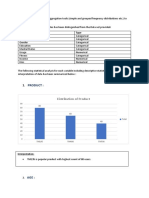
Das könnte Ihnen auch gefallen
- Understanding Power Dynamics and Developing Political ExpertiseDokument29 SeitenUnderstanding Power Dynamics and Developing Political Expertisealessiacon100% (1)
- EtomDokument1 SeiteEtomarthryxNoch keine Bewertungen
- 21 Great Answers To: Order ID: 0028913Dokument13 Seiten21 Great Answers To: Order ID: 0028913Yvette HOUNGUE100% (1)
- 8102 Assignment 1 - Statistical AnalysisDokument8 Seiten8102 Assignment 1 - Statistical AnalysistNoch keine Bewertungen
- Article State& Trait-Math Anxieties Performance-Inhibiting Predictors of Math AchievementDokument2 SeitenArticle State& Trait-Math Anxieties Performance-Inhibiting Predictors of Math AchievementGautam KumarNoch keine Bewertungen
- Data Mining Algorithms For ClassificationDokument27 SeitenData Mining Algorithms For ClassificationConstantinos CalomitsiniNoch keine Bewertungen
- TOS sCIENCE 2Dokument2 SeitenTOS sCIENCE 2Marnelle N. BaguhinNoch keine Bewertungen
- Pythagorean TriplesDokument1 SeitePythagorean TriplesSurajSinghNoch keine Bewertungen
- 3RD Quarter S.y.2018-2019Dokument6 Seiten3RD Quarter S.y.2018-2019Ruby Rose Reambonanza MagsolingNoch keine Bewertungen
- Harrison - Mathematics Assessment Interview Scirpt Book - EPM742 - Primary Mathematical DevelopmentDokument42 SeitenHarrison - Mathematics Assessment Interview Scirpt Book - EPM742 - Primary Mathematical DevelopmentSanchita ShahNoch keine Bewertungen
- Factors and Multiples RevisionDokument4 SeitenFactors and Multiples RevisionSeemaNoorNoch keine Bewertungen
- Analisa Data Frequencies: NotesDokument6 SeitenAnalisa Data Frequencies: NotesVitry Dannis GriyafashionNoch keine Bewertungen
- Rubel Assignment 2Dokument7 SeitenRubel Assignment 2to.jaharkarNoch keine Bewertungen
- Sec 2.8 - Measures of PositionDokument20 SeitenSec 2.8 - Measures of PositionSiinozuko MasentseNoch keine Bewertungen
- Core08 M9Dokument9 SeitenCore08 M9HanaNoch keine Bewertungen
- Osmeña Colleges: Table of Specification: 1 Grading Periodical Examination For Mathematics Grade 8Dokument2 SeitenOsmeña Colleges: Table of Specification: 1 Grading Periodical Examination For Mathematics Grade 8alvin n. vedarozagaNoch keine Bewertungen
- Introduction To MLDokument31 SeitenIntroduction To MLarif.ishaan99Noch keine Bewertungen
- Lesson 1 Practice Problems KeyDokument19 SeitenLesson 1 Practice Problems KeyChristina LeeNoch keine Bewertungen
- Tos Math7 3RD QTRDokument1 SeiteTos Math7 3RD QTRSeb GanaraNoch keine Bewertungen
- Contoh Soal 3.1 Ungroup Data: Nama: Sinta Puspita Kelas: 1 APM Tanggal: 18-12-2021Dokument5 SeitenContoh Soal 3.1 Ungroup Data: Nama: Sinta Puspita Kelas: 1 APM Tanggal: 18-12-2021Mutiara AlyaNoch keine Bewertungen
- Lecture Notes For Chapter 1: by Tan, Steinbach, Karpatne, KumarDokument28 SeitenLecture Notes For Chapter 1: by Tan, Steinbach, Karpatne, Kumarpromila09Noch keine Bewertungen
- 09 - ML - Decision TreeDokument45 Seiten09 - ML - Decision TreeIn TechNoch keine Bewertungen
- Entry Test A: Schofield & Sims Mental ArithmeticDokument1 SeiteEntry Test A: Schofield & Sims Mental ArithmeticAbdulazeez OlatoyeNoch keine Bewertungen
- Analysis of Women Harassment Invillages Using CETD Matrix ModalDokument3 SeitenAnalysis of Women Harassment Invillages Using CETD Matrix ModaliirNoch keine Bewertungen
- A Study On: Problems of Mat Weavers in PattamadaiDokument6 SeitenA Study On: Problems of Mat Weavers in PattamadaiTrishaNoch keine Bewertungen
- QP23DP2 - 132: Time: 3 Hours Total Marks: 100Dokument2 SeitenQP23DP2 - 132: Time: 3 Hours Total Marks: 100GAURAV SHARMANoch keine Bewertungen
- 6 - Romanko - Data - Science - and - Business - Analytics - Data - MiningDokument51 Seiten6 - Romanko - Data - Science - and - Business - Analytics - Data - MiningMariia LiubivaNoch keine Bewertungen
- Box-and-Whisker Plots Describe PopulationsDokument6 SeitenBox-and-Whisker Plots Describe PopulationsAtapolLeetrakulNoch keine Bewertungen
- An Introduction To WEKADokument85 SeitenAn Introduction To WEKAJamilNoch keine Bewertungen
- Table of Specification: Acad Form No. 41Dokument1 SeiteTable of Specification: Acad Form No. 41Kristian-Emman SarateNoch keine Bewertungen
- G7 - StatisticsDokument13 SeitenG7 - StatisticsolgaNoch keine Bewertungen
- Renalyn Q. Tagubase: Financial AdvisorDokument21 SeitenRenalyn Q. Tagubase: Financial AdvisorRENSKIENoch keine Bewertungen
- NyaiasiDokument6 SeitenNyaiasiKelas BjmtewehNoch keine Bewertungen
- Classification Ppts 2021Dokument80 SeitenClassification Ppts 2021PRIYA RATHORENoch keine Bewertungen
- Pedagogía Con Sentido Emprendedor: Colegio Comfaboy Guia de Enseñanza - Aprendizaje - X - No. 008Dokument5 SeitenPedagogía Con Sentido Emprendedor: Colegio Comfaboy Guia de Enseñanza - Aprendizaje - X - No. 008Erika CristanchoNoch keine Bewertungen
- Gemh 103Dokument33 SeitenGemh 103Noya LauraNoch keine Bewertungen
- Hasil Statistika SPSSDokument3 SeitenHasil Statistika SPSSandika prayuwanaNoch keine Bewertungen
- PRMO ProblemsDokument13 SeitenPRMO ProblemsPuneet JainNoch keine Bewertungen
- Lec05 Classification DecisionTreeDokument67 SeitenLec05 Classification DecisionTreeAli ShahidNoch keine Bewertungen
- New Updated Beginning Addition and Subtraction Without Carrying NotesDokument6 SeitenNew Updated Beginning Addition and Subtraction Without Carrying NotesDra. Nelly Abigail Rodríguez RosalesNoch keine Bewertungen
- Module-III (Math 002)Dokument32 SeitenModule-III (Math 002)kd2spytjzgNoch keine Bewertungen
- Sec 2.8 - 2021Dokument20 SeitenSec 2.8 - 2021sthembisoandile059Noch keine Bewertungen
- IntroductionDokument29 SeitenIntroduction20je0426HritikGuptaNoch keine Bewertungen
- Uji Analisis KategoriDokument12 SeitenUji Analisis KategoriWidia TriNoch keine Bewertungen
- The effects of the pandemic on students' Physical healthDokument13 SeitenThe effects of the pandemic on students' Physical healthKierra CelestiaNoch keine Bewertungen
- Business Statistics 2020Dokument4 SeitenBusiness Statistics 2020Siddhant GNoch keine Bewertungen
- Welcome To The BI Data Analyst Career Path: Introduction To Data Cheatsheet - CodecademyDokument8 SeitenWelcome To The BI Data Analyst Career Path: Introduction To Data Cheatsheet - CodecademyRick HunterNoch keine Bewertungen
- Factors and Multiples Reinforcement 1 Answers by Aadithya 5ADokument4 SeitenFactors and Multiples Reinforcement 1 Answers by Aadithya 5AkousikawinsNoch keine Bewertungen
- Top Notch 3 - Unit 8 - QuizletDokument7 SeitenTop Notch 3 - Unit 8 - Quizletmoba.nasirizadeh.1379Noch keine Bewertungen
- TOS - Midterm - 1st SemDokument2 SeitenTOS - Midterm - 1st SemRoxanne EnriquezNoch keine Bewertungen
- Data Mining: Concepts and Techniques: - Slides For Textbook - Chapter 7Dokument88 SeitenData Mining: Concepts and Techniques: - Slides For Textbook - Chapter 7Nikhil TengliNoch keine Bewertungen
- fractions - CopyDokument2 Seitenfractions - CopySehrish HumayunNoch keine Bewertungen
- Lecture Notes For Chapter 3 Introduction To Data Mining, 2 EditionDokument58 SeitenLecture Notes For Chapter 3 Introduction To Data Mining, 2 EditionsumahalsNoch keine Bewertungen
- Diagnostic Test in Science 6 TOSDokument3 SeitenDiagnostic Test in Science 6 TOSJhing Jhing ManlongatNoch keine Bewertungen
- Whole Numbers: Digit Place Value Digit Value Round Off To NearestDokument38 SeitenWhole Numbers: Digit Place Value Digit Value Round Off To NearestDayang FarizahNoch keine Bewertungen
- Fundamentals of Data Mining: Muhammad AsifDokument27 SeitenFundamentals of Data Mining: Muhammad Asifmuhammadasif_5839675Noch keine Bewertungen
- Tutorial 1 SolutionsDokument3 SeitenTutorial 1 SolutionsBochra SassiNoch keine Bewertungen
- Factorsand Multiples Speed Dating ActivityDokument9 SeitenFactorsand Multiples Speed Dating ActivityshamonmfNoch keine Bewertungen
- College of Saint Adela, Inc.: PercentageDokument1 SeiteCollege of Saint Adela, Inc.: PercentageRyan Jamil B. NodaNoch keine Bewertungen
- Standard DeviationDokument6 SeitenStandard Deviationabhimanyu bidenNoch keine Bewertungen
- College For Research and Technology of CabanatuanDokument1 SeiteCollege For Research and Technology of CabanatuanLeslie OfandaNoch keine Bewertungen
- MathsTraks: Number: A Collection of Blackline Masters for ages 11-14Von EverandMathsTraks: Number: A Collection of Blackline Masters for ages 11-14Noch keine Bewertungen
- Dm2018-Social-Networks PDFDokument39 SeitenDm2018-Social-Networks PDFLeonardo VidaNoch keine Bewertungen
- Form Application HKIDDokument2 SeitenForm Application HKIDLeonardo VidaNoch keine Bewertungen
- Data Mining - Utrecht University - 13. Active LearningDokument57 SeitenData Mining - Utrecht University - 13. Active LearningLeonardo VidaNoch keine Bewertungen
- Data Mining - Utrecht University - 11. SlidesDokument71 SeitenData Mining - Utrecht University - 11. SlidesLeonardo VidaNoch keine Bewertungen
- Schedule Bachelor Year 1 - Period 1 - 2015-2016 (Version 22-07-2015)Dokument1 SeiteSchedule Bachelor Year 1 - Period 1 - 2015-2016 (Version 22-07-2015)Leonardo VidaNoch keine Bewertungen
- Data Mining - Utrecht University - 0. IntroDokument53 SeitenData Mining - Utrecht University - 0. IntroLeonardo VidaNoch keine Bewertungen
- Data Mining - Utrecht University - 3. Dm2018-Bias-VarianceDokument24 SeitenData Mining - Utrecht University - 3. Dm2018-Bias-VarianceLeonardo VidaNoch keine Bewertungen
- Data Mining - Utrecht University - 10. SlidesDokument49 SeitenData Mining - Utrecht University - 10. SlidesLeonardo VidaNoch keine Bewertungen
- Data Mining - Utrecht University - 4. Dm-Graphmod2018-1Dokument40 SeitenData Mining - Utrecht University - 4. Dm-Graphmod2018-1Leonardo VidaNoch keine Bewertungen
- Inteligencia Explosion MicroeconomiaDokument96 SeitenInteligencia Explosion MicroeconomiajesusorcheNoch keine Bewertungen
- Dm-Classtrees-2-2018 PDFDokument46 SeitenDm-Classtrees-2-2018 PDFLeonardo VidaNoch keine Bewertungen
- GSM SniffingDokument51 SeitenGSM SniffingLeonardo Vida100% (2)
- Exam History of Economic ThoughtDokument3 SeitenExam History of Economic ThoughtLeonardo VidaNoch keine Bewertungen
- Markdown Tip Sheet Quick ReferenceDokument1 SeiteMarkdown Tip Sheet Quick ReferenceNimisha SinghNoch keine Bewertungen
- Discussion LeaderDokument5 SeitenDiscussion LeaderLeonardo VidaNoch keine Bewertungen
- Web of Science TransferDokument1 SeiteWeb of Science TransferLeonardo VidaNoch keine Bewertungen
- Aufgabe 6 Java - Programmieriung IIDokument2 SeitenAufgabe 6 Java - Programmieriung IILeonardo VidaNoch keine Bewertungen
- Content ServerDokument15 SeitenContent ServerLeonardo VidaNoch keine Bewertungen
- Swartz Report - Report To The PresidentDokument182 SeitenSwartz Report - Report To The PresidentLeonardo VidaNoch keine Bewertungen
- Goals Gone Wild: The Systematic Side Effets of Over-Prescribing Goal SettingDokument28 SeitenGoals Gone Wild: The Systematic Side Effets of Over-Prescribing Goal SettingLeonardo VidaNoch keine Bewertungen
- Wittgenstein, Ludwig - Philosophical Grammar (Blackwell, 1974)Dokument496 SeitenWittgenstein, Ludwig - Philosophical Grammar (Blackwell, 1974)Viktor Ruppini100% (2)
- Military Crypt Analysis by Sreekanth ChaladiDokument649 SeitenMilitary Crypt Analysis by Sreekanth Chaladichaladhi0% (1)
- Math Test Amsterdam University 2012Dokument1 SeiteMath Test Amsterdam University 2012Leonardo VidaNoch keine Bewertungen
- Excel Data AnalysisDokument30 SeitenExcel Data AnalysisРоман УдовичкоNoch keine Bewertungen
- The UFO Book Encyclopedia of The Extraterrestrial (PDFDrive)Dokument756 SeitenThe UFO Book Encyclopedia of The Extraterrestrial (PDFDrive)James Lee Fallin100% (2)
- Workflowy - 2. Using Tags For NavigationDokument10 SeitenWorkflowy - 2. Using Tags For NavigationSteveLangNoch keine Bewertungen
- 6.1.3 Final Exam - Exam (Exam)Dokument8 Seiten6.1.3 Final Exam - Exam (Exam)parker3poseyNoch keine Bewertungen
- Amber ToolsDokument309 SeitenAmber ToolshkmydreamsNoch keine Bewertungen
- Math 101Dokument3 SeitenMath 101Nitish ShahNoch keine Bewertungen
- U1L2 - Definitions of 21st Century LiteraciesDokument19 SeitenU1L2 - Definitions of 21st Century LiteraciesJerry Glenn Latorre CastilloNoch keine Bewertungen
- Kavanaugh On Philosophical EnterpriseDokument9 SeitenKavanaugh On Philosophical EnterprisePauline Zoi RabagoNoch keine Bewertungen
- Calibration Method For Misaligned Catadioptric CameraDokument8 SeitenCalibration Method For Misaligned Catadioptric CameraHapsari DeviNoch keine Bewertungen
- Lower Congo Basin 3D SurveyDokument2 SeitenLower Congo Basin 3D SurveyTalis TemNoch keine Bewertungen
- Comparison of Waste-Water Treatment Using Activated Carbon and Fullers Earth - A Case StudyDokument6 SeitenComparison of Waste-Water Treatment Using Activated Carbon and Fullers Earth - A Case StudyDEVESH SINGH100% (1)
- 2002 AriDokument53 Seiten2002 AriMbarouk Shaame MbaroukNoch keine Bewertungen
- Feasibility of Traditional Milk DeliveryDokument21 SeitenFeasibility of Traditional Milk DeliverySumit TomarNoch keine Bewertungen
- Super-Critical BoilerDokument32 SeitenSuper-Critical BoilerAshvani Shukla100% (2)
- Conductivity NickelDokument2 SeitenConductivity Nickelkishormujumdar998Noch keine Bewertungen
- 21st Century Literature Exam SpecsDokument2 Seiten21st Century Literature Exam SpecsRachel Anne Valois LptNoch keine Bewertungen
- Airframe Exam Review QuestionsDokument23 SeitenAirframe Exam Review QuestionsbirukNoch keine Bewertungen
- E Requisition SystemDokument8 SeitenE Requisition SystemWaNi AbidNoch keine Bewertungen
- C172M QRH (VH-JZJ) v1.1Dokument49 SeitenC172M QRH (VH-JZJ) v1.1alphaNoch keine Bewertungen
- Analysis of Piled Raft of Shanghai Tower in Shanghai by The Program ELPLADokument18 SeitenAnalysis of Piled Raft of Shanghai Tower in Shanghai by The Program ELPLAAmey DeshmukhNoch keine Bewertungen
- The Influence of Teleworking On Performance and Employees Counterproductive BehaviourDokument20 SeitenThe Influence of Teleworking On Performance and Employees Counterproductive BehaviourCHIZELUNoch keine Bewertungen
- Naaqs 2009Dokument2 SeitenNaaqs 2009sreenNoch keine Bewertungen
- Main Sulci & Fissures: Cerebral FissureDokument17 SeitenMain Sulci & Fissures: Cerebral FissureNagbhushan BmNoch keine Bewertungen
- Xiaomi Mi Drone 4K User Manual GuideDokument47 SeitenXiaomi Mi Drone 4K User Manual GuideΜιχάλης ΛαχανάςNoch keine Bewertungen
- Individual Moving Range (I-MR) Charts ExplainedDokument18 SeitenIndividual Moving Range (I-MR) Charts ExplainedRam Ramanathan0% (1)
- Ivy DLP 2nd Quart CotDokument4 SeitenIvy DLP 2nd Quart CotJhim CaasiNoch keine Bewertungen
- Electromagnetic Braking SystemDokument14 SeitenElectromagnetic Braking SystemTanvi50% (2)