Das könnte Ihnen auch gefallen
- Tarea DatawareHouseDokument2 SeitenTarea DatawareHouseGibran TurbiNoch keine Bewertungen
- Desarrolle Una Breve Descripción Sobre El Proceso ETL y Sus Principales CaracterísticasDokument2 SeitenDesarrolle Una Breve Descripción Sobre El Proceso ETL y Sus Principales CaracterísticasGibran TurbiNoch keine Bewertungen
- Rapid MinerDokument5 SeitenRapid MinerGibran TurbiNoch keine Bewertungen
- Proceso ETLDokument5 SeitenProceso ETLGibran TurbiNoch keine Bewertungen
- 0406B Trabajo Exposición e Investigación Grupo 1-2Dokument2 Seiten0406B Trabajo Exposición e Investigación Grupo 1-2Gibran TurbiNoch keine Bewertungen
- Auditoria - Trabajo Grupal PDFDokument10 SeitenAuditoria - Trabajo Grupal PDFGibran TurbiNoch keine Bewertungen
- Dilemas, Modulo 2 PDFDokument3 SeitenDilemas, Modulo 2 PDFGibran TurbiNoch keine Bewertungen
- Humanae Vitae, Una Encí - Clica ProféticaDokument8 SeitenHumanae Vitae, Una Encí - Clica ProféticaGibran TurbiNoch keine Bewertungen
- Practica Final de Programacion III Ciclo 2-2020 PDFDokument2 SeitenPractica Final de Programacion III Ciclo 2-2020 PDFGibran TurbiNoch keine Bewertungen
- Auditoria Informatica Tema 4 - PracticaDokument3 SeitenAuditoria Informatica Tema 4 - PracticaGibran TurbiNoch keine Bewertungen
- Principales Pruebas y Herramientas para Efectuar Una Auditoria InformaticaDokument7 SeitenPrincipales Pruebas y Herramientas para Efectuar Una Auditoria InformaticaGibran TurbiNoch keine Bewertungen
- Autenticidad e IdentidadDokument1 SeiteAutenticidad e IdentidadGibran TurbiNoch keine Bewertungen
- El Matrimonio (Script)Dokument1 SeiteEl Matrimonio (Script)Gibran TurbiNoch keine Bewertungen
- UNIDAD-7-Y-8. WuolahDokument7 SeitenUNIDAD-7-Y-8. WuolahPablo SánchezNoch keine Bewertungen
- Analisis - de-La-Ley-633Dokument4 SeitenAnalisis - de-La-Ley-633Yoan GalvezNoch keine Bewertungen
- El Circuito de Lealtad de Los ClientesDokument7 SeitenEl Circuito de Lealtad de Los ClientesJoeVezmoNoch keine Bewertungen
- Manual de Procedimientos - InnovaTecNM 2022Dokument27 SeitenManual de Procedimientos - InnovaTecNM 2022El Olivo InmueblesNoch keine Bewertungen
- La Jornada de TrabajoDokument9 SeitenLa Jornada de Trabajomatheline novoaNoch keine Bewertungen
- Baide Norma U1T1a2Dokument13 SeitenBaide Norma U1T1a2Norma BaideNoch keine Bewertungen
- ACTIVIDAD No 1 ENSAYO INVESTIGACION DE OPERACIONES Y MODELACIONDokument8 SeitenACTIVIDAD No 1 ENSAYO INVESTIGACION DE OPERACIONES Y MODELACIONDENNIS HERNANDEZNoch keine Bewertungen
- Ensayo Plataformas LogisticasDokument4 SeitenEnsayo Plataformas LogisticasLinaLlerenaNoch keine Bewertungen
- APRENDO WASAP (4) Escribimos Nuestro Diario Personal (3) CACDokument8 SeitenAPRENDO WASAP (4) Escribimos Nuestro Diario Personal (3) CACEDWIN JESUS FLORES AÑAÑOSNoch keine Bewertungen
- Noticias Del Valle Nro. 3Dokument12 SeitenNoticias Del Valle Nro. 3Dar MerNoch keine Bewertungen
- Codigo Agrupador de Cuentas Del Sat Nivel Codigo AgrupadorDokument108 SeitenCodigo Agrupador de Cuentas Del Sat Nivel Codigo AgrupadorIsay HuertaNoch keine Bewertungen
- Punto y Contrapunto, La Tecnologia y Los Intermediarios FinancierosDokument2 SeitenPunto y Contrapunto, La Tecnologia y Los Intermediarios FinancierosTomas MedinaNoch keine Bewertungen
- CLASE 6 Perfil ProfesionalDokument26 SeitenCLASE 6 Perfil ProfesionalMartha MurilloNoch keine Bewertungen
- Marlon - Contabilidad II - Tarea 2Dokument3 SeitenMarlon - Contabilidad II - Tarea 2Alexis Center100% (1)
- Productos Derivados de Las ArcillasDokument13 SeitenProductos Derivados de Las ArcillasAlejandro Caceres HaroNoch keine Bewertungen
- Silabo de Gestion de Cuencas HidrograficasDokument12 SeitenSilabo de Gestion de Cuencas HidrograficasCHUMBES VIVANCONoch keine Bewertungen
- Contrato de Auspicio o SponsorDokument3 SeitenContrato de Auspicio o SponsorJuan GallegosNoch keine Bewertungen
- Tarea6 Contabilidad 1Dokument5 SeitenTarea6 Contabilidad 1Adriany De JesúsNoch keine Bewertungen
- Organigramas E - BROKERDokument6 SeitenOrganigramas E - BROKERKatalina Urbano GuzmánNoch keine Bewertungen
- 58 Laboratorio Computación para IngenieríaDokument3 Seiten58 Laboratorio Computación para IngenieríaJose OmarNoch keine Bewertungen
- Trabajo Final Publicidad 2Dokument2 SeitenTrabajo Final Publicidad 2yamiletNoch keine Bewertungen
- Tarea #2 CuestionarioDokument6 SeitenTarea #2 CuestionarioEdwin VegaNoch keine Bewertungen
- CV MKDokument16 SeitenCV MKVaneza JamancaNoch keine Bewertungen
- El Cuadro de Mando IntegralDokument9 SeitenEl Cuadro de Mando Integraljulden perezNoch keine Bewertungen
- Banca - de Primer - NivelDokument16 SeitenBanca - de Primer - NivelViviana BurgosNoch keine Bewertungen
- Cuadro 3 Registro de Fugas Detectadas Sobre La Geomembrana - GeoelectricaDokument2 SeitenCuadro 3 Registro de Fugas Detectadas Sobre La Geomembrana - GeoelectricaEliarte CórdovaNoch keine Bewertungen
- Titulo 2 Que Ladrones de DocumentosDokument5 SeitenTitulo 2 Que Ladrones de DocumentosNadie NingunoNoch keine Bewertungen
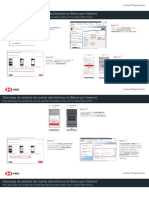
- Descarga Estados Cuenta PDFDokument3 SeitenDescarga Estados Cuenta PDFaatNoch keine Bewertungen
- INFORME UNIDAD III y UNIDAD IV ZOBEIDA (LEGISLACION FISCAL Y TRIBUTARIA) ANAIS CHACINDokument24 SeitenINFORME UNIDAD III y UNIDAD IV ZOBEIDA (LEGISLACION FISCAL Y TRIBUTARIA) ANAIS CHACINAnais ChacinNoch keine Bewertungen
- ) $t&+Zeu?'58"P : Información Del PeriodoDokument11 Seiten) $t&+Zeu?'58"P : Información Del PeriodoAlberto RocaNoch keine Bewertungen