialLalit KumarNoch keine Bewertungen
- Quartus Tutorial 2 Simulation PDFDokument25 SeitenQuartus Tutorial 2 Simulation PDFBill GonzálezNoch keine Bewertungen
- Retrieving Data From OPC Server-Excel-OPC VBA Macro-1Dokument19 SeitenRetrieving Data From OPC Server-Excel-OPC VBA Macro-1toufik1986Noch keine Bewertungen
- Installing and Using The Monte Carlo Simulation Excel Add-InDokument11 SeitenInstalling and Using The Monte Carlo Simulation Excel Add-InMact Manit Cse AlumniAssociationNoch keine Bewertungen
- Tutorial 3: Accessing Databases Using The ADO Data Control: ContentsDokument9 SeitenTutorial 3: Accessing Databases Using The ADO Data Control: ContentsPANKAJ100% (2)
- FlowMaster 04 How Do IDokument7 SeitenFlowMaster 04 How Do Ijoseluis789Noch keine Bewertungen
- Automation Studio TutorialDokument15 SeitenAutomation Studio TutorialSuresh Gobee100% (1)
- Introduction To SAR Interferometry: ArsetDokument31 SeitenIntroduction To SAR Interferometry: ArsetIgo CandeeiroNoch keine Bewertungen
- Session3 SAR EnglishDokument37 SeitenSession3 SAR EnglishIgo CandeeiroNoch keine Bewertungen
- Lab Assignment #1 Introduction To Geographic Data 1. LogisticsDokument16 SeitenLab Assignment #1 Introduction To Geographic Data 1. LogisticsIgo CandeeiroNoch keine Bewertungen
- PostDocTopic CO2LeakageInventory2021 (969035)Dokument1 SeitePostDocTopic CO2LeakageInventory2021 (969035)Igo CandeeiroNoch keine Bewertungen
- Latihan Bahasa Melayu Kertas 1 UPSRDokument7 SeitenLatihan Bahasa Melayu Kertas 1 UPSRshahruddin Bin Subari89% (53)
- Assignment 4Dokument5 SeitenAssignment 4Hafiz AhmadNoch keine Bewertungen
- Draft PDFDokument166 SeitenDraft PDFashwaq000111Noch keine Bewertungen
- Production of Bioethanol From Empty Fruit Bunch (Efb) of Oil PalmDokument26 SeitenProduction of Bioethanol From Empty Fruit Bunch (Efb) of Oil PalmcelestavionaNoch keine Bewertungen
- 1995 Biology Paper I Marking SchemeDokument13 Seiten1995 Biology Paper I Marking Schemetramysss100% (2)
- List of Some Common Surgical TermsDokument5 SeitenList of Some Common Surgical TermsShakil MahmodNoch keine Bewertungen
- Ilocos Norte Youth Development Office Accomplishment Report 2Dokument17 SeitenIlocos Norte Youth Development Office Accomplishment Report 2Solsona Natl HS MaanantengNoch keine Bewertungen
- EGurukul - RetinaDokument23 SeitenEGurukul - RetinaOscar Daniel Mendez100% (1)
- Introduction To Atomistic Simulation Through Density Functional TheoryDokument21 SeitenIntroduction To Atomistic Simulation Through Density Functional TheoryTarang AgrawalNoch keine Bewertungen
- Transportasi Distribusi MigasDokument25 SeitenTransportasi Distribusi MigasDian Permatasari100% (1)
- 19c Upgrade Oracle Database Manually From 12C To 19CDokument26 Seiten19c Upgrade Oracle Database Manually From 12C To 19Cjanmarkowski23Noch keine Bewertungen
- 385C Waw1-Up PDFDokument4 Seiten385C Waw1-Up PDFJUNA RUSANDI SNoch keine Bewertungen
- Binary OptionsDokument24 SeitenBinary Optionssamsa7Noch keine Bewertungen
- Low Budget Music Promotion and PublicityDokument41 SeitenLow Budget Music Promotion and PublicityFola Folayan100% (3)
- in 30 MinutesDokument5 Seitenin 30 MinutesCésar DiazNoch keine Bewertungen
- Vemu Institute of Technology: Department of Computer Science & EngineeringDokument79 SeitenVemu Institute of Technology: Department of Computer Science & EngineeringSiva SankarNoch keine Bewertungen
- Math 9 Quiz 4Dokument3 SeitenMath 9 Quiz 4Lin SisombounNoch keine Bewertungen
- Regional Manager Business Development in Atlanta GA Resume Jay GriffithDokument2 SeitenRegional Manager Business Development in Atlanta GA Resume Jay GriffithJayGriffithNoch keine Bewertungen
- Agency Canvas Ing PresentationDokument27 SeitenAgency Canvas Ing Presentationkhushi jaiswalNoch keine Bewertungen
- Midi Pro Adapter ManualDokument34 SeitenMidi Pro Adapter ManualUli ZukowskiNoch keine Bewertungen
- Comparison of PubMed, Scopus, Web of Science, and Google Scholar - Strengths and WeaknessesDokument5 SeitenComparison of PubMed, Scopus, Web of Science, and Google Scholar - Strengths and WeaknessesMostafa AbdelrahmanNoch keine Bewertungen
- Feed-Pump Hydraulic Performance and Design Improvement, Phase I: J2esearch Program DesignDokument201 SeitenFeed-Pump Hydraulic Performance and Design Improvement, Phase I: J2esearch Program DesignJonasNoch keine Bewertungen
- BMGT 200 Assignment 2 Answer KeysDokument3 SeitenBMGT 200 Assignment 2 Answer Keysharout keshishianNoch keine Bewertungen
- Mosharaf HossainDokument2 SeitenMosharaf HossainRuhul RajNoch keine Bewertungen
- ThorpeDokument267 SeitenThorpezaeem73Noch keine Bewertungen
- P 348Dokument196 SeitenP 348a123456978Noch keine Bewertungen
- SyncopeDokument105 SeitenSyncopeJohn DasNoch keine Bewertungen
- 3 Diversion&CareDokument2 Seiten3 Diversion&CareRyan EncomiendaNoch keine Bewertungen
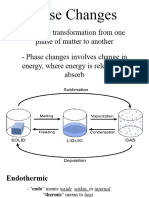
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDokument19 SeitenGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaNoch keine Bewertungen
- MEd TG G07 EN 04-Oct Digital PDFDokument94 SeitenMEd TG G07 EN 04-Oct Digital PDFMadhan GanesanNoch keine Bewertungen
- Wallem Philippines Shipping Inc. v. S.R. Farms (Laxamana)Dokument2 SeitenWallem Philippines Shipping Inc. v. S.R. Farms (Laxamana)WENDELL LAXAMANANoch keine Bewertungen
- Data Visualization: A Practical IntroductionVon EverandData Visualization: A Practical IntroductionBewertung: 5 von 5 Sternen5/5 (2)
- Blender 3D for Jobseekers: Learn professional 3D creation skills using Blender 3D (English Edition)Von EverandBlender 3D for Jobseekers: Learn professional 3D creation skills using Blender 3D (English Edition)Noch keine Bewertungen
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceVon EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNoch keine Bewertungen
- How to Create Cpn Numbers the Right way: A Step by Step Guide to Creating cpn Numbers LegallyVon EverandHow to Create Cpn Numbers the Right way: A Step by Step Guide to Creating cpn Numbers LegallyBewertung: 4 von 5 Sternen4/5 (27)
- Beginning AutoCAD® 2022 Exercise Workbook: For Windows®Von EverandBeginning AutoCAD® 2022 Exercise Workbook: For Windows®Noch keine Bewertungen
- 2022 Adobe® Premiere Pro Guide For Filmmakers and YouTubersVon Everand2022 Adobe® Premiere Pro Guide For Filmmakers and YouTubersBewertung: 5 von 5 Sternen5/5 (1)
- Learn Power BI: A beginner's guide to developing interactive business intelligence solutions using Microsoft Power BIVon EverandLearn Power BI: A beginner's guide to developing interactive business intelligence solutions using Microsoft Power BIBewertung: 5 von 5 Sternen5/5 (1)
- The Designer’s Guide to Figma: Master Prototyping, Collaboration, Handoff, and WorkflowVon EverandThe Designer’s Guide to Figma: Master Prototyping, Collaboration, Handoff, and WorkflowNoch keine Bewertungen
- Skulls & Anatomy: Copyright Free Vintage Illustrations for Artists & DesignersVon EverandSkulls & Anatomy: Copyright Free Vintage Illustrations for Artists & DesignersNoch keine Bewertungen
- Photoshop: A Step by Step Ultimate Beginners’ Guide to Mastering Adobe Photoshop in 1 WeekVon EverandPhotoshop: A Step by Step Ultimate Beginners’ Guide to Mastering Adobe Photoshop in 1 WeekNoch keine Bewertungen
- NFT per Creators: La guida pratica per creare, investire e vendere token non fungibili ed arte digitale nella blockchain: Guide sul metaverso e l'arte digitale con le criptovaluteVon EverandNFT per Creators: La guida pratica per creare, investire e vendere token non fungibili ed arte digitale nella blockchain: Guide sul metaverso e l'arte digitale con le criptovaluteBewertung: 5 von 5 Sternen5/5 (15)
- Animation for Beginners: Getting Started with Animation FilmmakingVon EverandAnimation for Beginners: Getting Started with Animation FilmmakingBewertung: 3 von 5 Sternen3/5 (1)
- Mastering YouTube Automation: The Ultimate Guide to Creating a Successful Faceless ChannelVon EverandMastering YouTube Automation: The Ultimate Guide to Creating a Successful Faceless ChannelNoch keine Bewertungen
- Tableau Your Data!: Fast and Easy Visual Analysis with Tableau SoftwareVon EverandTableau Your Data!: Fast and Easy Visual Analysis with Tableau SoftwareBewertung: 4.5 von 5 Sternen4.5/5 (4)
- Blender 3D Basics Beginner's Guide Second EditionVon EverandBlender 3D Basics Beginner's Guide Second EditionBewertung: 5 von 5 Sternen5/5 (1)
- Windows 11 for Beginners: The Complete Step-by-Step User Guide to Learn and Take Full Use of Windows 11 (A Windows 11 Manual with Useful Tips & Tricks)Von EverandWindows 11 for Beginners: The Complete Step-by-Step User Guide to Learn and Take Full Use of Windows 11 (A Windows 11 Manual with Useful Tips & Tricks)Bewertung: 5 von 5 Sternen5/5 (1)