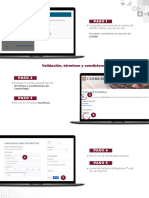
Das könnte Ihnen auch gefallen
- Stakeholders - Una Mirada A Los Grupos de InteresDokument2 SeitenStakeholders - Una Mirada A Los Grupos de InteresMiguel SuarezNoch keine Bewertungen
- Renovación E-Conciencia 2023Dokument1 SeiteRenovación E-Conciencia 2023Miguel SuarezNoch keine Bewertungen
- Diapositivas Semana 1Dokument24 SeitenDiapositivas Semana 1Miguel SuarezNoch keine Bewertungen
- Guia para La Realizacion de Examen de Ingles Cambridge + SUMADIDokument20 SeitenGuia para La Realizacion de Examen de Ingles Cambridge + SUMADIMiguel SuarezNoch keine Bewertungen
- Guía de Psicologia Itinerario OrganizacionalDokument35 SeitenGuía de Psicologia Itinerario OrganizacionalMiguel SuarezNoch keine Bewertungen
- Configuración Del Aplicativo SumadiDokument5 SeitenConfiguración Del Aplicativo SumadiMiguel SuarezNoch keine Bewertungen
- Guía de Instalación SumadiDokument2 SeitenGuía de Instalación SumadiMiguel SuarezNoch keine Bewertungen
- Empowerment y CoachingDokument5 SeitenEmpowerment y CoachingMiguel SuarezNoch keine Bewertungen
- Equipos de Alto DesempeñoDokument3 SeitenEquipos de Alto DesempeñoMiguel SuarezNoch keine Bewertungen
- Instalación en Mac SumadiDokument2 SeitenInstalación en Mac SumadiMiguel SuarezNoch keine Bewertungen
- Formador de FormadoresDokument4 SeitenFormador de FormadoresMiguel SuarezNoch keine Bewertungen
- Pago Busqueda FoneticaDokument1 SeitePago Busqueda FoneticaMiguel SuarezNoch keine Bewertungen
- Sueldos Asesores y AsambleistasDokument32 SeitenSueldos Asesores y AsambleistasMiguel Suarez75% (4)
- Carta CompromisoDokument1 SeiteCarta CompromisoMiguel SuarezNoch keine Bewertungen
- Competencias LaboralesDokument3 SeitenCompetencias LaboralesMiguel SuarezNoch keine Bewertungen
- Eficiencia Personal y EmpresarialDokument3 SeitenEficiencia Personal y EmpresarialMiguel SuarezNoch keine Bewertungen
- Coaching EmpresarialDokument4 SeitenCoaching EmpresarialMiguel SuarezNoch keine Bewertungen
- Propuesta Curso OSINT LATINOAMERICADokument5 SeitenPropuesta Curso OSINT LATINOAMERICAMiguel SuarezNoch keine Bewertungen
- Coaching CorporativoDokument4 SeitenCoaching CorporativoMiguel SuarezNoch keine Bewertungen
- Cronograma - OI 1C 2022Dokument2 SeitenCronograma - OI 1C 2022Miguel SuarezNoch keine Bewertungen
- Ejemplos de Argumentos y FalaciasDokument4 SeitenEjemplos de Argumentos y FalaciasMiguel SuarezNoch keine Bewertungen
- 39 - C001 - Aplicacion - para - La - Certificacion - de - Personas Gestión de Turismo Rural y ComunitarioDokument6 Seiten39 - C001 - Aplicacion - para - La - Certificacion - de - Personas Gestión de Turismo Rural y ComunitarioMiguel SuarezNoch keine Bewertungen
- Aparato Locomotor-HuesosDokument3 SeitenAparato Locomotor-HuesosMiguel SuarezNoch keine Bewertungen
- Test Alessandra - ExplicacionDokument6 SeitenTest Alessandra - ExplicacionMiguel SuarezNoch keine Bewertungen
- Programa Calificado Por La SociedadDokument10 SeitenPrograma Calificado Por La SociedadMiguel SuarezNoch keine Bewertungen
- Parcial ResueltoDokument4 SeitenParcial ResueltoMiguel SuarezNoch keine Bewertungen
- Test de Alessandra Metodo y DesarrolloDokument4 SeitenTest de Alessandra Metodo y DesarrolloMiguel Suarez0% (1)
- ResumenDokument8 SeitenResumenAlejandra Inés NuñezNoch keine Bewertungen
- Error Decodificar Ber PDFDokument2 SeitenError Decodificar Ber PDFAlineNoch keine Bewertungen
- Extensiones de ArchivosssDokument9 SeitenExtensiones de ArchivosssJuan JoNoch keine Bewertungen
- KSG1 U3 A2 EfraDokument6 SeitenKSG1 U3 A2 EfraEfra RinconNoch keine Bewertungen
- Actividad Unity 2d1.1Dokument11 SeitenActividad Unity 2d1.1Pedro MuñozNoch keine Bewertungen
- MN Gtwin EsDokument302 SeitenMN Gtwin EsQuiqueNoch keine Bewertungen
- Formato - Historia de Usuario 2Dokument3 SeitenFormato - Historia de Usuario 2Daniel MendozaNoch keine Bewertungen
- Plan FinalDokument86 SeitenPlan FinalHansNoch keine Bewertungen
- Acta de Entrega de Equipo de ComputoDokument1 SeiteActa de Entrega de Equipo de ComputoDanilo MaxNoch keine Bewertungen
- Formato Reporte de IncidentesDokument4 SeitenFormato Reporte de IncidentesJessica UrregoNoch keine Bewertungen
- Ejemplo de Diseño de Una Base de DatosDokument11 SeitenEjemplo de Diseño de Una Base de DatossantiagoNoch keine Bewertungen
- Taller Función SIDokument12 SeitenTaller Función SIXSUSOXDNoch keine Bewertungen
- Live Usb GPGDokument108 SeitenLive Usb GPGantornioNoch keine Bewertungen
- Historial de RevisionDokument6 SeitenHistorial de RevisionPaul ContrerasNoch keine Bewertungen
- Estudiante Manual - 03Dokument8 SeitenEstudiante Manual - 03Dubithsa Quispe QuispeNoch keine Bewertungen
- TERRITORIUM Manual de UsuarioDokument8 SeitenTERRITORIUM Manual de UsuarioJohn AlFonsoNoch keine Bewertungen
- HOJA DE VIDA MilenaDokument6 SeitenHOJA DE VIDA MilenaCarina GarzonNoch keine Bewertungen
- Manual de Informatica Sin Servidor de Azure PDFDokument393 SeitenManual de Informatica Sin Servidor de Azure PDFOswaldo Bello100% (1)
- Sumadi Manual en Espa OlDokument12 SeitenSumadi Manual en Espa OlRenzo AquinoNoch keine Bewertungen
- Buscador Especializado de ArquitecturaDokument7 SeitenBuscador Especializado de ArquitecturaNixson Tejeda PumaNoch keine Bewertungen
- Flutter & IonicDokument17 SeitenFlutter & IonicHarold VallejoNoch keine Bewertungen
- COPIAmas Ejercicios SQLDokument17 SeitenCOPIAmas Ejercicios SQLDeisy DelaCruzNoch keine Bewertungen
- ISO DiferenciasDokument2 SeitenISO DiferenciasFrancisco Sampedro GilerNoch keine Bewertungen
- Ejercicio - Base de Datos AccessDokument32 SeitenEjercicio - Base de Datos AccessJosue Lagos50% (4)
- Sistema SiltraDokument39 SeitenSistema SiltraMaribel MarotoNoch keine Bewertungen
- Introduccion A La Tecnologia Digital Ii PDFDokument5 SeitenIntroduccion A La Tecnologia Digital Ii PDFCarlos PinedaNoch keine Bewertungen
- Formas NormalesDokument6 SeitenFormas NormalesJulio Lopez-NunezNoch keine Bewertungen
- Examen de Práctica de Cloud Engineer PDFDokument23 SeitenExamen de Práctica de Cloud Engineer PDFCRISTIAN100% (1)
- El Software y La Ingeniería de SoftwareDokument5 SeitenEl Software y La Ingeniería de SoftwareManuel LopezNoch keine Bewertungen
- BBDD Lenguaje DMLDokument86 SeitenBBDD Lenguaje DMLcarmenNoch keine Bewertungen