Das könnte Ihnen auch gefallen
- Codigos Respuesta DIAN FEDokument32 SeitenCodigos Respuesta DIAN FEWilmer40% (15)
- El Kempis Del Enfermo 76230307Dokument1 SeiteEl Kempis Del Enfermo 76230307José Alberto FernándezNoch keine Bewertungen
- GUIA COMPLETO Practica Ataques Spoofing DoS InyeccionSQL SolucionesDokument334 SeitenGUIA COMPLETO Practica Ataques Spoofing DoS InyeccionSQL SolucionesjavNoch keine Bewertungen
- Autómatas de PilaDokument5 SeitenAutómatas de PilaLuis MedinaNoch keine Bewertungen
- Practica - Operaciones Basicas Sobre Windows y LinuxDokument9 SeitenPractica - Operaciones Basicas Sobre Windows y LinuxjoseluisgilNoch keine Bewertungen
- Sistema de ArchivosDokument17 SeitenSistema de ArchivosDaniela SanchezNoch keine Bewertungen
- La Memoria Real en Los Sistemas OperativosDokument4 SeitenLa Memoria Real en Los Sistemas OperativosDaniel GandolffiNoch keine Bewertungen
- ProgramacionDokument7 SeitenProgramacionLorraine Ledezma0% (1)
- Practica WiresharkDokument8 SeitenPractica WiresharkVictorNoch keine Bewertungen
- Memoria en Sistemas OperativosDokument18 SeitenMemoria en Sistemas OperativosJHON JAIRO BARRAGAN VEGANoch keine Bewertungen
- Comando PingDokument11 SeitenComando PingFernando Rodríguez CaroNoch keine Bewertungen
- Investigacion Unidad 1 Sistemas OperativoDokument11 SeitenInvestigacion Unidad 1 Sistemas OperativoHumberto Rodriguez CambranisNoch keine Bewertungen
- Informe NmapDokument5 SeitenInforme NmapYeison IbarguenNoch keine Bewertungen
- Etiquetas de Movimiento en HTMLDokument7 SeitenEtiquetas de Movimiento en HTMLLuis Enrique HernandezNoch keine Bewertungen
- Arquitectura de SoftwareDokument8 SeitenArquitectura de SoftwareDenisee Rodriguez GuerreroNoch keine Bewertungen
- Como Usar NetsatDokument3 SeitenComo Usar NetsatRicardo Zevallos CruzNoch keine Bewertungen
- Arquitectura de Software Informe Final de FinalesDokument44 SeitenArquitectura de Software Informe Final de FinalesAngel O.P.Noch keine Bewertungen
- Planificación de Procesos en Sistemas OperativosDokument4 SeitenPlanificación de Procesos en Sistemas OperativosYANELI GAITANNoch keine Bewertungen
- Joins en SQLDokument9 SeitenJoins en SQLHashirama SenjuNoch keine Bewertungen
- Ejemplo Modelo Vista ControladorDokument31 SeitenEjemplo Modelo Vista Controladorsantiago_pérez_51Noch keine Bewertungen
- Sub Consultas Oracle 2008ultima ProcedimientosDokument96 SeitenSub Consultas Oracle 2008ultima ProcedimientosFrank CayetanoNoch keine Bewertungen
- Trabajo Grupal#1 AutómatasDokument6 SeitenTrabajo Grupal#1 AutómatasAndrésArmandoJaramilloMontañoNoch keine Bewertungen
- Qué Es Un BlogDokument2 SeitenQué Es Un BlogBel IvettNoch keine Bewertungen
- Habilidades de Comunicación Oral Cap. 3Dokument19 SeitenHabilidades de Comunicación Oral Cap. 3carlos garzonNoch keine Bewertungen
- Actividad AA2 1 Fundamentarse Sobre Los Sistemas Manejadores de Bases de Datos 2Dokument22 SeitenActividad AA2 1 Fundamentarse Sobre Los Sistemas Manejadores de Bases de Datos 2JeissonNoch keine Bewertungen
- Proyecto de SoftwareDokument16 SeitenProyecto de SoftwareDiego Andres Susa GaviriaNoch keine Bewertungen
- Criterios de Seleccion de Metodologias de Desarrollo de SoftwareDokument6 SeitenCriterios de Seleccion de Metodologias de Desarrollo de SoftwareFernando David Tulumba TuestaNoch keine Bewertungen
- Procedimientos y Funciones (Oracle)Dokument8 SeitenProcedimientos y Funciones (Oracle)Miguel Leito LeoNoch keine Bewertungen
- Clase Vector y ArraylistDokument3 SeitenClase Vector y ArraylistCarlos EnriqueNoch keine Bewertungen
- Tipos de JoinDokument4 SeitenTipos de JoinLeyva RonaldNoch keine Bewertungen
- Tablas en HTMLDokument4 SeitenTablas en HTMLJesus Chilque LunaNoch keine Bewertungen
- Activiadad 1 (Juan David Rios Palomino)Dokument14 SeitenActiviadad 1 (Juan David Rios Palomino)Juan David RiosNoch keine Bewertungen
- Gestion de Procesos en Sistemas OperativosDokument4 SeitenGestion de Procesos en Sistemas OperativosLiliana PrettyNoch keine Bewertungen
- Sistemas Operativos. Gestion de ProcesosDokument6 SeitenSistemas Operativos. Gestion de ProcesosJuan ToNoch keine Bewertungen
- Instalacion de Kali Dentro de VirtualBoxDokument8 SeitenInstalacion de Kali Dentro de VirtualBoxingridamorNoch keine Bewertungen
- Diseño de SoftwareDokument18 SeitenDiseño de SoftwarecjavichNoch keine Bewertungen
- Pilasy FilasDokument13 SeitenPilasy Filasxx_angel_xxNoch keine Bewertungen
- Práctica de Laboratorio LinuxDokument10 SeitenPráctica de Laboratorio LinuxfrancdyNoch keine Bewertungen
- 3.4.2 Niveles de EjecuciónDokument2 Seiten3.4.2 Niveles de EjecuciónSamuelEuripidesLariosMendezNoch keine Bewertungen
- Evaluación 1 - Sistemas Operativos (2022-1)Dokument3 SeitenEvaluación 1 - Sistemas Operativos (2022-1)Victor JoséNoch keine Bewertungen
- INTERRUPCIONESDokument8 SeitenINTERRUPCIONESAna PanameñoNoch keine Bewertungen
- Practica 10Dokument25 SeitenPractica 10Tanni DiazNoch keine Bewertungen
- Sistemas Operativos 4.2Dokument7 SeitenSistemas Operativos 4.2Isaac ValdezNoch keine Bewertungen
- Creacion BD Oracle 11GDokument5 SeitenCreacion BD Oracle 11GMariana PalenciaNoch keine Bewertungen
- Tipos de Plataformas de Desarrollo en JavaDokument9 SeitenTipos de Plataformas de Desarrollo en JavaEric HenriquezNoch keine Bewertungen
- Qué Es La Memoria VirtualDokument9 SeitenQué Es La Memoria VirtualJosue GoyesNoch keine Bewertungen
- Ejemplo ANTLRDokument6 SeitenEjemplo ANTLRHumberto José MejiasNoch keine Bewertungen
- ControladoresDokument35 SeitenControladoresRay MartiNoch keine Bewertungen
- Comandos en LinuxDokument6 SeitenComandos en LinuxCarlos RiquelmeNoch keine Bewertungen
- Pilas y ColasDokument14 SeitenPilas y ColasNicolasNoch keine Bewertungen
- AutoEvaluación 1 Sistemas OperativosDokument3 SeitenAutoEvaluación 1 Sistemas OperativosbelenNoch keine Bewertungen
- Comparación de Los SGBD Mas UsadosDokument9 SeitenComparación de Los SGBD Mas UsadosAndré Jr SandovalNoch keine Bewertungen
- Introduccion A La Programacion PDFDokument163 SeitenIntroduccion A La Programacion PDFXimena Gonzalez MillaNoch keine Bewertungen
- Presentación-06-Colas y PilasDokument23 SeitenPresentación-06-Colas y PilasLuis Miguel Gómez CaldasNoch keine Bewertungen
- Unidad 1. Diseno de AlgoritmosDokument26 SeitenUnidad 1. Diseno de AlgoritmosRtworo ADNoch keine Bewertungen
- Estructura Del Sistema OperativoDokument2 SeitenEstructura Del Sistema OperativoCarlos HernandezNoch keine Bewertungen
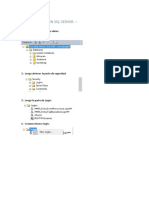
- Crear Usuario en SQL ServerDokument7 SeitenCrear Usuario en SQL ServerLuis RiveroNoch keine Bewertungen
- E2.Requisitos de SGBDDokument5 SeitenE2.Requisitos de SGBDGibran Barbosa RodriguezNoch keine Bewertungen
- LINUX - Más de 400 Comandos para GNU-Linux Que Deberías ConocerDokument27 SeitenLINUX - Más de 400 Comandos para GNU-Linux Que Deberías ConocerCesar ManriqueNoch keine Bewertungen
- Sistemas de Archivo Soportados Por LinuxDokument18 SeitenSistemas de Archivo Soportados Por LinuxCristian RiosNoch keine Bewertungen
- El Sistema de Ficheros Ext3Dokument14 SeitenEl Sistema de Ficheros Ext3Daniel Oswaldo Perez RamirezNoch keine Bewertungen
- 3-Sistemas de ArchivosDokument14 Seiten3-Sistemas de ArchivosjosebelandiaNoch keine Bewertungen
- Manual Servidor de Impresion Linux UbuntuDokument26 SeitenManual Servidor de Impresion Linux Ubuntugotita55100% (1)
- Manual de Uso de Marca para EFDokument13 SeitenManual de Uso de Marca para EFAlvaro PobleteNoch keine Bewertungen
- Informe PrácticaDokument39 SeitenInforme PrácticaAlvaro PobleteNoch keine Bewertungen
- Modelo OSI y Cableado Estructurado (Borrador)Dokument2 SeitenModelo OSI y Cableado Estructurado (Borrador)Alvaro PobleteNoch keine Bewertungen
- Certamen2 2010 2 TNS D PautaDokument4 SeitenCertamen2 2010 2 TNS D PautaAlvaro PobleteNoch keine Bewertungen
- Efectos CompizDokument6 SeitenEfectos CompizAlvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-23, S-1, MemoriasDokument7 SeitenArq de Comp, 2010-2, Sesión-23, S-1, MemoriasAlvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-17, S-1Dokument6 SeitenArq de Comp, 2010-2, Sesión-17, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-07, S-1Dokument4 SeitenArq de Comp, 2010-2, Sesión-07, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-22, S-1, MemoriasDokument6 SeitenArq de Comp, 2010-2, Sesión-22, S-1, MemoriasAlvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-19, S-1Dokument3 SeitenArq de Comp, 2010-2, Sesión-19, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-20, S-1Dokument6 SeitenArq de Comp, 2010-2, Sesión-20, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-21, S-1Dokument5 SeitenArq de Comp, 2010-2, Sesión-21, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-16, S-1Dokument8 SeitenArq de Comp, 2010-2, Sesión-16, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-18, S-1Dokument6 SeitenArq de Comp, 2010-2, Sesión-18, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-15, S-1Dokument6 SeitenArq de Comp, 2010-2, Sesión-15, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-14, S-1Dokument5 SeitenArq de Comp, 2010-2, Sesión-14, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-06, S-1Dokument4 SeitenArq de Comp, 2010-2, Sesión-06, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-13, S-1Dokument5 SeitenArq de Comp, 2010-2, Sesión-13, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-03, S-1Dokument3 SeitenArq de Comp, 2010-2, Sesión-03, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-04, S-1Dokument8 SeitenArq de Comp, 2010-2, Sesión-04, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-02, S-1Dokument6 SeitenArq de Comp, 2010-2, Sesión-02, S-1Alvaro PobleteNoch keine Bewertungen
- Arq de Comp, 2010-2, Sesión-01, S-1Dokument4 SeitenArq de Comp, 2010-2, Sesión-01, S-1Alvaro PobleteNoch keine Bewertungen
- Vectorizar de Una ImagenDokument26 SeitenVectorizar de Una ImagenroxanaNoch keine Bewertungen
- Manual de GoToMeeting Versión EscritorioDokument10 SeitenManual de GoToMeeting Versión EscritorioManuelJMNoch keine Bewertungen
- Contenedores SwingDokument6 SeitenContenedores SwingIsmael Adrián Díaz MirandaNoch keine Bewertungen
- Computer Hoy - Curso Básico de InformáticaDokument117 SeitenComputer Hoy - Curso Básico de InformáticaNereakoNoch keine Bewertungen
- AudioBox IOne-iTwo Manual de UsuarioDokument58 SeitenAudioBox IOne-iTwo Manual de UsuarioCarlos LaraNoch keine Bewertungen
- BPLDokument50 SeitenBPLErnesto Josue Mendoza Perez100% (1)
- Que Es Un ServicioDokument4 SeitenQue Es Un Serviciodulce aquinoNoch keine Bewertungen
- Lab Diagram A Real World Process PDFDokument2 SeitenLab Diagram A Real World Process PDFVictorJavierRiveraPalaciosNoch keine Bewertungen
- Qué Es Una Hoja de CálculoDokument6 SeitenQué Es Una Hoja de CálculoMa Gpe RiosNoch keine Bewertungen
- Proyecto de Desarrollo EducativoDokument4 SeitenProyecto de Desarrollo EducativoIsac Jorge100% (1)
- PLC MotoresDokument125 SeitenPLC MotoresGonzalo Bautista100% (1)
- Manual de Operación Del Torno CNCDokument6 SeitenManual de Operación Del Torno CNCJHON FRANCO TITO TORREJONNoch keine Bewertungen
- Informe de RequisitosdocxDokument19 SeitenInforme de Requisitosdocxromario duglas gonzalez monteroNoch keine Bewertungen
- MasoneilanDokument54 SeitenMasoneilanAlfredoNoch keine Bewertungen
- Anexo 1 - Insumos - Tarea 4Dokument22 SeitenAnexo 1 - Insumos - Tarea 4Juan Diego TiqueNoch keine Bewertungen
- Desarrollo Ofimatica para Blog Final PDFDokument38 SeitenDesarrollo Ofimatica para Blog Final PDFnataliacbetancurNoch keine Bewertungen
- Manual ArticulateDokument54 SeitenManual ArticulateDanilo BMNoch keine Bewertungen
- BioinDokument92 SeitenBioinJenny S-boomNoch keine Bewertungen
- BD 2cap5Dokument36 SeitenBD 2cap5Kady Gisselle GomézNoch keine Bewertungen
- Caso SalesforceDokument3 SeitenCaso SalesforceNicolas OñateNoch keine Bewertungen
- Actividad 2 InformaticaDokument2 SeitenActividad 2 InformaticaJuan FernandezNoch keine Bewertungen
- 1.3 Convergencia PDFDokument2 Seiten1.3 Convergencia PDFIvan AvilaNoch keine Bewertungen
- Diapositivas ISO 27001Dokument13 SeitenDiapositivas ISO 27001CinthiaGarrónNoch keine Bewertungen
- Examen Final Gil Delfin PDFDokument10 SeitenExamen Final Gil Delfin PDFJohn MontenegroNoch keine Bewertungen
- Tutoriales PIC - Control de Múltiples Servos Con Un Único TIMERDokument9 SeitenTutoriales PIC - Control de Múltiples Servos Con Un Único TIMERJaime Morera LuqueNoch keine Bewertungen
- 2 Capacitacion Modulo Word y PPT 2017Dokument8 Seiten2 Capacitacion Modulo Word y PPT 2017Anonymous NS65s3ckXNoch keine Bewertungen
- REJ603 3.0 PG 1MDB07220 YN ESaDokument20 SeitenREJ603 3.0 PG 1MDB07220 YN ESaLinder Torrico FloresNoch keine Bewertungen
- Grupo 3 - Planeamiento InformáticoDokument8 SeitenGrupo 3 - Planeamiento Informático01-IS-HU-JEAN POOL IBARRA PEREZNoch keine Bewertungen