Das könnte Ihnen auch gefallen
- The Currency Correlation Secret - TwoDokument10 SeitenThe Currency Correlation Secret - Twofebrichow100% (1)
- Guide To Indicators: How Technical Indicators Help Improve Your Trade AnalysisDokument53 SeitenGuide To Indicators: How Technical Indicators Help Improve Your Trade AnalysissuksanNoch keine Bewertungen
- Descriptive Statistics Chapter SummaryDokument15 SeitenDescriptive Statistics Chapter Summary23985811100% (2)
- MACD and Technical AnalysisDokument20 SeitenMACD and Technical AnalysisThugy Dee100% (3)
- CA FINAL Strategic Financial Management NotesDokument299 SeitenCA FINAL Strategic Financial Management NotesGopika CA100% (1)
- Module 3 Descriptive Statistics FinalDokument15 SeitenModule 3 Descriptive Statistics FinalJordine Umayam100% (1)
- Project 10 (StatisticsDokument14 SeitenProject 10 (StatisticsArkin DuttaNoch keine Bewertungen
- Beginners Guide To AmiBroker A AJAN K KDokument185 SeitenBeginners Guide To AmiBroker A AJAN K KHaNguyenNoch keine Bewertungen
- Forecasting Ppt01Dokument119 SeitenForecasting Ppt01LeojelaineIgcoy100% (1)
- Trading Smart With Moving Averages-080811Dokument52 SeitenTrading Smart With Moving Averages-080811James100% (3)
- Technical Analysis MasterClass CheatSheet PDFDokument14 SeitenTechnical Analysis MasterClass CheatSheet PDFAman KumarNoch keine Bewertungen
- New Concept in RSIDokument25 SeitenNew Concept in RSIYagnesh Patel86% (7)
- Zig Zag. 2 Compilations LatestDokument23 SeitenZig Zag. 2 Compilations LatestkosurugNoch keine Bewertungen
- Introduction To Non Parametric Methods Through R SoftwareVon EverandIntroduction To Non Parametric Methods Through R SoftwareNoch keine Bewertungen
- Handbook of Human Resources Management-Springer-Verlag Berlin Heidelberg (2016) PDFDokument1.414 SeitenHandbook of Human Resources Management-Springer-Verlag Berlin Heidelberg (2016) PDFzulfiqar26100% (1)
- Descriptive Statistics Explained: Measures of Central Tendency, Spread and ShapeDokument34 SeitenDescriptive Statistics Explained: Measures of Central Tendency, Spread and ShapeNAVANEETHNoch keine Bewertungen
- Manufacturing Forecasting SheetDokument10 SeitenManufacturing Forecasting SheetArun kumar rouniyar100% (1)
- Measures of Central Tendency: A Guide to AveragesDokument36 SeitenMeasures of Central Tendency: A Guide to Averagesroshni100% (1)
- Statistical Machine LearningDokument12 SeitenStatistical Machine LearningDeva Hema100% (1)
- Content 2:: Descriptive and Inferential StatisticsDokument59 SeitenContent 2:: Descriptive and Inferential StatisticsJohn FuerzasNoch keine Bewertungen
- Technical Analysis Introduction: Key Concepts and Tools ExplainedDokument65 SeitenTechnical Analysis Introduction: Key Concepts and Tools Explainedmr25000Noch keine Bewertungen
- Overview Of Bayesian Approach To Statistical Methods: SoftwareVon EverandOverview Of Bayesian Approach To Statistical Methods: SoftwareNoch keine Bewertungen
- Statistics in Research ExplainedDokument26 SeitenStatistics in Research ExplainedStevoh100% (2)
- Wayne A. Thorp - Technical Analysis PDFDokument33 SeitenWayne A. Thorp - Technical Analysis PDFSalomão LealNoch keine Bewertungen
- Nicolas Vandeput - Data Science For Supply Chain Forecasting-De Gruyter (2021)Dokument310 SeitenNicolas Vandeput - Data Science For Supply Chain Forecasting-De Gruyter (2021)Jeampierr JIMENEZ MARQUEZ80% (5)
- Merits and DemeritsDokument10 SeitenMerits and DemeritsRamesh SafareNoch keine Bewertungen
- Statistics Document Title Under 40 CharactersDokument9 SeitenStatistics Document Title Under 40 CharactersTejashwi KumarNoch keine Bewertungen
- Unit-2-Business Statistics-Desc StatDokument26 SeitenUnit-2-Business Statistics-Desc StatDeepa SelvamNoch keine Bewertungen
- Unit 1 Repaired)Dokument8 SeitenUnit 1 Repaired)mussaiyibNoch keine Bewertungen
- Mean Median, ModeDokument15 SeitenMean Median, Mode21010324029Noch keine Bewertungen
- Measures of central Tendency and statistical averagesDokument14 SeitenMeasures of central Tendency and statistical averagesmojnkuNoch keine Bewertungen
- Merits and Demerits of MeanDokument6 SeitenMerits and Demerits of Meananil gond100% (2)
- Stats NotesDokument16 SeitenStats NotesDivyanshuNoch keine Bewertungen
- Mean Median AnswersDokument10 SeitenMean Median Answerstoy sanghaNoch keine Bewertungen
- Basics for Understanding Statistics in 40 CharactersDokument8 SeitenBasics for Understanding Statistics in 40 CharacterssamNoch keine Bewertungen
- Measure of Central TendencyDokument33 SeitenMeasure of Central Tendencydemondida100% (1)
- Name-Shilpi Singh Patel Assignment Set - 1 Programe - M.B.A. Semester - 1 Subject Code - Mb0040 Subject - Statistics For ManagementDokument9 SeitenName-Shilpi Singh Patel Assignment Set - 1 Programe - M.B.A. Semester - 1 Subject Code - Mb0040 Subject - Statistics For Managementgp1987Noch keine Bewertungen
- Business Statistics & Analytics For Decision Making Assignment 1 Franklin BabuDokument9 SeitenBusiness Statistics & Analytics For Decision Making Assignment 1 Franklin Babufranklin100% (1)
- Measures of Dispersion EditDokument8 SeitenMeasures of Dispersion EditShimaa KashefNoch keine Bewertungen
- Unit IVDokument80 SeitenUnit IVneelabhronanda02Noch keine Bewertungen
- PGDISM Assignments 05 06Dokument12 SeitenPGDISM Assignments 05 06ashishNoch keine Bewertungen
- MEasures of Central TendencyDokument12 SeitenMEasures of Central TendencyPranjal KulkarniNoch keine Bewertungen
- Qm-Lesson 4Dokument16 SeitenQm-Lesson 4jedowen sagangNoch keine Bewertungen
- Business StatisticsDokument52 SeitenBusiness StatisticsShabana Shaikh-100% (1)
- Exploring Measures of Central Tendency in Business StatisticsDokument3 SeitenExploring Measures of Central Tendency in Business StatisticsJM Enteria100% (1)
- Mba Semester 1 Mb0040 - Statistics For Management-4 Credits (Book ID: B1129) Assignment Set - 1 (60 Marks)Dokument9 SeitenMba Semester 1 Mb0040 - Statistics For Management-4 Credits (Book ID: B1129) Assignment Set - 1 (60 Marks)guptarohitkumarNoch keine Bewertungen
- Business Statistics Unit 2Dokument17 SeitenBusiness Statistics Unit 2Janardhan VNoch keine Bewertungen
- Measures of VariabilityDokument21 SeitenMeasures of VariabilitybeckonashiNoch keine Bewertungen
- Define StatisticsDokument89 SeitenDefine StatisticskhanjiNoch keine Bewertungen
- Define StatisticsDokument89 SeitenDefine StatisticskhanjiNoch keine Bewertungen
- Descriptive StatisticsDokument4 SeitenDescriptive StatisticsRaghad Al QweeflNoch keine Bewertungen
- Presentation On Data Analysis: Submitted byDokument38 SeitenPresentation On Data Analysis: Submitted byAmisha PopliNoch keine Bewertungen
- Unit 1 - Business Statistics & AnalyticsDokument25 SeitenUnit 1 - Business Statistics & Analyticsk89794Noch keine Bewertungen
- Measurement of Central TendencyDokument2 SeitenMeasurement of Central TendencyAbrar AhmadNoch keine Bewertungen
- Measures of Central TendencyDokument30 SeitenMeasures of Central TendencyYukti SharmaNoch keine Bewertungen
- BUSINESS STATISTICS MEASURESDokument16 SeitenBUSINESS STATISTICS MEASURESPnx RageNoch keine Bewertungen
- FROM DR Neerja NigamDokument75 SeitenFROM DR Neerja Nigamamankhore86Noch keine Bewertungen
- Tutorial 15Dokument7 SeitenTutorial 15Yeong Zi YingNoch keine Bewertungen
- Mba Semester 1 Mb0040 - Statistics For Management-4 Credits (Book ID: B1129) Assignment Set - 1 (60 Marks)Dokument10 SeitenMba Semester 1 Mb0040 - Statistics For Management-4 Credits (Book ID: B1129) Assignment Set - 1 (60 Marks)amarendrasumanNoch keine Bewertungen
- Answers B.S.Dokument9 SeitenAnswers B.S.khushi vaswaniNoch keine Bewertungen
- 14 - Chapter 7 PDFDokument39 Seiten14 - Chapter 7 PDFMay Anne M. ArceoNoch keine Bewertungen
- Using Assessment Data to Measure Student PerformanceDokument6 SeitenUsing Assessment Data to Measure Student PerformanceJessa Mae CantilloNoch keine Bewertungen
- 1 Descriptive Statistics - UnlockedDokument18 Seiten1 Descriptive Statistics - UnlockedNidaOkuyazTüregünNoch keine Bewertungen
- Descriptive Statistics: Summarizing and Analyzing DataDokument2 SeitenDescriptive Statistics: Summarizing and Analyzing DataNeña Dela Torre GanzonNoch keine Bewertungen
- Measures of Central Tendency: Mean, Mode, MedianDokument30 SeitenMeasures of Central Tendency: Mean, Mode, Medianafnan nabiNoch keine Bewertungen
- Central TendencyDokument6 SeitenCentral TendencyShashank DeshmukhNoch keine Bewertungen
- Unit-3 DS StudentsDokument35 SeitenUnit-3 DS StudentsHarpreet Singh BaggaNoch keine Bewertungen
- List The Importance of Data Analysis in Daily LifeDokument6 SeitenList The Importance of Data Analysis in Daily LifeKogilan Bama DavenNoch keine Bewertungen
- SEM 1 MB0040 1 Statistics For ManagementDokument8 SeitenSEM 1 MB0040 1 Statistics For ManagementKumar GollapudiNoch keine Bewertungen
- Measures Central Tendency Mean Mode MedianDokument26 SeitenMeasures Central Tendency Mean Mode MedianHetal Koringa patelNoch keine Bewertungen
- Data Analysis Mean Median Mode Statistics GuideDokument54 SeitenData Analysis Mean Median Mode Statistics Guidemusharraf anjumNoch keine Bewertungen
- Statistics basics introDokument5 SeitenStatistics basics introAryan SharmaNoch keine Bewertungen
- Gaaan 1Dokument26 SeitenGaaan 1Ayesha ChNoch keine Bewertungen
- Letter For ExemptionDokument9 SeitenLetter For ExemptionJean NjeruNoch keine Bewertungen
- Personalization: Name: P.Shyam Reg No: 19331E0086Dokument7 SeitenPersonalization: Name: P.Shyam Reg No: 19331E0086Shyam MaariNoch keine Bewertungen
- 19331E0073-N.SAI KRISHNA - A Model of Compensation DecisionsDokument7 Seiten19331E0073-N.SAI KRISHNA - A Model of Compensation DecisionsShyam MaariNoch keine Bewertungen
- Functions of Front Office: Name: P.Shyam REG NO: 19331E0086Dokument5 SeitenFunctions of Front Office: Name: P.Shyam REG NO: 19331E0086Shyam MaariNoch keine Bewertungen
- HRM SubjectsDokument23 SeitenHRM SubjectsShyam MaariNoch keine Bewertungen
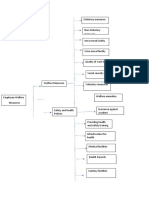
- Diagram Employee Welfare (Shyam 19331E0086)Dokument2 SeitenDiagram Employee Welfare (Shyam 19331E0086)Shyam MaariNoch keine Bewertungen
- Finance ManagementDokument184 SeitenFinance ManagementShyam MaariNoch keine Bewertungen
- Retail Management-Unit III - Cluster 4Dokument14 SeitenRetail Management-Unit III - Cluster 4Shyam MaariNoch keine Bewertungen
- Diagram Employee Welfare (Shyam 19331E0086)Dokument2 SeitenDiagram Employee Welfare (Shyam 19331E0086)Shyam MaariNoch keine Bewertungen
- Ch6 - Designing The Marketing ChannelDokument30 SeitenCh6 - Designing The Marketing ChannelShyam MaariNoch keine Bewertungen
- 19331E0086 Logistics Supply Chain ManagementDokument7 Seiten19331E0086 Logistics Supply Chain ManagementShyam MaariNoch keine Bewertungen
- Operations MNGTDokument6 SeitenOperations MNGTShyam MaariNoch keine Bewertungen
- Team-C Report DoneDokument7 SeitenTeam-C Report DoneShyam MaariNoch keine Bewertungen
- 3 - Strategic ManagementDokument7 Seiten3 - Strategic ManagementShyam MaariNoch keine Bewertungen
- Capital Structure DeterminentsDokument3 SeitenCapital Structure DeterminentsShyam MaariNoch keine Bewertungen
- Work StudyDokument18 SeitenWork StudyShyam MaariNoch keine Bewertungen
- Block-4 MS-53 Unit-1 PDFDokument13 SeitenBlock-4 MS-53 Unit-1 PDFShyam MaariNoch keine Bewertungen
- Dividend Decission Profit - Vs-Dividend: Income Distribution in A CompanyDokument6 SeitenDividend Decission Profit - Vs-Dividend: Income Distribution in A CompanyShyam MaariNoch keine Bewertungen
- Cash ManagementDokument3 SeitenCash ManagementShyam MaariNoch keine Bewertungen
- II YEAR III SEMESTER (Online)Dokument1 SeiteII YEAR III SEMESTER (Online)Shyam MaariNoch keine Bewertungen
- Factories Act 1948Dokument56 SeitenFactories Act 1948Shyam MaariNoch keine Bewertungen
- International Finance Course ObjectivesDokument4 SeitenInternational Finance Course ObjectivesShyam MaariNoch keine Bewertungen
- Finance ManagementDokument184 SeitenFinance ManagementShyam MaariNoch keine Bewertungen
- ANDHRA UNIVERSITY MHRM ADMISSION 2019-20Dokument33 SeitenANDHRA UNIVERSITY MHRM ADMISSION 2019-20Shyam MaariNoch keine Bewertungen
- Environmental Scanning and Approaches: PaperDokument18 SeitenEnvironmental Scanning and Approaches: PaperShyam MaariNoch keine Bewertungen
- Essentials of Strategic ManagementDokument22 SeitenEssentials of Strategic ManagementManivannancNoch keine Bewertungen
- Personality Development ModuleDokument12 SeitenPersonality Development ModuleShyam MaariNoch keine Bewertungen
- Essentials of Strategic ManagementDokument22 SeitenEssentials of Strategic ManagementManivannancNoch keine Bewertungen
- Marketing Concepts and EvolutionDokument13 SeitenMarketing Concepts and EvolutionShyam MaariNoch keine Bewertungen
- Marketing Concepts and EvolutionDokument13 SeitenMarketing Concepts and EvolutionShyam MaariNoch keine Bewertungen
- Tracking Time Series DataDokument8 SeitenTracking Time Series DataPrasiddha PradhanNoch keine Bewertungen
- Forecasting: Operations ManagementDokument50 SeitenForecasting: Operations ManagementoumaimaNoch keine Bewertungen
- IIFL Amey Kulkarni PDFDokument48 SeitenIIFL Amey Kulkarni PDFPALLAVI KAMBLENoch keine Bewertungen
- Quatech ProjectsDokument63 SeitenQuatech ProjectsBlairEmrallafNoch keine Bewertungen
- Unit 8 Technical Analysis: ObjectivesDokument13 SeitenUnit 8 Technical Analysis: Objectivesveggi expressNoch keine Bewertungen
- GoklDokument14 SeitenGoklsadeqNoch keine Bewertungen
- Summer Internship Report on Financial Management at IIFL SecuritiesDokument36 SeitenSummer Internship Report on Financial Management at IIFL Securitieschander mauli tripathiNoch keine Bewertungen
- SCM ReportDokument10 SeitenSCM ReportAhsan IqbalNoch keine Bewertungen
- Latest Generation Sinter Process Optimization SystemsDokument21 SeitenLatest Generation Sinter Process Optimization SystemsolongkodokNoch keine Bewertungen
- TSM WebsiteContentsDokument21 SeitenTSM WebsiteContentsMaria Cherry0% (1)
- July 2020 Greenwich Maritime Quantitative Methods ExamDokument9 SeitenJuly 2020 Greenwich Maritime Quantitative Methods ExamHaroon GNoch keine Bewertungen
- Chapter-4 - PROJECT EVALUATION AND ANALYSISDokument121 SeitenChapter-4 - PROJECT EVALUATION AND ANALYSISnuhaminNoch keine Bewertungen
- Pro Real Time - ProscreenerDokument36 SeitenPro Real Time - Proscreener11727Noch keine Bewertungen
- The Complete Beginner's Guide To Technical AnalysisDokument10 SeitenThe Complete Beginner's Guide To Technical AnalysisAngie LeeNoch keine Bewertungen
- Unit 15 Business ForecastingDokument21 SeitenUnit 15 Business ForecastingQuynh NguyenNoch keine Bewertungen
- MM Certification QUESTIONSDokument4 SeitenMM Certification QUESTIONSRamasare NishadNoch keine Bewertungen