Das könnte Ihnen auch gefallen
- Learn Statistics Fast: A Simplified Detailed Version for StudentsVon EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNoch keine Bewertungen
- NERC System Protection and Control Subcommittee SPCS 20 SAMS-SPCS SPS Technic 02182014Dokument48 SeitenNERC System Protection and Control Subcommittee SPCS 20 SAMS-SPCS SPS Technic 02182014sykimk8921Noch keine Bewertungen
- Matlab-Based Voltage Stability AnalysisDokument5 SeitenMatlab-Based Voltage Stability AnalysisSharsu GadgetNoch keine Bewertungen
- PV Curve For Voltage StabilityDokument1 SeitePV Curve For Voltage Stabilityveeru_puppalaNoch keine Bewertungen
- Etap Validation Cases and Comparison Results: Load FlowDokument66 SeitenEtap Validation Cases and Comparison Results: Load FlowK.RamachandranNoch keine Bewertungen
- Standard Numbering For Small Wiring For Switch Gear and AssociatedDokument4 SeitenStandard Numbering For Small Wiring For Switch Gear and AssociatedPaul JonesNoch keine Bewertungen
- Chapter 10Dokument35 SeitenChapter 10Venkata KalyanNoch keine Bewertungen
- Matlab-Based Voltage Stability Analysis Toolbox and Its Validity CheckDokument5 SeitenMatlab-Based Voltage Stability Analysis Toolbox and Its Validity Checkwvargas926Noch keine Bewertungen
- ArcFlash Example4 PDFDokument7 SeitenArcFlash Example4 PDFashraf-84Noch keine Bewertungen
- Symmetrical Components Made EasyDokument9 SeitenSymmetrical Components Made Easys_banerjeeNoch keine Bewertungen
- CT Saturation and Its Influence On Protective RelaysDokument11 SeitenCT Saturation and Its Influence On Protective RelaysMijhael Tuesta HerreraNoch keine Bewertungen
- Matlab For SHRT Circuit AnalysisDokument6 SeitenMatlab For SHRT Circuit AnalysisM B Hemanth KumarNoch keine Bewertungen
- Causes and statistics of power substation protection system misoperationsDokument6 SeitenCauses and statistics of power substation protection system misoperationsOscar GarciaNoch keine Bewertungen
- HVDC TransmissionDokument78 SeitenHVDC Transmissiondhay aliNoch keine Bewertungen
- Poweremt: Protection System Analysis and Testing Using Electro-Magnetic Transients SimulationDokument48 SeitenPoweremt: Protection System Analysis and Testing Using Electro-Magnetic Transients Simulationdebajyoti ghoshNoch keine Bewertungen
- T TestsDokument64 SeitenT TestsFaheemudheen KNoch keine Bewertungen
- Motor Starting Dynamic AccelerationDokument63 SeitenMotor Starting Dynamic Accelerationashraf-84Noch keine Bewertungen
- SudhirDokument24 SeitenSudhirKomal MathurNoch keine Bewertungen
- Voltage Stability: (Definition and Concept)Dokument33 SeitenVoltage Stability: (Definition and Concept)sadia moinNoch keine Bewertungen
- MEN System of EarthningDokument6 SeitenMEN System of EarthningstarykltNoch keine Bewertungen
- Voltage Stability Toolbox For Power System Education and ResearchDokument11 SeitenVoltage Stability Toolbox For Power System Education and Researchamir_seifiNoch keine Bewertungen
- Relaying Applications of Traveling Waves: Dr.M.Manjula ProfessorDokument61 SeitenRelaying Applications of Traveling Waves: Dr.M.Manjula ProfessornemarjeltnNoch keine Bewertungen
- Short 74 Power Swing DetectionDokument29 SeitenShort 74 Power Swing Detectionpriyanka236Noch keine Bewertungen
- Performing Power Factor Test On Dry-Type Transformer During Commissioning - EEP-1 PDFDokument14 SeitenPerforming Power Factor Test On Dry-Type Transformer During Commissioning - EEP-1 PDFNADEEM KHANNoch keine Bewertungen
- TVSS UL Spec 1449Dokument2 SeitenTVSS UL Spec 1449nbashir786Noch keine Bewertungen
- Motor de Induccion ETAPDokument20 SeitenMotor de Induccion ETAPgabriel_87Noch keine Bewertungen
- Low Voltage Selectivity With ABB Circuit Breakers (1SDC007100G0202)Dokument56 SeitenLow Voltage Selectivity With ABB Circuit Breakers (1SDC007100G0202)Eduardo ZapataNoch keine Bewertungen
- Medium Voltage Cable Training 02242023010240Dokument36 SeitenMedium Voltage Cable Training 02242023010240NOELGREGORIONoch keine Bewertungen
- EL07 Coordination System of Low Voltage Circuit Breaker - PresentationDokument39 SeitenEL07 Coordination System of Low Voltage Circuit Breaker - PresentationJhonSitanala100% (1)
- 1MRG009835 en Application Note 87T For Step-Up Transformer Consisting of Three Single-Phase Units PDFDokument5 Seiten1MRG009835 en Application Note 87T For Step-Up Transformer Consisting of Three Single-Phase Units PDFrajeshNoch keine Bewertungen
- Site Inspection and Test Record: 1. General Data and InformationDokument5 SeitenSite Inspection and Test Record: 1. General Data and InformationSohail AhmedNoch keine Bewertungen
- Unsymmetrical FaultsDokument16 SeitenUnsymmetrical FaultsBhairab BoseNoch keine Bewertungen
- Hpi RCDDokument25 SeitenHpi RCDapi-3728789Noch keine Bewertungen
- Statistics Can Be Broadly Classified Into Two Categories Namely (I) Descriptive Statistics and (II) Inferential StatisticsDokument59 SeitenStatistics Can Be Broadly Classified Into Two Categories Namely (I) Descriptive Statistics and (II) Inferential Statisticstradag0% (1)
- 2 Tutorial Handouts 300Dokument30 Seiten2 Tutorial Handouts 300Cu Teo100% (1)
- Fundamental of Power System Protection - Paithankar&Bidhe.2003Dokument335 SeitenFundamental of Power System Protection - Paithankar&Bidhe.2003AyyubRezpectorNoch keine Bewertungen
- Automatic Voltage Regulator Test Instructions and Report for 120 MW Gas Turbine GeneratorDokument225 SeitenAutomatic Voltage Regulator Test Instructions and Report for 120 MW Gas Turbine Generatorsantoshkumar777100% (1)
- E M 1 Lab ManualDokument63 SeitenE M 1 Lab ManualdsparanthamanNoch keine Bewertungen
- BIDRAM - MPPT Shading Review PDFDokument15 SeitenBIDRAM - MPPT Shading Review PDFGeyciane PinheiroNoch keine Bewertungen
- Power System StabilityDokument150 SeitenPower System StabilityRavichandran Sekar100% (1)
- Optimal Power Flow Simulation in Deregulated EnvironmentDokument13 SeitenOptimal Power Flow Simulation in Deregulated EnvironmentGuru MishraNoch keine Bewertungen
- Sel-411l - Line DifferentialDokument21 SeitenSel-411l - Line DifferentialRatheesh KumarNoch keine Bewertungen
- Power System Faults Analysis PDFDokument191 SeitenPower System Faults Analysis PDFmarkigldmm918Noch keine Bewertungen
- Transient Stability Events and ActionsDokument8 SeitenTransient Stability Events and ActionsAnonymous xBi2FsBxNoch keine Bewertungen
- Cable Testing Report By: Neetrac: Presented By: Tapas Ankit KumarDokument21 SeitenCable Testing Report By: Neetrac: Presented By: Tapas Ankit KumartapasNoch keine Bewertungen
- Voltage Shunt Feedback AmplifierDokument18 SeitenVoltage Shunt Feedback AmplifierHimanshu Singh100% (1)
- Bushing CT Report 75 MVADokument7 SeitenBushing CT Report 75 MVARajnarayan Karmaker0% (1)
- P630 DemoDokument71 SeitenP630 DemoIlaiyaa RajaNoch keine Bewertungen
- ECE 576 Power System Dynamics and Stability Lecture NotesDokument28 SeitenECE 576 Power System Dynamics and Stability Lecture Notes7harma V1swaNoch keine Bewertungen
- de 6 Dca 404 CDokument31 Seitende 6 Dca 404 CFarrukh JamilNoch keine Bewertungen
- Inferential Statistics PART 1 PresentationDokument28 SeitenInferential Statistics PART 1 PresentationwqlqqNoch keine Bewertungen
- Inferential Statistic IDokument83 SeitenInferential Statistic IThiviyashiniNoch keine Bewertungen
- MATRIKULASI STATISTIKDokument78 SeitenMATRIKULASI STATISTIKArisa MayNoch keine Bewertungen
- Hypothesis Testing Guide for Behavioral ScienceDokument31 SeitenHypothesis Testing Guide for Behavioral ScienceSushant SinghNoch keine Bewertungen
- Elle. HYPOTHESIS TESTINGDokument25 SeitenElle. HYPOTHESIS TESTINGJhianne EstacojaNoch keine Bewertungen
- Hypothesis TestDokument57 SeitenHypothesis TestVirgilio AbellanaNoch keine Bewertungen
- Eda Hypothesis Testing For Single SampleDokument6 SeitenEda Hypothesis Testing For Single SampleMaryang DescartesNoch keine Bewertungen
- Lecture 4 Hypothesis SamplingDokument59 SeitenLecture 4 Hypothesis SamplingDstormNoch keine Bewertungen
- Hypothesis TestingDokument86 SeitenHypothesis TestingMohammed AdusNoch keine Bewertungen
- Opening Bell: Market Outlook Today's HighlightsDokument7 SeitenOpening Bell: Market Outlook Today's HighlightsDevendra MahajanNoch keine Bewertungen
- Technology2020 and Beyond PDFDokument48 SeitenTechnology2020 and Beyond PDFMegha BepariNoch keine Bewertungen
- Customer-Based Marketing Metrics: Source: Reinartz and Kumar, Database Marketing Berry and LinhoffDokument32 SeitenCustomer-Based Marketing Metrics: Source: Reinartz and Kumar, Database Marketing Berry and LinhoffDevendra MahajanNoch keine Bewertungen
- Liebherr-Catalogue IndiaDokument38 SeitenLiebherr-Catalogue IndiaDevendra Mahajan100% (1)
- Apiemspaper Tiena 14oct17 PDFDokument8 SeitenApiemspaper Tiena 14oct17 PDFDevendra MahajanNoch keine Bewertungen
- JoinnusonepagerenglishjunioDokument1 SeiteJoinnusonepagerenglishjunioDevendra MahajanNoch keine Bewertungen
- Electronics March 2015 PDFDokument1 SeiteElectronics March 2015 PDFDevendra MahajanNoch keine Bewertungen
- MBA-CET2018 Result Withheld 19may2018 PDFDokument1 SeiteMBA-CET2018 Result Withheld 19may2018 PDFDevendra MahajanNoch keine Bewertungen
- M.SC - Finance Application Form 2018 20Dokument3 SeitenM.SC - Finance Application Form 2018 20lucifer1711Noch keine Bewertungen
- Arrive Find Seat Make Paste Select Plate Eat Stack Plates & Pay LeaveDokument2 SeitenArrive Find Seat Make Paste Select Plate Eat Stack Plates & Pay LeaveDevendra MahajanNoch keine Bewertungen
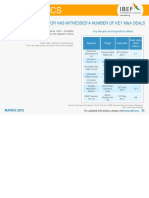
- Electronics: The Sector Has Witnessed A Number of Key M&A DealsDokument1 SeiteElectronics: The Sector Has Witnessed A Number of Key M&A DealsDevendra MahajanNoch keine Bewertungen
- Ch7.JOB COSTINGDokument17 SeitenCh7.JOB COSTINGDevendra MahajanNoch keine Bewertungen
- M SC - Finance-Notification PDFDokument2 SeitenM SC - Finance-Notification PDFDevendra MahajanNoch keine Bewertungen
- Novavax and SK Bioscience Collaborate For NVXCoV2373 Covid19 Vaccine CandidateDokument1 SeiteNovavax and SK Bioscience Collaborate For NVXCoV2373 Covid19 Vaccine CandidateDevendra MahajanNoch keine Bewertungen
- Setting Reserve Prices PDFDokument22 SeitenSetting Reserve Prices PDFDevendra MahajanNoch keine Bewertungen
- Maharashtra Engineering Services (Mechanical), Group-A & B (Main) Examination परी ा योजनाDokument2 SeitenMaharashtra Engineering Services (Mechanical), Group-A & B (Main) Examination परी ा योजनाÁbhijit SheteNoch keine Bewertungen
- PGP 1920 IE Lec 2 Agg SCRDokument26 SeitenPGP 1920 IE Lec 2 Agg SCRDevendra MahajanNoch keine Bewertungen
- Financial Analysis of The Blue Economy: Sagarmala's Case in PointDokument39 SeitenFinancial Analysis of The Blue Economy: Sagarmala's Case in PointCFA IndiaNoch keine Bewertungen
- TSP Assignment GDokument2 SeitenTSP Assignment GDevendra MahajanNoch keine Bewertungen
- CompensationDokument1 SeiteCompensationDevendra MahajanNoch keine Bewertungen
- Opening Bell: Market Outlook Today's HighlightsDokument7 SeitenOpening Bell: Market Outlook Today's HighlightsDevendra MahajanNoch keine Bewertungen
- Bharat MalaDokument12 SeitenBharat MalakarthickpadmanabanNoch keine Bewertungen
- SaevjtiDokument3 SeitenSaevjtiDevendra MahajanNoch keine Bewertungen
- EuropeanJournalofOperationalResearch51 PDFDokument19 SeitenEuropeanJournalofOperationalResearch51 PDFDevendra MahajanNoch keine Bewertungen
- EuropeanJournalofOperationalResearch51 PDFDokument19 SeitenEuropeanJournalofOperationalResearch51 PDFDevendra MahajanNoch keine Bewertungen
- Daft OT11e PPT Ch01Dokument18 SeitenDaft OT11e PPT Ch01Jason Higgins100% (1)
- AbcDokument5 SeitenAbcDevendra MahajanNoch keine Bewertungen
- Quiz 2 Solution HintsDokument1 SeiteQuiz 2 Solution HintsDevendra MahajanNoch keine Bewertungen
- C6 - Liquid Chemical Company - Final2Dokument4 SeitenC6 - Liquid Chemical Company - Final2Gandhi MardiNoch keine Bewertungen
- Concise Biostatistics ManualDokument85 SeitenConcise Biostatistics ManualMANASA AswathNoch keine Bewertungen
- Just ThingsDokument4 SeitenJust ThingsJason VillaverdeNoch keine Bewertungen
- STA102 - Simple Corr - RegressionDokument37 SeitenSTA102 - Simple Corr - RegressionMehedi HasanNoch keine Bewertungen
- 14 Appendix 3 N-Way Anova FormulaDokument2 Seiten14 Appendix 3 N-Way Anova FormulaRenelito Dichos TangkayNoch keine Bewertungen
- Risk and Managerial (Real) Options in Capital Budgeting Risk and Managerial (Real) Options in Capital BudgetingDokument42 SeitenRisk and Managerial (Real) Options in Capital Budgeting Risk and Managerial (Real) Options in Capital BudgetingAhmed El KhateebNoch keine Bewertungen
- Notes 4Dokument11 SeitenNotes 4Alzany OsmanNoch keine Bewertungen
- Intermediate Statistics Sample Test 1Dokument17 SeitenIntermediate Statistics Sample Test 1muralidharan0% (3)
- Chapter 2: Traditional and Behavioral FinanceDokument22 SeitenChapter 2: Traditional and Behavioral FinanceGeeta RanjanNoch keine Bewertungen
- Chapter 4 VocabDokument2 SeitenChapter 4 VocabJordon HaltemanNoch keine Bewertungen
- S.Y.B.Sc Comp - Science Operation ReseaechDokument19 SeitenS.Y.B.Sc Comp - Science Operation ReseaechSanket shinde100% (1)
- Chapter 4 Regression Models: Quantitative Analysis For Management, 11e (Render)Dokument27 SeitenChapter 4 Regression Models: Quantitative Analysis For Management, 11e (Render)Jay BrockNoch keine Bewertungen
- ANOVADokument15 SeitenANOVAStocknEarnNoch keine Bewertungen
- Ag213 Unit 5 Online PDFDokument29 SeitenAg213 Unit 5 Online PDFNaiker KaveetNoch keine Bewertungen
- Game PlayingDokument24 SeitenGame PlayingAayush “Ashu”Noch keine Bewertungen
- Discrete Choice Models: William Greene Stern School of Business New York UniversityDokument24 SeitenDiscrete Choice Models: William Greene Stern School of Business New York Universitymmorvin89Noch keine Bewertungen
- ('Christos Papadimitriou', 'Midterm 2', ' (Solution) ') Fall 2009 PDFDokument4 Seiten('Christos Papadimitriou', 'Midterm 2', ' (Solution) ') Fall 2009 PDFJohn SmithNoch keine Bewertungen
- Bayesian Logistic Regression Modelling Via Markov Chain Monte Carlo Algorithm - Henry De-Graft AcquahDokument5 SeitenBayesian Logistic Regression Modelling Via Markov Chain Monte Carlo Algorithm - Henry De-Graft AcquahSantiago FucciNoch keine Bewertungen
- Dice throw simulation quantifies potential lossesDokument3 SeitenDice throw simulation quantifies potential lossesTimmy OngNoch keine Bewertungen
- Regression Analysis Random MotorsDokument11 SeitenRegression Analysis Random MotorsNivedita Nautiyal100% (1)
- Pengaruh Pelatihan Dan Pengalaman Mengajar Terhadap Profesionalisme GuruDokument20 SeitenPengaruh Pelatihan Dan Pengalaman Mengajar Terhadap Profesionalisme GuruLita DiansyahNoch keine Bewertungen
- Simple Linear RegressionDokument55 SeitenSimple Linear RegressionPatrick HernandezNoch keine Bewertungen
- Assignment 2 - 2020Dokument3 SeitenAssignment 2 - 2020Mpho NkuNoch keine Bewertungen
- Factors Affecting Performance of Village Officers in Ampana Sub-District, Tojo Una-UnaDokument9 SeitenFactors Affecting Performance of Village Officers in Ampana Sub-District, Tojo Una-UnaNely Noer SofwatiNoch keine Bewertungen
- 01 Decision AnalysisDokument8 Seiten01 Decision AnalysisChendie C. MayaNoch keine Bewertungen
- CHAPTER 9 Game TheoryDokument27 SeitenCHAPTER 9 Game TheorychuchuNoch keine Bewertungen
- Summary of Formulas For Time Value of MoneyDokument3 SeitenSummary of Formulas For Time Value of MoneyMarilyn Varquez100% (1)
- FRM PPT Risk Adjusted Rate of Return in CapitalDokument10 SeitenFRM PPT Risk Adjusted Rate of Return in CapitalRachna MarcusNoch keine Bewertungen
- HeteroskedasticityDokument23 SeitenHeteroskedasticityAgung Setiawan100% (1)
- IRC - Risk and UncertaintyDokument5 SeitenIRC - Risk and Uncertaintynur iman qurrataini abdul rahmanNoch keine Bewertungen
- Stat 111 | Section 8: BayesianDokument7 SeitenStat 111 | Section 8: BayesianEricNoch keine Bewertungen