Das könnte Ihnen auch gefallen
- Practical Foundations For Programming LanguagesDokument340 SeitenPractical Foundations For Programming LanguagesrahulvgopinathNoch keine Bewertungen
- Firebase Ebook PDFDokument35 SeitenFirebase Ebook PDFwelingtonlNoch keine Bewertungen
- Learn Ruby The Hard Way (Part 2)Dokument6 SeitenLearn Ruby The Hard Way (Part 2)irohaNoch keine Bewertungen
- Architecture of Complex Web ApplicationsDokument257 SeitenArchitecture of Complex Web ApplicationsJesus Palencia RamirezNoch keine Bewertungen
- Hilary S One Page DevOps Engineer Resume PDFDokument1 SeiteHilary S One Page DevOps Engineer Resume PDFSatheeshRajuKalidhindiNoch keine Bewertungen
- Denis Kalinin - Modern Web Development With Scala 142 (2017, Leanpub) - Libgen - LiDokument147 SeitenDenis Kalinin - Modern Web Development With Scala 142 (2017, Leanpub) - Libgen - LiSi FouNoch keine Bewertungen
- Hacker RankDokument29 SeitenHacker Rankomar moNoch keine Bewertungen
- Programmers Work at Night PDFDokument29 SeitenProgrammers Work at Night PDFreyNoch keine Bewertungen
- C100dev 3Dokument14 SeitenC100dev 3Mai PhuongNoch keine Bewertungen
- 100 Most Influential Programming Books According To Stack OverflowDokument58 Seiten100 Most Influential Programming Books According To Stack OverflowNguyễn Công Huy100% (1)
- Webgl Reference Card 1 - 0 PDFDokument4 SeitenWebgl Reference Card 1 - 0 PDFqweqwewqeqweNoch keine Bewertungen
- Re FactoringDokument16 SeitenRe Factoringmartin nad100% (3)
- Real World Next - JsDokument367 SeitenReal World Next - Jssate258Noch keine Bewertungen
- Modern C++ DesignDokument6 SeitenModern C++ DesignAndrea0% (1)
- Combinatorial Optimization: Alexander SchrijverDokument34 SeitenCombinatorial Optimization: Alexander SchrijverWilfredo FelixNoch keine Bewertungen
- Beginner's Coding SheetDokument12 SeitenBeginner's Coding SheetArya SarkarNoch keine Bewertungen
- Large Scale Apps With Svelte and TypeScript by DamDokument273 SeitenLarge Scale Apps With Svelte and TypeScript by DamTran quoc Huy100% (1)
- Linked ListDokument258 SeitenLinked ListBhavneet SinghNoch keine Bewertungen
- Computational MathematicsDokument199 SeitenComputational MathematicsEbenezer WeyaoNoch keine Bewertungen
- Codility Solutions 4Dokument14 SeitenCodility Solutions 4Ramya RamsNoch keine Bewertungen
- Algorithms Wikipedia PDFDokument2.118 SeitenAlgorithms Wikipedia PDFAayush Borkar100% (1)
- Svelte Custom Stores TypeScript Declaration - by David Dal Busco - Better ProgrammingDokument14 SeitenSvelte Custom Stores TypeScript Declaration - by David Dal Busco - Better ProgramminghowesteveNoch keine Bewertungen
- 2008 The Modern Algebra of Information RetrievalDokument332 Seiten2008 The Modern Algebra of Information RetrievalAkashNoch keine Bewertungen
- ArraysDokument471 SeitenArraysAsafAhmadNoch keine Bewertungen
- Chapter 13 Abstract Classes and InterfacesDokument55 SeitenChapter 13 Abstract Classes and InterfacesBhavik DaveNoch keine Bewertungen
- Tan Li Hau - Real-World Svelte - Supercharge Your Apps With Svelte 4 by Mastering Advanced Web Development Concepts-Packt (2023)Dokument282 SeitenTan Li Hau - Real-World Svelte - Supercharge Your Apps With Svelte 4 by Mastering Advanced Web Development Concepts-Packt (2023)AntonioMolinaNoch keine Bewertungen
- OpenACC For Programmers 2018Dokument317 SeitenOpenACC For Programmers 2018darek RaceNoch keine Bewertungen
- The Tetris Game in Java 2DDokument17 SeitenThe Tetris Game in Java 2DEnrique Emiliano Santos CantuNoch keine Bewertungen
- Chris Viau - Andrew Thornton - Ger Hobbelt, Roland Dunn-Developing A D3.Js Edge - Constructing Reusable D3 Components and Charts-Bleeding Edge PressDokument108 SeitenChris Viau - Andrew Thornton - Ger Hobbelt, Roland Dunn-Developing A D3.Js Edge - Constructing Reusable D3 Components and Charts-Bleeding Edge PresslakshmiescribdNoch keine Bewertungen
- Principles of Computer Hardware - PDF RoomDokument705 SeitenPrinciples of Computer Hardware - PDF Roomboniface ChosenNoch keine Bewertungen
- Rethinking Classical Concurrency PatternsDokument121 SeitenRethinking Classical Concurrency PatternsGopher ANoch keine Bewertungen
- Java Multi-Threading Evolution and TopicsDokument45 SeitenJava Multi-Threading Evolution and Topicsarchana gangadharNoch keine Bewertungen
- Humble Ruby BookDokument141 SeitenHumble Ruby Book5xnewxNoch keine Bewertungen
- Adobe PDFDokument151 SeitenAdobe PDFPrateek Patidar100% (1)
- Teach Yourself Computer ScienceDokument18 SeitenTeach Yourself Computer SciencesuryaNoch keine Bewertungen
- c4 Important Classes and MoreDokument168 Seitenc4 Important Classes and MoreIka Ratna Apriliani100% (1)
- Sigmod278 SilbersteinDokument12 SeitenSigmod278 SilbersteinDmytro ShteflyukNoch keine Bewertungen
- Mastering Concurrency Programming Java 8 Ebook B012o8s89k PDFDokument5 SeitenMastering Concurrency Programming Java 8 Ebook B012o8s89k PDFgen0% (1)
- Scala With CatsDokument322 SeitenScala With CatsArsenij KroptyaNoch keine Bewertungen
- Whats New Java 8Dokument112 SeitenWhats New Java 8shadowtoastaNoch keine Bewertungen
- Gdi Debug From The Windows NT Source Code LeakDokument46 SeitenGdi Debug From The Windows NT Source Code Leakillegal-manualsNoch keine Bewertungen
- BlueJ Programming: learn lots of logic based skill of BlueJVon EverandBlueJ Programming: learn lots of logic based skill of BlueJNoch keine Bewertungen
- Clojure PDFDokument1.801 SeitenClojure PDFalipiodepaulaNoch keine Bewertungen
- SOAPUI - Groovy ScriptingDokument44 SeitenSOAPUI - Groovy ScriptingVinay Gowda100% (1)
- An Introduction To The Usa Computing Olympiad: Darren YaoDokument87 SeitenAn Introduction To The Usa Computing Olympiad: Darren YaocristianNoch keine Bewertungen
- Sample Cracking Microservices InterviewsDokument32 SeitenSample Cracking Microservices InterviewsSuhas SettyNoch keine Bewertungen
- Data StructuresDokument613 SeitenData StructuresJai BishnoiNoch keine Bewertungen
- GWT RPC2Dokument14 SeitenGWT RPC2ramji013Noch keine Bewertungen
- JAVA Question BankDokument3 SeitenJAVA Question BankContact_ArindomNoch keine Bewertungen
- Data Structures and AlgorithmsDokument111 SeitenData Structures and AlgorithmsOliver KaneNoch keine Bewertungen
- Programming, Data Structures Algorithms: PythonDokument637 SeitenProgramming, Data Structures Algorithms: Pythonpavan kumar100% (1)
- Vala TutorialDokument56 SeitenVala TutorialFelipe Borges50% (2)
- UntitledDokument287 SeitenUntitledMarcos César Costa BarbosaNoch keine Bewertungen
- Bootstrap (Front-End Framework)Dokument4 SeitenBootstrap (Front-End Framework)Asad AliNoch keine Bewertungen
- A Quick Reference to Data Structures and Computer Algorithms: An Insight on the Beauty of BlockchainVon EverandA Quick Reference to Data Structures and Computer Algorithms: An Insight on the Beauty of BlockchainNoch keine Bewertungen
- Flutter for Jobseekers: Learn Flutter and take your cross-platform app development skills to the next level (English Edition)Von EverandFlutter for Jobseekers: Learn Flutter and take your cross-platform app development skills to the next level (English Edition)Noch keine Bewertungen
- Math150 PDFDokument85 SeitenMath150 PDFeterlouNoch keine Bewertungen
- Tankguard AR: Technical Data SheetDokument5 SeitenTankguard AR: Technical Data SheetAzar SKNoch keine Bewertungen
- San Francisco Chinese Christian Union, Et Al. v. City and County of San Francisco, Et Al. ComplaintDokument25 SeitenSan Francisco Chinese Christian Union, Et Al. v. City and County of San Francisco, Et Al. ComplaintFindLawNoch keine Bewertungen
- Imp121 1isDokument6 SeitenImp121 1isErnesto AyzenbergNoch keine Bewertungen
- Future Generation Computer SystemsDokument18 SeitenFuture Generation Computer SystemsEkoNoch keine Bewertungen
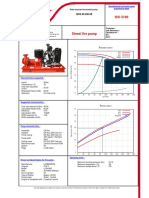
- NOS 65-200-90x60-30KWD PDFDokument2 SeitenNOS 65-200-90x60-30KWD PDFDao The ThangNoch keine Bewertungen
- Web Server ProjectDokument16 SeitenWeb Server Projectمعتز العجيليNoch keine Bewertungen
- HR Q and ADokument87 SeitenHR Q and Asanjeeb88Noch keine Bewertungen
- INSURANCE BROKER POLICIES Erna SuryawatiDokument7 SeitenINSURANCE BROKER POLICIES Erna SuryawatiKehidupan DuniawiNoch keine Bewertungen
- Inductive Grammar Chart (Unit 2, Page 16)Dokument2 SeitenInductive Grammar Chart (Unit 2, Page 16)Michael ZavalaNoch keine Bewertungen
- Galanz - Galaxy 7-9-12K - SPLIT PDFDokument42 SeitenGalanz - Galaxy 7-9-12K - SPLIT PDFUbaldo BritoNoch keine Bewertungen
- 2 Players The One With Steam BaronsDokument1 Seite2 Players The One With Steam BaronsBrad RoseNoch keine Bewertungen
- Business Mathematics and Statistics: Fundamentals ofDokument468 SeitenBusiness Mathematics and Statistics: Fundamentals ofSamirNoch keine Bewertungen
- My New ResumeDokument1 SeiteMy New Resumeapi-412394530Noch keine Bewertungen
- RS485 ManualDokument7 SeitenRS485 Manualndtruc100% (2)
- Capitol Medical Center, Inc. v. NLRCDokument14 SeitenCapitol Medical Center, Inc. v. NLRCFidel Rico NiniNoch keine Bewertungen
- Scout Activities On The Indian Railways - Original Order: MC No. SubjectDokument4 SeitenScout Activities On The Indian Railways - Original Order: MC No. SubjectVikasvijay SinghNoch keine Bewertungen
- Basics Stats Ti NspireDokument7 SeitenBasics Stats Ti NspirePanagiotis SotiropoulosNoch keine Bewertungen
- Phet Body Group 1 ScienceDokument42 SeitenPhet Body Group 1 ScienceMebel Alicante GenodepanonNoch keine Bewertungen
- Guide On Multiple RegressionDokument29 SeitenGuide On Multiple RegressionLucyl MendozaNoch keine Bewertungen
- Item No. 6 Diary No 6856 2024 ConsolidatedDokument223 SeitenItem No. 6 Diary No 6856 2024 Consolidatedisha NagpalNoch keine Bewertungen
- Mind Mapping BIOTEKDokument1 SeiteMind Mapping BIOTEKAdrian Muhammad RonalNoch keine Bewertungen
- DMP 2021 TPJ SRDokument275 SeitenDMP 2021 TPJ SRishu sNoch keine Bewertungen
- Ibt - Module 2 International Trade - Theories Are: Classical and Are From The PerspectiveDokument9 SeitenIbt - Module 2 International Trade - Theories Are: Classical and Are From The PerspectiveLyca NegrosNoch keine Bewertungen
- PraxiarDokument8 SeitenPraxiara_roy003Noch keine Bewertungen
- Instructions For The Safe Use Of: Web LashingsDokument2 SeitenInstructions For The Safe Use Of: Web LashingsVij Vaibhav VermaNoch keine Bewertungen
- Meco ReviewerDokument9 SeitenMeco ReviewerKang ChulNoch keine Bewertungen
- Q3 Week 1 Homeroom Guidance JGRDokument9 SeitenQ3 Week 1 Homeroom Guidance JGRJasmin Goot Rayos50% (4)
- DCF ModelDokument14 SeitenDCF ModelTera ByteNoch keine Bewertungen
- Current Matching Control System For Multi-Terminal DC Transmission To Integrate Offshore Wind FarmsDokument6 SeitenCurrent Matching Control System For Multi-Terminal DC Transmission To Integrate Offshore Wind FarmsJackie ChuNoch keine Bewertungen
- Dolby Atmos Specifications PDFDokument24 SeitenDolby Atmos Specifications PDFVanya ValdovinosNoch keine Bewertungen