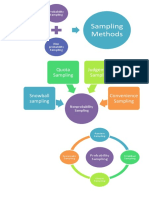
Das könnte Ihnen auch gefallen
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignVon EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNoch keine Bewertungen
- What Is Hypothesis TestingDokument46 SeitenWhat Is Hypothesis Testingmuliawan firdaus100% (1)
- Type-I and Type-II Errors in StatisticsDokument3 SeitenType-I and Type-II Errors in StatisticsImtiyaz AhmadNoch keine Bewertungen
- Sample Size DeterminationDokument25 SeitenSample Size DeterminationAvanti ChinteNoch keine Bewertungen
- Hypothesis TestingDokument180 SeitenHypothesis Testingrns116Noch keine Bewertungen
- Measuement and ScalingDokument31 SeitenMeasuement and Scalingagga1111Noch keine Bewertungen
- Type I and II ErrorsDokument11 SeitenType I and II ErrorsPratik PachaniNoch keine Bewertungen
- Hypothesis Testing and Errors in Hypothesis: Dr. Abdur RasheedDokument29 SeitenHypothesis Testing and Errors in Hypothesis: Dr. Abdur RasheedSafi SheikhNoch keine Bewertungen
- Measurement and Scaling Fundamentals, Comparative and Non Comparative ScalingDokument28 SeitenMeasurement and Scaling Fundamentals, Comparative and Non Comparative ScalingSavya JaiswalNoch keine Bewertungen
- Introduction of Testing of Hypothesis NotesDokument4 SeitenIntroduction of Testing of Hypothesis NotesThammana Nishithareddy100% (1)
- IKM - Sample Size Calculation in Epid Study PDFDokument7 SeitenIKM - Sample Size Calculation in Epid Study PDFcindyNoch keine Bewertungen
- Measurement and Scaling: UNIT:03Dokument36 SeitenMeasurement and Scaling: UNIT:03Nishant JoshiNoch keine Bewertungen
- Type I and Type II Errors PDFDokument5 SeitenType I and Type II Errors PDFGulfam AnsariNoch keine Bewertungen
- Tests of HypothesisDokument23 SeitenTests of HypothesisHazel PapagayoNoch keine Bewertungen
- Non Parametric GuideDokument5 SeitenNon Parametric GuideEnrico_LariosNoch keine Bewertungen
- Example For Questions QM AnswersDokument5 SeitenExample For Questions QM AnswersempirechocoNoch keine Bewertungen
- Tests of Significance and Measures of AssociationDokument21 SeitenTests of Significance and Measures of Associationanandan777supmNoch keine Bewertungen
- Determination of Sample SizeDokument19 SeitenDetermination of Sample Sizesanchi rajputNoch keine Bewertungen
- Ch7. Hypothesis TestingDokument86 SeitenCh7. Hypothesis TestingKhongmuon Noi100% (1)
- # RESEARCH METHODOLOGY Review On Comfirmatory Factor AnalysisDokument22 Seiten# RESEARCH METHODOLOGY Review On Comfirmatory Factor AnalysisMintiNoch keine Bewertungen
- Multiple Regression AnalysisDokument77 SeitenMultiple Regression Analysishayati5823Noch keine Bewertungen
- Chap4 Normality (Data Analysis) FVDokument72 SeitenChap4 Normality (Data Analysis) FVryad fki100% (1)
- An Introduction To Exploratory Factor AnalysisDokument6 SeitenAn Introduction To Exploratory Factor AnalysisAJayNoch keine Bewertungen
- Sampling: Business Research MethodologiesDokument21 SeitenSampling: Business Research MethodologiesJames DavisNoch keine Bewertungen
- All About Statistical Significance and TestingDokument15 SeitenAll About Statistical Significance and TestingSherwan R ShalNoch keine Bewertungen
- Analysing Quantitative DataDokument33 SeitenAnalysing Quantitative DataSumayyah ArslanNoch keine Bewertungen
- Inferential StatisticsDokument23 SeitenInferential StatisticsAki StephyNoch keine Bewertungen
- Test of SignificanceDokument22 SeitenTest of SignificanceKathiravan GopalanNoch keine Bewertungen
- Paper - 3Dokument9 SeitenPaper - 3Mamatha ShettyNoch keine Bewertungen
- Chapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Dokument91 SeitenChapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Sahib Ullah MukhlisNoch keine Bewertungen
- Non Parametric TestDokument16 SeitenNon Parametric TestVIKAS DOGRA100% (1)
- Tests of HypothesisDokument16 SeitenTests of HypothesisDilip YadavNoch keine Bewertungen
- Q2 L3 HypothesisDokument16 SeitenQ2 L3 HypothesisKd VonnNoch keine Bewertungen
- Statistics and Freq DistributionDokument35 SeitenStatistics and Freq DistributionMuhammad UsmanNoch keine Bewertungen
- LESSON 2 Introduction To Statistics ContinuationDokument32 SeitenLESSON 2 Introduction To Statistics ContinuationJhay Anne Pearl Menor100% (1)
- Chapter 5 Indicators and VariablesDokument24 SeitenChapter 5 Indicators and Variablestemesgen yohannesNoch keine Bewertungen
- Tabu Ran NormalDokument14 SeitenTabu Ran NormalSylvia100% (1)
- Formulating Research ProblemDokument20 SeitenFormulating Research ProblemPumla Sohe100% (1)
- Testing For Normality Using SPSS PDFDokument12 SeitenTesting For Normality Using SPSS PDFΧρήστος Ντάνης100% (1)
- Regression Analysis ProjectDokument4 SeitenRegression Analysis ProjectAsif. MahamudNoch keine Bewertungen
- Chapter 1 - Data CollectionDokument7 SeitenChapter 1 - Data CollectionRay AdamNoch keine Bewertungen
- Chapter 9 Introduction To The T StatisticDokument32 SeitenChapter 9 Introduction To The T StatisticdeNoch keine Bewertungen
- Experiment ResearchDokument13 SeitenExperiment ResearchmazorodzesNoch keine Bewertungen
- Manova and MancovaDokument10 SeitenManova and Mancovakinhai_seeNoch keine Bewertungen
- Chapter 7:sampling and Sampling DistributionsDokument50 SeitenChapter 7:sampling and Sampling DistributionsThe Tun 91Noch keine Bewertungen
- Multivariate Analysis of VarianceDokument29 SeitenMultivariate Analysis of VarianceAC BalioNoch keine Bewertungen
- Two-Way AnovaDokument19 SeitenTwo-Way AnovaidriszakariaNoch keine Bewertungen
- Parametric Statistic Nonparametric Statistic: AnswerDokument2 SeitenParametric Statistic Nonparametric Statistic: Answerribka62Noch keine Bewertungen
- Chi Square Test FinalDokument40 SeitenChi Square Test FinalIndu SinghNoch keine Bewertungen
- Likert ScaleDokument2 SeitenLikert ScaleIvani KatalNoch keine Bewertungen
- Parametric Vs Non-ParametricDokument2 SeitenParametric Vs Non-ParametricJovi Tariga LayasanNoch keine Bewertungen
- ARCH ModelDokument26 SeitenARCH ModelAnish S.MenonNoch keine Bewertungen
- Association and CausationDokument60 SeitenAssociation and Causationsehar_bashirNoch keine Bewertungen
- Data Analysis PDFDokument65 SeitenData Analysis PDFYaronBabaNoch keine Bewertungen
- Research Methodology 22Dokument28 SeitenResearch Methodology 22Ahmed MalikNoch keine Bewertungen
- Session 7 - Multivariate Data AnalysisDokument28 SeitenSession 7 - Multivariate Data AnalysisTrinh Anh PhongNoch keine Bewertungen
- Assignment 1Dokument3 SeitenAssignment 1Deepak DuggadNoch keine Bewertungen
- Bias and Confounding: Nayana FernandoDokument31 SeitenBias and Confounding: Nayana FernandoanojNoch keine Bewertungen
- Introduction to Statistics Through Resampling Methods and RVon EverandIntroduction to Statistics Through Resampling Methods and RNoch keine Bewertungen
- 4th Long Test 1Dokument2 Seiten4th Long Test 1Shanna Basallo AlentonNoch keine Bewertungen
- 4th Problem Set 3Dokument2 Seiten4th Problem Set 3Shanna Basallo AlentonNoch keine Bewertungen
- Making A Poster Rubric 1Dokument1 SeiteMaking A Poster Rubric 1Shanna Basallo AlentonNoch keine Bewertungen
- 3.3 Slopes of LinesDokument9 Seiten3.3 Slopes of LinesShanna Basallo AlentonNoch keine Bewertungen
- 4th Problem Set 1Dokument1 Seite4th Problem Set 1Shanna Basallo AlentonNoch keine Bewertungen
- 4th Problem Set 2Dokument2 Seiten4th Problem Set 2Shanna Basallo AlentonNoch keine Bewertungen
- Corrected SLK3 StatisticsandProbability Week7 8Dokument16 SeitenCorrected SLK3 StatisticsandProbability Week7 8Shanna Basallo AlentonNoch keine Bewertungen
- Answer Key SLK - 2 Week 7 General Mathematics Shs Activity 4 - Answers May Vary EvaluationDokument1 SeiteAnswer Key SLK - 2 Week 7 General Mathematics Shs Activity 4 - Answers May Vary EvaluationShanna Basallo AlentonNoch keine Bewertungen
- Second Periodic Examination in Math Problem Solving: Main Campus - Level 11Dokument6 SeitenSecond Periodic Examination in Math Problem Solving: Main Campus - Level 11Shanna Basallo AlentonNoch keine Bewertungen
- Third Periodic Examination in Math Problem Solving: Main Campus - Level 12Dokument9 SeitenThird Periodic Examination in Math Problem Solving: Main Campus - Level 12Shanna Basallo AlentonNoch keine Bewertungen
- Second Periodic Examination in Math Problem Solving: Main Campus - Level 12Dokument5 SeitenSecond Periodic Examination in Math Problem Solving: Main Campus - Level 12Shanna Basallo AlentonNoch keine Bewertungen
- Second Periodic Examination in Math Problem Solving: Main Campus - Level 9Dokument6 SeitenSecond Periodic Examination in Math Problem Solving: Main Campus - Level 9Shanna Basallo AlentonNoch keine Bewertungen
- Second Periodic Examination in Math Problem Solving: Main Campus - Level 10Dokument6 SeitenSecond Periodic Examination in Math Problem Solving: Main Campus - Level 10Shanna Basallo AlentonNoch keine Bewertungen
- Addition Subtraction: The Sum of Put Together Increased Plus More Than The Total of SummationDokument2 SeitenAddition Subtraction: The Sum of Put Together Increased Plus More Than The Total of SummationShanna Basallo AlentonNoch keine Bewertungen
- SESSION Guide. HERMOSODokument1 SeiteSESSION Guide. HERMOSOShanna Basallo AlentonNoch keine Bewertungen
- Cite at Least 2 Advantages and Disadvantages of The Following Sampling Techniques. Sampling Techniques Advantages DisadvantagesDokument2 SeitenCite at Least 2 Advantages and Disadvantages of The Following Sampling Techniques. Sampling Techniques Advantages DisadvantagesShanna Basallo AlentonNoch keine Bewertungen
- FunctionDokument1 SeiteFunctionShanna Basallo AlentonNoch keine Bewertungen
- 2011statistics h2Dokument1 Seite2011statistics h2Shanna Basallo AlentonNoch keine Bewertungen
- Approval SheetDokument3 SeitenApproval SheetShanna Basallo AlentonNoch keine Bewertungen
- Addition Subtraction: The Sum of Put Together Increased Plus More Than The Total of SummationDokument2 SeitenAddition Subtraction: The Sum of Put Together Increased Plus More Than The Total of SummationShanna Basallo AlentonNoch keine Bewertungen
- Pythagorean TheoremDokument1 SeitePythagorean TheoremShanna Basallo AlentonNoch keine Bewertungen
- Sample Program Completion ReportDokument4 SeitenSample Program Completion ReportShanna Basallo Alenton100% (5)
- Final Training Matrix MathDokument9 SeitenFinal Training Matrix MathShanna Basallo AlentonNoch keine Bewertungen
- Conceptual and Theoretical FrameworkDokument2 SeitenConceptual and Theoretical FrameworkShanna Basallo AlentonNoch keine Bewertungen
- Oral DefenseDokument23 SeitenOral DefenseShanna Basallo AlentonNoch keine Bewertungen
- Oral DefenseDokument23 SeitenOral DefenseShanna Basallo AlentonNoch keine Bewertungen
- Midterm Exam With AnswersDokument11 SeitenMidterm Exam With AnswersShanna Basallo AlentonNoch keine Bewertungen
- JerutsDokument7 SeitenJerutsShanna Basallo AlentonNoch keine Bewertungen
- Final ResearchDokument27 SeitenFinal ResearchShanna Basallo Alenton100% (2)
- Stat and Prob Q4 Week 3 Module 11 Alexander Randy EstradaDokument21 SeitenStat and Prob Q4 Week 3 Module 11 Alexander Randy Estradagabezarate071Noch keine Bewertungen
- Assignments-Mba Sem-Iii: Subject Code: MB0034Dokument25 SeitenAssignments-Mba Sem-Iii: Subject Code: MB0034Mithesh KumarNoch keine Bewertungen
- Simplilearn - Customer-Service-Requests-Analysis - Ipynb - ColaboratoryDokument15 SeitenSimplilearn - Customer-Service-Requests-Analysis - Ipynb - Colaboratoryritwij maunasNoch keine Bewertungen
- Unit 3 Simple Correlation and Regression Analysis1Dokument16 SeitenUnit 3 Simple Correlation and Regression Analysis1Rhea MirchandaniNoch keine Bewertungen
- Quadrat Analysis PDFDokument4 SeitenQuadrat Analysis PDFjoyNoch keine Bewertungen
- Cosumer Survey Report On Tapal TeaDokument9 SeitenCosumer Survey Report On Tapal Teafaryal naseemNoch keine Bewertungen
- Assessing The Impact of School Rules and RegulatioDokument9 SeitenAssessing The Impact of School Rules and Regulatiocherry vhim f. lanuriasNoch keine Bewertungen
- Quantitative Research Qualitative ResearcDokument14 SeitenQuantitative Research Qualitative ResearcJude MetanteNoch keine Bewertungen
- Poe AnswersDokument78 SeitenPoe AnswersNguyen Xuan Nguyen100% (2)
- Exam (Q) Set ADokument13 SeitenExam (Q) Set Aflowerpot321100% (1)
- Ilorin Journal of Education Vol 25 August 2006Dokument101 SeitenIlorin Journal of Education Vol 25 August 2006Victor Oluwaseyi Olowonisi100% (1)
- Essentials of Statistics For The Behavioral Sciences Gravetter 8th Edition Solutions ManualDokument5 SeitenEssentials of Statistics For The Behavioral Sciences Gravetter 8th Edition Solutions ManualJeffBrandtboqdx100% (38)
- COMM121 UOW Final Exam - Autumn With Answers - SAMPLEDokument23 SeitenCOMM121 UOW Final Exam - Autumn With Answers - SAMPLERuben BábyNoch keine Bewertungen
- Tests of Significance Notes PDFDokument12 SeitenTests of Significance Notes PDFManish KNoch keine Bewertungen
- Stat 151 Assignment 5Dokument5 SeitenStat 151 Assignment 5P KaurNoch keine Bewertungen
- MR - ' T ' Test-Independent Sample and Paired SampleDokument26 SeitenMR - ' T ' Test-Independent Sample and Paired SamplePrem RajNoch keine Bewertungen
- BUS 302 Study MaterialDokument8 SeitenBUS 302 Study MaterialCadyMyersNoch keine Bewertungen
- Chi-Square Test For For Goodness-of-Fit: AnnouncementsDokument4 SeitenChi-Square Test For For Goodness-of-Fit: AnnouncementsNellson NichioustNoch keine Bewertungen
- Analysis and Interpretation of Employee Satisfaction.Dokument20 SeitenAnalysis and Interpretation of Employee Satisfaction.Ashutosh Sharma92% (12)
- Statprob Q4 Module 6Dokument17 SeitenStatprob Q4 Module 6Kelsey Gaile MaghanoyNoch keine Bewertungen
- Hypothesis TestingDokument12 SeitenHypothesis TestingJp Combis100% (1)
- Unit 1 SNM - New (Compatibility Mode) Solved Hypothesis Test PDFDokument50 SeitenUnit 1 SNM - New (Compatibility Mode) Solved Hypothesis Test PDFsanjeevlrNoch keine Bewertungen
- Sample Research Paper With Null HypothesisDokument5 SeitenSample Research Paper With Null Hypothesisvictoriathompsonaustin100% (2)
- TQM Adoption in BangladeshDokument18 SeitenTQM Adoption in BangladeshKule89Noch keine Bewertungen
- Statistical Interpretation of Data - : Guide ToDokument14 SeitenStatistical Interpretation of Data - : Guide TomuratNoch keine Bewertungen
- Statistics For OsceDokument77 SeitenStatistics For OsceArun GeorgeNoch keine Bewertungen
- Sta404 Chapter 08Dokument120 SeitenSta404 Chapter 08Ibnu IyarNoch keine Bewertungen
- SBF Group Assignment PDFDokument9 SeitenSBF Group Assignment PDFAi Tien TranNoch keine Bewertungen
- Statistics Economics - Test of HypothesisDokument20 SeitenStatistics Economics - Test of HypothesissamirNoch keine Bewertungen
- YUSI AssignmentModule6Dokument4 SeitenYUSI AssignmentModule6Reyne YusiNoch keine Bewertungen