Das könnte Ihnen auch gefallen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Cyber SecurityDokument15 SeitenCyber SecurityStephanie DilloNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- CBSE Class 9 Computer Applications 2021-22Dokument4 SeitenCBSE Class 9 Computer Applications 2021-22Pushpa Jha0% (1)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- HDX Video Movie English PDFDokument82 SeitenHDX Video Movie English PDFCesar Augusto CalderonNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Test in Ms PowerpointDokument1 SeiteTest in Ms PowerpointMark Paul AlvarezNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- A6V11763673 - C400 Climatix Controllers Basic Documentation - enDokument44 SeitenA6V11763673 - C400 Climatix Controllers Basic Documentation - enHuy Dao QuangNoch keine Bewertungen
- SG350-28MP Datasheet: Get A QuoteDokument3 SeitenSG350-28MP Datasheet: Get A QuoteKali LinuxNoch keine Bewertungen
- Proban - TM - Manual de Probabilidade - VeritasDokument128 SeitenProban - TM - Manual de Probabilidade - VeritasEverson VieiraNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Project ReportDokument6 SeitenProject ReportMouneeswaran A INoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- 0417 Information and Communication TechnologyDokument8 Seiten0417 Information and Communication TechnologyilovefettuccineNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Tutorial On Extracting The Models.: October 2015 360 PostsDokument4 SeitenTutorial On Extracting The Models.: October 2015 360 PostsAlucardw32Noch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
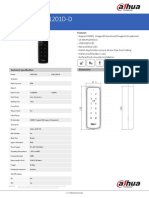
- ASR1201D ASR1201D-D: Slim Water-Proof RFID ReaderDokument1 SeiteASR1201D ASR1201D-D: Slim Water-Proof RFID ReaderSTEPHANE LAIRNoch keine Bewertungen
- Cyber Security Checklist: Overarching Best Practices Network SecurityDokument1 SeiteCyber Security Checklist: Overarching Best Practices Network SecurityAkram AlqadasiNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Informatica ETL Naming ConventionsDokument2 SeitenInformatica ETL Naming Conventionsnagababu10679Noch keine Bewertungen
- 11 Example of References Using The Numeric SystemDokument2 Seiten11 Example of References Using The Numeric SystemHepisipa MatekitongaNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- On Research of Big Data Ecosystem 2Dokument22 SeitenOn Research of Big Data Ecosystem 2Krupa PatelNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Zscaler Digital Transformation Admin Study GuideDokument149 SeitenZscaler Digital Transformation Admin Study GuidesrimanikantainaparthiNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Being Digital at The Core: Finacle Core Banking SolutionDokument24 SeitenBeing Digital at The Core: Finacle Core Banking SolutionAhaisibwe GeofreyNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- CMPG 111 Pec - 2024Dokument7 SeitenCMPG 111 Pec - 2024Donovan DyeNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- DGS-1510 Series CLI Reference Guide v1.20 (W)Dokument747 SeitenDGS-1510 Series CLI Reference Guide v1.20 (W)Rafael BustamanteNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Amazon Web Services: ProjectDokument13 SeitenAmazon Web Services: ProjectAneelaMalikNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Practicle Java Sem 1 - Vikalp SharmaDokument3 SeitenPracticle Java Sem 1 - Vikalp Sharmavs3465Noch keine Bewertungen
- JAVA (QuestionBank)Dokument22 SeitenJAVA (QuestionBank)Sahil ChauahanNoch keine Bewertungen
- LESSON 4 - Imaging and Design For Online EnvironmentDokument26 SeitenLESSON 4 - Imaging and Design For Online Environmentjudith c. lorica100% (1)
- Tms320F2806X Piccolo™ Mcus Silicon Revisions B, A, 0Dokument36 SeitenTms320F2806X Piccolo™ Mcus Silicon Revisions B, A, 0Vaibhav AgarwalNoch keine Bewertungen
- 10.4 Custom ExceptionsDokument4 Seiten10.4 Custom Exceptionsaftab alamNoch keine Bewertungen
- Sandipan Saha Ece 6th Sem 10600321021 Ec604c Ca2Dokument15 SeitenSandipan Saha Ece 6th Sem 10600321021 Ec604c Ca2Aryadeep ChakrabortyNoch keine Bewertungen
- Samson 7 Configuracion 61-65Dokument96 SeitenSamson 7 Configuracion 61-65Paul Ramos CarcaustoNoch keine Bewertungen
- Maxwell Flitton - Rust Web Programming - A Hands-On Guide To Developing, Packaging, and Deploying Fully Functional Rust Web Applications,-Packt Publishing (2023)Dokument666 SeitenMaxwell Flitton - Rust Web Programming - A Hands-On Guide To Developing, Packaging, and Deploying Fully Functional Rust Web Applications,-Packt Publishing (2023)coder seekerNoch keine Bewertungen
- Requirement Engineering For Web Applications: Dr. Sohaib AhmedDokument38 SeitenRequirement Engineering For Web Applications: Dr. Sohaib AhmedShumaila KhanNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Indian Toners 2019 PDFDokument157 SeitenIndian Toners 2019 PDFPuneet367Noch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)