Das könnte Ihnen auch gefallen
- Arduino Uno CNC ShieldDokument11 SeitenArduino Uno CNC ShieldMărian IoanNoch keine Bewertungen
- GDS-VFP Interview Guides July 9 2021Dokument6 SeitenGDS-VFP Interview Guides July 9 2021Manda ReemaNoch keine Bewertungen
- Data Cleaning: A Brief Guide ToDokument15 SeitenData Cleaning: A Brief Guide Topooja singhalNoch keine Bewertungen
- Digital Measurement: Analy&cs Workshop On How To Turn Data Into Ac&onable InsightsDokument84 SeitenDigital Measurement: Analy&cs Workshop On How To Turn Data Into Ac&onable Insightsapi-26225168Noch keine Bewertungen
- CRM Stands For Customer Relationship ManagementDokument8 SeitenCRM Stands For Customer Relationship ManagementRavindra GoyalNoch keine Bewertungen
- BANA6037-Data Visualization-18FS 001 and 003Dokument10 SeitenBANA6037-Data Visualization-18FS 001 and 003mahithaNoch keine Bewertungen
- Intelligent Food Recommendation System Using Machine LearningDokument4 SeitenIntelligent Food Recommendation System Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Forrester - The Current State of Marketing Measurement and OptimizationDokument17 SeitenForrester - The Current State of Marketing Measurement and OptimizationLadyboy Sissy ChristianeNoch keine Bewertungen
- Traditional Conjoint Analysis With ExcelDokument9 SeitenTraditional Conjoint Analysis With ExcelPierreNeganoNoch keine Bewertungen
- 385C Waw1-Up PDFDokument4 Seiten385C Waw1-Up PDFJUNA RUSANDI SNoch keine Bewertungen
- Computer Science ResourcesDokument4 SeitenComputer Science ResourcesadicikoNoch keine Bewertungen
- Draft JV Agreement (La Mesa Gardens Condominiums - Amparo Property)Dokument13 SeitenDraft JV Agreement (La Mesa Gardens Condominiums - Amparo Property)Patrick PenachosNoch keine Bewertungen
- Marketing AnalyticsDokument6 SeitenMarketing AnalyticsharshitNoch keine Bewertungen
- Sales Analysis of E-Commerce Websites Using Data MDokument6 SeitenSales Analysis of E-Commerce Websites Using Data MSang NguyễnNoch keine Bewertungen
- Statistics For Business Analysis: Learning ObjectivesDokument37 SeitenStatistics For Business Analysis: Learning ObjectivesShivani PandeyNoch keine Bewertungen
- Bigquery AnalyticsDokument2 SeitenBigquery AnalyticsShekhar SivaramanNoch keine Bewertungen
- 01 ASHOK CHARAN - The Marketing Analytics Practitioner's Guide - Vol. 01, Brand and Consumer (11oct2023)Dokument340 Seiten01 ASHOK CHARAN - The Marketing Analytics Practitioner's Guide - Vol. 01, Brand and Consumer (11oct2023)sjahrialfennieNoch keine Bewertungen
- Analytics CompendiumDokument41 SeitenAnalytics Compendiumshubham markadNoch keine Bewertungen
- Powerbi MaterialDokument30 SeitenPowerbi Materialanubha guptaNoch keine Bewertungen
- Data Analyst Interview QuestionsDokument12 SeitenData Analyst Interview QuestionsShubham MishraNoch keine Bewertungen
- Babe Ruth Saves BaseballDokument49 SeitenBabe Ruth Saves BaseballYijun PengNoch keine Bewertungen
- Predicting Customer Lifetime Value With "Buy Til You Die" Probabilistic Models in PythonDokument18 SeitenPredicting Customer Lifetime Value With "Buy Til You Die" Probabilistic Models in PythonFabio FrangiamoreNoch keine Bewertungen
- Research Paper LlamaDokument27 SeitenResearch Paper LlamaBlerim HasaNoch keine Bewertungen
- Data Analytics ProjectDokument9 SeitenData Analytics ProjectShubham SinghNoch keine Bewertungen
- Introduction To AI IBM (COURSERA)Dokument2 SeitenIntroduction To AI IBM (COURSERA)Ritika MondalNoch keine Bewertungen
- Prescriptive ANalyticsDokument39 SeitenPrescriptive ANalyticsjaiwarwick1Noch keine Bewertungen
- Marketing Mix Modeling 0.9 PDFDokument8 SeitenMarketing Mix Modeling 0.9 PDFPerumalla Pradeep Kumar100% (1)
- Customer Segmentation Using RFM Analysis: OverviewDokument11 SeitenCustomer Segmentation Using RFM Analysis: OverviewAlain R LugonesNoch keine Bewertungen
- Digital Analytics Individual Assignment - BHATT AlokDokument28 SeitenDigital Analytics Individual Assignment - BHATT AlokAlok BhattNoch keine Bewertungen
- DMIT - Midbrain - DMIT SoftwareDokument16 SeitenDMIT - Midbrain - DMIT SoftwarevinNoch keine Bewertungen
- My SQL For BeginnersDokument3 SeitenMy SQL For BeginnersPallavi SinghNoch keine Bewertungen
- Asterisk NowDokument82 SeitenAsterisk Nowkambojk100% (1)
- Data VisualizationDokument55 SeitenData VisualizationThành Cao ĐứcNoch keine Bewertungen
- Participants ListDokument13 SeitenParticipants Listmailway002Noch keine Bewertungen
- BigDataAnalyticsDokument36 SeitenBigDataAnalyticsdeepak1892100% (1)
- Maritta Koch-Weser, Scott Guggenheim - Social Development in The World Bank - Essays in Honor of Michael M. Cernea-Springer (2021)Dokument374 SeitenMaritta Koch-Weser, Scott Guggenheim - Social Development in The World Bank - Essays in Honor of Michael M. Cernea-Springer (2021)IacobNoch keine Bewertungen
- Market Mix ModelDokument34 SeitenMarket Mix Modelkarthik narayan0% (1)
- Ucc & BM of Osmania University (MBA)Dokument22 SeitenUcc & BM of Osmania University (MBA)ABDIRASAKNoch keine Bewertungen
- Marketing Management JUNE 2022Dokument12 SeitenMarketing Management JUNE 2022Rajni KumariNoch keine Bewertungen
- $100+ MILLION 5-8% / PRACTICE: Eliminated Risk Sap Erp/CrmDokument1 Seite$100+ MILLION 5-8% / PRACTICE: Eliminated Risk Sap Erp/CrmParvathi ChandramohanNoch keine Bewertungen
- Business IntelligenceDokument41 SeitenBusiness IntelligenceCarlo SerioNoch keine Bewertungen
- Programming With Python Coursework 2020: Supermarket Self-Checkout SystemDokument14 SeitenProgramming With Python Coursework 2020: Supermarket Self-Checkout SystemBorderBRENoch keine Bewertungen
- Data To Knowledge To Results Rev4Dokument21 SeitenData To Knowledge To Results Rev4Mark GalloNoch keine Bewertungen
- Business Analytics Prajwal Bhat HDokument4 SeitenBusiness Analytics Prajwal Bhat Hprajwalbhat50% (2)
- SalesDokument17 SeitenSalesPriyanka ManjrekarNoch keine Bewertungen
- Itm Lab: Assignment - 2Dokument10 SeitenItm Lab: Assignment - 2muktaNoch keine Bewertungen
- TablueDokument2 SeitenTabluedevender_nandre0% (1)
- Implications of Predictive AnalyticsDokument9 SeitenImplications of Predictive AnalyticsAMIT PANDEYNoch keine Bewertungen
- Semester: 3 Course Name: Marketing Analytics Course Code: 18JBS315 Number of Credits: 3 Number of Hours: 30Dokument4 SeitenSemester: 3 Course Name: Marketing Analytics Course Code: 18JBS315 Number of Credits: 3 Number of Hours: 30Lipson ThomasNoch keine Bewertungen
- Marketing Analytics: Putting Data Science and Machine Learning To WorkDokument2 SeitenMarketing Analytics: Putting Data Science and Machine Learning To Workjames ryerNoch keine Bewertungen
- Basic Business Analytics Using Excel, Chapter 01Dokument21 SeitenBasic Business Analytics Using Excel, Chapter 01ann camile maupayNoch keine Bewertungen
- EX - NO: 2A Chart in Spread SheetDokument8 SeitenEX - NO: 2A Chart in Spread SheetBalajiNoch keine Bewertungen
- CCW331 Business Analytics Material Unit I Type2Dokument43 SeitenCCW331 Business Analytics Material Unit I Type2ultra BNoch keine Bewertungen
- Assignment 02Dokument9 SeitenAssignment 02dilhaniNoch keine Bewertungen
- 2 Forecast AccuracyDokument26 Seiten2 Forecast Accuracynatalie clyde matesNoch keine Bewertungen
- 6 Different Ways To Compensate For Missing Values in A DatasetDokument6 Seiten6 Different Ways To Compensate For Missing Values in A DatasetichaNoch keine Bewertungen
- Prototype CRM ImplementationDokument3 SeitenPrototype CRM ImplementationGangadhar MamadapurNoch keine Bewertungen
- What Is Customer Lifetime Value?: Price DiscriminationDokument4 SeitenWhat Is Customer Lifetime Value?: Price DiscriminationRajan MishraNoch keine Bewertungen
- IBM Q1 Technical Marketing ASSET2 - Data Science Methodology-Best Practices For Successful Implementations Ov37176 PDFDokument6 SeitenIBM Q1 Technical Marketing ASSET2 - Data Science Methodology-Best Practices For Successful Implementations Ov37176 PDFxjackxNoch keine Bewertungen
- Uber HYD COE Business Analyst JD - Analytics & Data Science-1 PDFDokument3 SeitenUber HYD COE Business Analyst JD - Analytics & Data Science-1 PDFcherukuNoch keine Bewertungen
- Careers - Data Analytics Training - Internshala Trainings PDFDokument2 SeitenCareers - Data Analytics Training - Internshala Trainings PDFAbhilash BhatiNoch keine Bewertungen
- TSF GRIP Tasks PDFDokument32 SeitenTSF GRIP Tasks PDFGeorg PaulNoch keine Bewertungen
- Unit II-Database Design, Archiitecture - ModelDokument23 SeitenUnit II-Database Design, Archiitecture - ModelAditya ThakurNoch keine Bewertungen
- Principles of Data ScienceDokument3 SeitenPrinciples of Data ScienceKattieSmith45Noch keine Bewertungen
- Unit IV - Database NormalizationDokument31 SeitenUnit IV - Database NormalizationAditya ThakurNoch keine Bewertungen
- Marketing Mix Modelling A Complete Guide - 2020 EditionVon EverandMarketing Mix Modelling A Complete Guide - 2020 EditionNoch keine Bewertungen
- EAC Inquiry SDCDokument9 SeitenEAC Inquiry SDCThe Sustainable Development Commission (UK, 2000-2011)Noch keine Bewertungen
- Data Sheet Eldar Void SpinnerDokument1 SeiteData Sheet Eldar Void SpinnerAlex PolleyNoch keine Bewertungen
- NABARD R&D Seminar FormatDokument7 SeitenNABARD R&D Seminar FormatAnupam G. RatheeNoch keine Bewertungen
- Shelly e CommerceDokument13 SeitenShelly e CommerceVarun_Arya_8382Noch keine Bewertungen
- Stone As A Building Material: LateriteDokument13 SeitenStone As A Building Material: LateriteSatyajeet ChavanNoch keine Bewertungen
- RMC 102-2017 HighlightsDokument3 SeitenRMC 102-2017 HighlightsmmeeeowwNoch keine Bewertungen
- Epreuve Anglais EG@2022Dokument12 SeitenEpreuve Anglais EG@2022Tresor SokoudjouNoch keine Bewertungen
- Water Pump 250 Hrs Service No Unit: Date: HM: ShiftDokument8 SeitenWater Pump 250 Hrs Service No Unit: Date: HM: ShiftTLK ChannelNoch keine Bewertungen
- Midi Pro Adapter ManualDokument34 SeitenMidi Pro Adapter ManualUli ZukowskiNoch keine Bewertungen
- Regional Manager Business Development in Atlanta GA Resume Jay GriffithDokument2 SeitenRegional Manager Business Development in Atlanta GA Resume Jay GriffithJayGriffithNoch keine Bewertungen
- Komunikasi Sebagai Piranti Kebijakan Bi: Materi SESMABI Mei 2020Dokument26 SeitenKomunikasi Sebagai Piranti Kebijakan Bi: Materi SESMABI Mei 2020syahriniNoch keine Bewertungen
- Introduction - Livspace - RenoDokument12 SeitenIntroduction - Livspace - RenoMêghnâ BîswâsNoch keine Bewertungen
- Semi Detailed Lesson PlanDokument2 SeitenSemi Detailed Lesson PlanJean-jean Dela Cruz CamatNoch keine Bewertungen
- HSCC SRH 0705 PDFDokument1 SeiteHSCC SRH 0705 PDFBhawna KapoorNoch keine Bewertungen
- UM-140-D00221-07 SeaTrac Developer Guide (Firmware v2.4)Dokument154 SeitenUM-140-D00221-07 SeaTrac Developer Guide (Firmware v2.4)Antony Jacob AshishNoch keine Bewertungen
- The Privatization PolicyDokument14 SeitenThe Privatization PolicyRIBLEN EDORINANoch keine Bewertungen
- Cam 18 Test 3 ListeningDokument6 SeitenCam 18 Test 3 ListeningKhắc Trung NguyễnNoch keine Bewertungen
- Maritime Academy of Asia and The Pacific-Kamaya Point Department of AcademicsDokument7 SeitenMaritime Academy of Asia and The Pacific-Kamaya Point Department of Academicsaki sintaNoch keine Bewertungen
- MEd TG G07 EN 04-Oct Digital PDFDokument94 SeitenMEd TG G07 EN 04-Oct Digital PDFMadhan GanesanNoch keine Bewertungen
- Case Study Single Sign On Solution Implementation Software Luxoft For Ping IdentityDokument5 SeitenCase Study Single Sign On Solution Implementation Software Luxoft For Ping IdentityluxoftNoch keine Bewertungen
- Decision Trees For Management of An Avulsed Permanent ToothDokument2 SeitenDecision Trees For Management of An Avulsed Permanent ToothAbhi ThakkarNoch keine Bewertungen
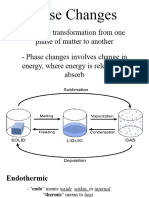
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDokument19 SeitenGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaNoch keine Bewertungen