Das könnte Ihnen auch gefallen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Understanding Deep Image Representations by Inverting Them PDFDokument9 SeitenUnderstanding Deep Image Representations by Inverting Them PDFgousesyedNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Learning Deep Features For Discriminative Localization - SuppDokument9 SeitenLearning Deep Features For Discriminative Localization - SuppgousesyedNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- ImageNet Large Scale Visual Recognition Challenge PDFDokument43 SeitenImageNet Large Scale Visual Recognition Challenge PDFgousesyedNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Grad-CAM: Visual Explanations From Deep Networks Via Gradient-Based LocalizationDokument24 SeitenGrad-CAM: Visual Explanations From Deep Networks Via Gradient-Based LocalizationgousesyedNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Adaptive Deconvolutional Networks For Mid and High Level Feature LearningDokument8 SeitenAdaptive Deconvolutional Networks For Mid and High Level Feature LearninggousesyedNoch keine Bewertungen
- DS ANT TNA352A33rDokument3 SeitenDS ANT TNA352A33rEdelNoch keine Bewertungen
- Business Strategy With Exploratory & Exploitative Innovation - The Analytics Role From SMAC TechnologyDokument12 SeitenBusiness Strategy With Exploratory & Exploitative Innovation - The Analytics Role From SMAC TechnologyAmit DahiyaNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- ES22-ES37 Operation Manual 003Dokument39 SeitenES22-ES37 Operation Manual 003andy habibi100% (1)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Tnms SNMP Nbi - Operation GuideDokument90 SeitenTnms SNMP Nbi - Operation GuideAdrian FlorensaNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Final-Front Pages-2011 PME CodeDokument10 SeitenFinal-Front Pages-2011 PME CodeJoseph R. F. DavidNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Basic of SoundDokument54 SeitenBasic of SoundRoslina Jaafar75% (4)
- Blazing Text Navigating The Dimensional LabyrinthDokument91 SeitenBlazing Text Navigating The Dimensional LabyrinthsurendersaraNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- 9814663735Dokument367 Seiten9814663735scribdermanNoch keine Bewertungen
- Bealls List of Predatory PublishersDokument38 SeitenBealls List of Predatory PublishersRandy The FoxNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- GNC Rfid PDFDokument66 SeitenGNC Rfid PDFFederico Manuel Pujol100% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Protocol Padlet - Online Projects 2020Dokument2 SeitenProtocol Padlet - Online Projects 2020api-284373535Noch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Medium-Voltage Surge Arresters US - Catalog HP-AR 25 PDFDokument47 SeitenMedium-Voltage Surge Arresters US - Catalog HP-AR 25 PDFfrostssssNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
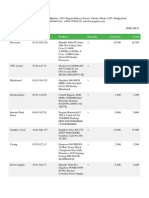
- Category ID Product Quantity Unit Price TotalDokument2 SeitenCategory ID Product Quantity Unit Price TotalMohammad RumanNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Design, Development and Characterization of Resistive Arm Based Planar and Conformal Metasurfaces For RCS ReductionDokument15 SeitenDesign, Development and Characterization of Resistive Arm Based Planar and Conformal Metasurfaces For RCS Reductionfereshteh samadiNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- PDG - 2017 Latest (New Dryer)Dokument4 SeitenPDG - 2017 Latest (New Dryer)mohd fadhilNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Download, Upload, Delete Files From FTP Server Using C#Dokument9 SeitenDownload, Upload, Delete Files From FTP Server Using C#Henrique PereiraNoch keine Bewertungen
- BIO PROJECT MOBILE RADIATION 2 (Official Release)Dokument28 SeitenBIO PROJECT MOBILE RADIATION 2 (Official Release)Sarosij Sen Sarma67% (3)
- Dec - 2018 - NEO - Siren Output OptionsDokument4 SeitenDec - 2018 - NEO - Siren Output OptionsAndre EinsteinNoch keine Bewertungen
- FTTX Technology ReportDokument48 SeitenFTTX Technology ReportanadiguptaNoch keine Bewertungen
- Atp Api R12Dokument16 SeitenAtp Api R12prasad_jampanaNoch keine Bewertungen
- Catalogo Mass Parts - Accesorios Final - 2017Dokument50 SeitenCatalogo Mass Parts - Accesorios Final - 2017Carlos Reconco100% (1)
- Test Chapter 13Dokument14 SeitenTest Chapter 13Rildo Reis TanNoch keine Bewertungen
- Antec 1200 ManualDokument11 SeitenAntec 1200 ManualmhtradeNoch keine Bewertungen
- Silicon Chip 2009-01 PDFDokument78 SeitenSilicon Chip 2009-01 PDFhmdv100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- 0in CDC UG PDFDokument479 Seiten0in CDC UG PDFRamakrishnaRao Soogoori0% (1)
- SW2000 DSDokument4 SeitenSW2000 DSargaNoch keine Bewertungen
- Surveying IIIDokument7 SeitenSurveying IIIShaik Jhoir100% (1)
- Selenium ToolDokument24 SeitenSelenium ToolSayali NagarkarNoch keine Bewertungen
- MAcro ResumeDokument5 SeitenMAcro ResumehumayunNoch keine Bewertungen
- PLC Based Elevator Control System-1Dokument26 SeitenPLC Based Elevator Control System-1Belete GetachewNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)