Das könnte Ihnen auch gefallen
- Using Using Using Using Using Using Using Using Using Namespace Public Partial Class PublicDokument4 SeitenUsing Using Using Using Using Using Using Using Using Namespace Public Partial Class PublicKristian GatchalianNoch keine Bewertungen
- Coin SeperatorDokument4 SeitenCoin SeperatorKristian GatchalianNoch keine Bewertungen
- Accepting Command Line Arguments in C Using Argc and ArgvDokument2 SeitenAccepting Command Line Arguments in C Using Argc and ArgvKristian Gatchalian100% (1)
- Package PongV2Dokument21 SeitenPackage PongV2Kristian GatchalianNoch keine Bewertungen
- Edit Death Statement of The Pythia Pythia Chaerephon Apollo Elenchus Daimonic VoiceDokument1 SeiteEdit Death Statement of The Pythia Pythia Chaerephon Apollo Elenchus Daimonic VoiceKristian GatchalianNoch keine Bewertungen
- Pandistritong Tagisan NG Talento Sa Filipino 2018: Petsa: Pagpapatala: SimulaDokument2 SeitenPandistritong Tagisan NG Talento Sa Filipino 2018: Petsa: Pagpapatala: SimulaKristian Gatchalian100% (1)
- Verse 1: @0:11: HappierDokument2 SeitenVerse 1: @0:11: HappierKristian GatchalianNoch keine Bewertungen
- Directed by Produced by Screenplay by Based On Starring: Charlotte's WebDokument5 SeitenDirected by Produced by Screenplay by Based On Starring: Charlotte's WebKristian GatchalianNoch keine Bewertungen
- ResearchDokument3 SeitenResearchKristian GatchalianNoch keine Bewertungen
- Charles' Law: Gr11 Chem Unit 2: Gases and The Atmosphere, Lesson 6: Volume, TemperatureDokument3 SeitenCharles' Law: Gr11 Chem Unit 2: Gases and The Atmosphere, Lesson 6: Volume, TemperatureKristian GatchalianNoch keine Bewertungen
- 5 Experiments 1 Final (AWIN)Dokument8 Seiten5 Experiments 1 Final (AWIN)Kristian GatchalianNoch keine Bewertungen
- ModeDokument15 SeitenModeKristian GatchalianNoch keine Bewertungen
- Genetically Modified OrganismsDokument14 SeitenGenetically Modified OrganismsKristian GatchalianNoch keine Bewertungen
- Migration of IonsDokument6 SeitenMigration of IonsKristian GatchalianNoch keine Bewertungen
- Aristotele Vs Galilean Views of MotionDokument6 SeitenAristotele Vs Galilean Views of MotionKristian GatchalianNoch keine Bewertungen
- Turn Milk Into PlasticDokument5 SeitenTurn Milk Into PlasticKristian Gatchalian100% (1)
- Mass Versus Weight: Matter Force Gravity Earth Gravitational Field Strength Newton Kilogram Mars SaturnDokument2 SeitenMass Versus Weight: Matter Force Gravity Earth Gravitational Field Strength Newton Kilogram Mars SaturnKristian GatchalianNoch keine Bewertungen
- Objectives To Determine How High The Balls Bounce Materials: ProceduresDokument6 SeitenObjectives To Determine How High The Balls Bounce Materials: ProceduresKristian GatchalianNoch keine Bewertungen
- "Simplest Form of Reproduction": Group 2Dokument13 Seiten"Simplest Form of Reproduction": Group 2Kristian GatchalianNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Heap Sort: Input: One-Dimension Array Advantages of Insertion Sort and Merge Sort Heap SortDokument26 SeitenHeap Sort: Input: One-Dimension Array Advantages of Insertion Sort and Merge Sort Heap SortMohammed HajjajNoch keine Bewertungen
- Digital Signal Processing 10EC52Dokument50 SeitenDigital Signal Processing 10EC52Ratish NairNoch keine Bewertungen
- Lecture HW 04 RootsDokument12 SeitenLecture HW 04 RootssmashthecommienwoNoch keine Bewertungen
- Queue: Dept. of Computer Science Faculty of Science and TechnologyDokument21 SeitenQueue: Dept. of Computer Science Faculty of Science and TechnologyRehaan RazibNoch keine Bewertungen
- PPL BookDokument179 SeitenPPL Booksanams141Noch keine Bewertungen
- MCQ Unit 4Dokument14 SeitenMCQ Unit 4SIVALAKSHMINoch keine Bewertungen
- Graph Theory-Mfcs MaterialDokument67 SeitenGraph Theory-Mfcs MaterialKiran KumarNoch keine Bewertungen
- First Order Logic (Artificial Intelligence)Dokument39 SeitenFirst Order Logic (Artificial Intelligence)Ali SiddiquiNoch keine Bewertungen
- Computer AssignmentDokument19 SeitenComputer AssignmentGayathri G KurupNoch keine Bewertungen
- A Course in CombinatoricsDokument618 SeitenA Course in CombinatoricsWalner Mendonça Santos100% (19)
- Chapter 5. Arrays and StringsDokument49 SeitenChapter 5. Arrays and StringsminhquangelNoch keine Bewertungen
- For of KcetDokument16 SeitenFor of KcetJagannath JagguNoch keine Bewertungen
- ProgramsDokument82 SeitenProgramsSudha MadhuriNoch keine Bewertungen
- Sheet 1Dokument2 SeitenSheet 1Mohamed FaragNoch keine Bewertungen
- Name: Student No. Group: - Expression Tree - : Csc248 - Fundamentals of Data Structures Tree: Class ExerciseDokument4 SeitenName: Student No. Group: - Expression Tree - : Csc248 - Fundamentals of Data Structures Tree: Class ExerciseKimpiz ITNoch keine Bewertungen
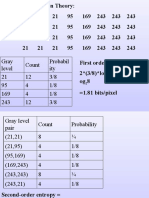
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Dokument51 SeitenGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaNoch keine Bewertungen
- Fast HMM MapMatchingDokument19 SeitenFast HMM MapMatchingMohamed Abderrahim FellaouineNoch keine Bewertungen
- Lecture 09 - Calculus and Optimization Techniques (3) - PlainDokument15 SeitenLecture 09 - Calculus and Optimization Techniques (3) - PlainRajaNoch keine Bewertungen
- AI QBank Unit 1&2Dokument4 SeitenAI QBank Unit 1&2Shreyash DeshpandeNoch keine Bewertungen
- F (X) X G (X) X X: Delfinado, Mia Jaymee P. Laboratory Exercise # 3 May 12, 2020 ECE120L-C24 Jonathan OracionDokument7 SeitenF (X) X G (X) X X: Delfinado, Mia Jaymee P. Laboratory Exercise # 3 May 12, 2020 ECE120L-C24 Jonathan OracionJaymee DelfinadoNoch keine Bewertungen
- Data Structure and Algorithms - Two Mark Questions and AnswersDokument6 SeitenData Structure and Algorithms - Two Mark Questions and AnswersJanuNoch keine Bewertungen
- Practical Artificial Intelligence Programming in Java Mark WatsonDokument124 SeitenPractical Artificial Intelligence Programming in Java Mark WatsonSafarudin100% (2)
- Rod Cutting Problem - Techie DelightDokument8 SeitenRod Cutting Problem - Techie DelightSuman JyotiNoch keine Bewertungen
- Semidefinite Relaxation of Quadratic Optimization ProblemsDokument14 SeitenSemidefinite Relaxation of Quadratic Optimization ProblemschandrasekaranNoch keine Bewertungen
- Week 6Dokument15 SeitenWeek 6Franz NatayadaNoch keine Bewertungen
- Ada LabDokument23 SeitenAda LabbalakrishnaNoch keine Bewertungen
- 1 IntroductionDokument24 Seiten1 IntroductiontenpointerNoch keine Bewertungen
- Data Structure Full NotesDokument72 SeitenData Structure Full NotesSuper Hit MoviesNoch keine Bewertungen
- Dijkstra's Algorithm: Project TitleDokument13 SeitenDijkstra's Algorithm: Project TitleAkul SrinidhiNoch keine Bewertungen
- Lecture Notes For Chapter 7 Introduction To Data Mining, 2 EditionDokument108 SeitenLecture Notes For Chapter 7 Introduction To Data Mining, 2 Editionhanifa puspaNoch keine Bewertungen