Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Create A Neural Network in 7 Steps - Neural DesignerDokument11 SeitenCreate A Neural Network in 7 Steps - Neural DesignerRamón RuizNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
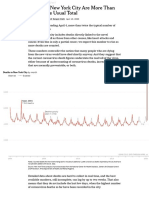
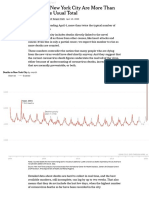
- Deaths in New York City Are More Than Double The Usual Total - The New York Times PDFDokument3 SeitenDeaths in New York City Are More Than Double The Usual Total - The New York Times PDFRamón RuizNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Deaths in New York City Are More Than Double The Usual TotalDokument3 SeitenDeaths in New York City Are More Than Double The Usual TotalRamón RuizNoch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- A Whirlwind Tour of The World of (, 1) - CategoriesDokument46 SeitenA Whirlwind Tour of The World of (, 1) - CategoriesRamón RuizNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- A Short Course On - CategoriesDokument77 SeitenA Short Course On - CategoriesRamón RuizNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Stuff About QuasicategoriesDokument146 SeitenStuff About QuasicategoriesRamón RuizNoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elements of - Category Theory PDFDokument522 SeitenElements of - Category Theory PDFRamón Ruiz100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Explaining How People Assess Credibility Online PDFDokument2 SeitenExplaining How People Assess Credibility Online PDFRamón RuizNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Tomasello-Gonzalez-Cabrera2017 Article TheRoleOfOntogenyInTheEvolutio PDFDokument15 SeitenTomasello-Gonzalez-Cabrera2017 Article TheRoleOfOntogenyInTheEvolutio PDFRamón RuizNoch keine Bewertungen
- Pattern ClassificationDokument41 SeitenPattern ClassificationShashaank Mattur AswathaNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Etizion The Third Way To A Good SocietyDokument33 SeitenEtizion The Third Way To A Good SocietyRamón RuizNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Lecture 05 - Addendum - Chisquare, T and F DistributionsDokument8 SeitenLecture 05 - Addendum - Chisquare, T and F DistributionsNajmi TajudinNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- SCE52001 Advanced Engineering Mathematics Notes 1Dokument24 SeitenSCE52001 Advanced Engineering Mathematics Notes 1Alexander AlexanderNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Introduction To Linear Regression and Correlation Analysis: ObjectivesDokument33 SeitenIntroduction To Linear Regression and Correlation Analysis: ObjectivesJude Patrick SabaybayNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Hotz and Schaller - 2021 - Coarse-Graining Master Equation For Periodically DDokument11 SeitenHotz and Schaller - 2021 - Coarse-Graining Master Equation For Periodically DvdbNoch keine Bewertungen
- Assignment #2Dokument3 SeitenAssignment #2Darlene Ramirez Peña0% (1)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Quantum TeleportationDokument19 SeitenQuantum TeleportationSai SaranNoch keine Bewertungen
- Stats and ProbabilityDokument17 SeitenStats and ProbabilityLeonard Anthony DeladiaNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Appreciation Including Gratitude and Affective WelDokument11 SeitenAppreciation Including Gratitude and Affective WelSwarangi SNoch keine Bewertungen
- Journal SynopsisDokument2 SeitenJournal SynopsisTeo Ming HaoNoch keine Bewertungen
- Chapter 5 - Continuous Probability DistributionDokument42 SeitenChapter 5 - Continuous Probability DistributionDiep Anh PhanNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- ENGR 371 Chapter 3Dokument10 SeitenENGR 371 Chapter 3Nicholas FrancoNoch keine Bewertungen
- MG221: Applied Probability & Statistics: Syllabus 2018Dokument2 SeitenMG221: Applied Probability & Statistics: Syllabus 2018psychshetty439Noch keine Bewertungen
- The Mathematics of Modern Physics: DescriptionDokument2 SeitenThe Mathematics of Modern Physics: DescriptionBintang KejoraNoch keine Bewertungen
- Levene's TestDokument2 SeitenLevene's TestJoseph_NuamahNoch keine Bewertungen
- Quantum Mechanics. Theory and Experiment PDFDokument529 SeitenQuantum Mechanics. Theory and Experiment PDFHemanta Upadhaya100% (1)
- Zeeman and Paschen-Back EffectDokument12 SeitenZeeman and Paschen-Back EffectKamanpreet Singh100% (1)
- Personality Psychology Foundations and Findings 1st Edition Miserandino Test BankDokument31 SeitenPersonality Psychology Foundations and Findings 1st Edition Miserandino Test Bankkatherinefordneptqrwcyb100% (11)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- 1964 An Algebraic Approach To Quantum Field TheoryDokument15 Seiten1964 An Algebraic Approach To Quantum Field Theoryphys zhangNoch keine Bewertungen
- Week2 StatisticsDokument7 SeitenWeek2 StatisticsNancy LantinganNoch keine Bewertungen
- Hydrogen Atom and Non Euclidean GeometryDokument11 SeitenHydrogen Atom and Non Euclidean GeometryMichel MarcondesNoch keine Bewertungen
- Lesson 4 Communication ModelsDokument8 SeitenLesson 4 Communication ModelsJanelle Fem NovelasNoch keine Bewertungen
- Marxist CriticismDokument20 SeitenMarxist CriticismBhakti Bagoes Ibrahim100% (1)
- Probing Chaos by Magic MonotonesDokument26 SeitenProbing Chaos by Magic MonotonesJassiel JimenezNoch keine Bewertungen
- JurnalDokument18 SeitenJurnaliqlima zahraNoch keine Bewertungen
- STAT 2006 Chapter 3 - 2022Dokument60 SeitenSTAT 2006 Chapter 3 - 2022Hiu Yin YuenNoch keine Bewertungen
- ERG Theory and Adams' EquityDokument3 SeitenERG Theory and Adams' EquityParami RanaweeraNoch keine Bewertungen
- Sakurai 1.17Dokument11 SeitenSakurai 1.17uberpawsNoch keine Bewertungen
- Department of Physics, University of Pennsylvania Philadelphia, PA 19104-6396, USADokument26 SeitenDepartment of Physics, University of Pennsylvania Philadelphia, PA 19104-6396, USABayer MitrovicNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Modern Atomic TheoryDokument2 SeitenModern Atomic TheorySamantha Chim ParkNoch keine Bewertungen
- The Standard Model of Particle Physics FinalDokument29 SeitenThe Standard Model of Particle Physics Finalcifarha venantNoch keine Bewertungen