Das könnte Ihnen auch gefallen
- Embedded Processors and Memory: Version 2 EE IIT, Kharagpur 1Dokument9 SeitenEmbedded Processors and Memory: Version 2 EE IIT, Kharagpur 1ahamedNoch keine Bewertungen
- Vassilis Sakizlis, Vivek Dua, Stratos PistikopoulosDokument34 SeitenVassilis Sakizlis, Vivek Dua, Stratos PistikopouloscacacocoNoch keine Bewertungen
- Digital Signal Processing QUESTION BANKDokument5 SeitenDigital Signal Processing QUESTION BANKSaran SekaranNoch keine Bewertungen
- OFDM & Cyclic PrefixDokument37 SeitenOFDM & Cyclic PrefixRani KumariNoch keine Bewertungen
- Art I Go CN Mac 2024 Armando VelasquezDokument7 SeitenArt I Go CN Mac 2024 Armando VelasquezMaria Luisa Velasquez VelasquezNoch keine Bewertungen
- FFTDokument28 SeitenFFTFan Wang100% (2)
- GE42 DSP 22 p1Dokument75 SeitenGE42 DSP 22 p1Imane ZahiriNoch keine Bewertungen
- Lec02 Architecture1Dokument28 SeitenLec02 Architecture1Whenrick DilloNoch keine Bewertungen
- Analog FFT Interface For Ultra-Low Power Analog Receiver ArchitecturesDokument4 SeitenAnalog FFT Interface For Ultra-Low Power Analog Receiver ArchitecturesNathan ImigNoch keine Bewertungen
- 2006 ISRO ECE Question Paper PDFDokument19 Seiten2006 ISRO ECE Question Paper PDFKD0% (1)
- Basics of Feedback Control: Mechanical and Aerospace Engineering Cornell UniversityDokument36 SeitenBasics of Feedback Control: Mechanical and Aerospace Engineering Cornell UniversityahmadNoch keine Bewertungen
- MC IdmaDokument28 SeitenMC IdmaAliAlissNoch keine Bewertungen
- Video Segment: ControlDokument14 SeitenVideo Segment: ControlTimothy FieldsNoch keine Bewertungen
- Real-time DSP Lecture TMS320C6xDokument42 SeitenReal-time DSP Lecture TMS320C6xAndika Dwi RubyantoroNoch keine Bewertungen
- PCE6101 Linear Systems Theory: (Tracking Controller Design)Dokument31 SeitenPCE6101 Linear Systems Theory: (Tracking Controller Design)Birhex FeyeNoch keine Bewertungen
- Pulse-Width Modulation Fundamentals and Applications in Control SystemsDokument4 SeitenPulse-Width Modulation Fundamentals and Applications in Control SystemsYassine DjillaliNoch keine Bewertungen
- 01 Time Response Analysis V1Dokument47 Seiten01 Time Response Analysis V1ShadowツNoch keine Bewertungen
- Hardware For Universal Quantum Computers: - A Programmable Trapped-Ion MachineDokument44 SeitenHardware For Universal Quantum Computers: - A Programmable Trapped-Ion MachineTarek SeguirNoch keine Bewertungen
- Aducrf101: Uhf TransceiverDokument26 SeitenAducrf101: Uhf TransceiverdudualbertiNoch keine Bewertungen
- Dynamic CMOSDokument15 SeitenDynamic CMOSPoornanand NaikNoch keine Bewertungen
- Course 1112Dokument42 SeitenCourse 1112Veko BoyNoch keine Bewertungen
- McltechoDokument3 SeitenMcltechojagruteegNoch keine Bewertungen
- Source and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Dokument17 SeitenSource and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Adarsh AnchiNoch keine Bewertungen
- Ieee Paper Presentation: Gude Aditya 611627Dokument22 SeitenIeee Paper Presentation: Gude Aditya 611627lokesh kadagalaNoch keine Bewertungen
- Synchronization and Digital Receivers: Marie-Laure BOUCHERET Irit/Enseeiht E-MailDokument50 SeitenSynchronization and Digital Receivers: Marie-Laure BOUCHERET Irit/Enseeiht E-MailJean-Hubert DelassaleNoch keine Bewertungen
- UART Design and ImplementationDokument28 SeitenUART Design and ImplementationpreetiNoch keine Bewertungen
- Lec8 - Transform Coding (JPG)Dokument39 SeitenLec8 - Transform Coding (JPG)Ali AhmedNoch keine Bewertungen
- Two Machine System Pu ModelDokument14 SeitenTwo Machine System Pu ModelDinesh ShettyNoch keine Bewertungen
- ELEC30x0 Lab11 Characterization SlidesDokument22 SeitenELEC30x0 Lab11 Characterization Slideswww.autovatorNoch keine Bewertungen
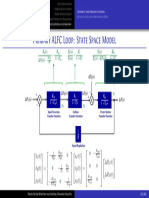
- Primary ALFC LoopDokument1 SeitePrimary ALFC LoopCharandeep TirkeyNoch keine Bewertungen
- Ee 6403 - Discrete Time Systems and Signal Processing (April/ May 2017) Regulations 2013Dokument4 SeitenEe 6403 - Discrete Time Systems and Signal Processing (April/ May 2017) Regulations 2013selvakumargeorg1722Noch keine Bewertungen
- Simulation of Communication Systems: Wireless Systems Instructional DesignDokument12 SeitenSimulation of Communication Systems: Wireless Systems Instructional DesignshahdNoch keine Bewertungen
- Digital Communications I: Modulation and Coding Course: Term 3 - 2008 Catharina LogothetisDokument22 SeitenDigital Communications I: Modulation and Coding Course: Term 3 - 2008 Catharina LogothetiserichaasNoch keine Bewertungen
- Guckert Audio Compression SVD MDCT MP3 PDFDokument13 SeitenGuckert Audio Compression SVD MDCT MP3 PDFZoran BogoeskiNoch keine Bewertungen
- An MDCT Hardware Accelerator for MP3 AudioDokument5 SeitenAn MDCT Hardware Accelerator for MP3 AudioFlorin CiudinNoch keine Bewertungen
- Optimal ControlDokument32 SeitenOptimal Controlvicenc puigNoch keine Bewertungen
- Lecture 2Dokument22 SeitenLecture 2Amir KhanNoch keine Bewertungen
- Digital Modulation Techniques ExplainedDokument42 SeitenDigital Modulation Techniques ExplainedHuongNguyenNoch keine Bewertungen
- DSP II Math BackgroundDokument21 SeitenDSP II Math BackgroundraviNoch keine Bewertungen
- L20: Waveform CodingDokument13 SeitenL20: Waveform CodingHunter VerneNoch keine Bewertungen
- 1 Basics DSP AV IntroDokument36 Seiten1 Basics DSP AV IntroUbaid UmarNoch keine Bewertungen
- Signal Processing: Design of IIR FiltersDokument94 SeitenSignal Processing: Design of IIR FiltersTrần Nhật DươngNoch keine Bewertungen
- LE3U-Manual SpecificationDokument11 SeitenLE3U-Manual SpecificationPVC XANH QDNoch keine Bewertungen
- College scheduling optimization techniquesDokument35 SeitenCollege scheduling optimization techniquesperplexeNoch keine Bewertungen
- tp2 Systc3a8mes Asservis Numc3a9riquesDokument1 Seitetp2 Systc3a8mes Asservis Numc3a9riquesomarNoch keine Bewertungen
- 5.2 CMOS Logic Gate Design: Serial or Parallel in Rs Transisto of NoDokument15 Seiten5.2 CMOS Logic Gate Design: Serial or Parallel in Rs Transisto of NoRaj AryanNoch keine Bewertungen
- Greatest Common Divisor Circuit Design Greatest Common Divisor Circuit DesignDokument35 SeitenGreatest Common Divisor Circuit Design Greatest Common Divisor Circuit Designvishalideepak1324Noch keine Bewertungen
- 09-Digital Control SystemsDokument2 Seiten09-Digital Control Systemssudhakar kNoch keine Bewertungen
- An FPGA-Based Digital Modulation Signal Generator With Fading Channel EmulationDokument5 SeitenAn FPGA-Based Digital Modulation Signal Generator With Fading Channel Emulationsenao71263Noch keine Bewertungen
- Real Time Optimization: A Parametric Programming Approach: Vivek DuaDokument26 SeitenReal Time Optimization: A Parametric Programming Approach: Vivek DuaKurtuluş Mehmet AkkayaNoch keine Bewertungen
- Minimum Distance Sequence Detection Receiver Design for PAMDokument8 SeitenMinimum Distance Sequence Detection Receiver Design for PAMMalkurthi SreekarNoch keine Bewertungen
- Digital Control Systems KDS PDFDokument77 SeitenDigital Control Systems KDS PDFSudip MondalNoch keine Bewertungen
- DTSP ExtcDokument15 SeitenDTSP ExtcPurva KNoch keine Bewertungen
- Đ Án Rơ Le DuyDokument44 SeitenĐ Án Rơ Le Duynam phuongNoch keine Bewertungen
- Combinatorial Algorithms: For Computers and CalculatorsVon EverandCombinatorial Algorithms: For Computers and CalculatorsBewertung: 4 von 5 Sternen4/5 (2)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Von EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Noch keine Bewertungen
- Practical Digital Electronics for TechniciansVon EverandPractical Digital Electronics for TechniciansBewertung: 3 von 5 Sternen3/5 (1)
- Verilog HDL Synthesis and ImplementationDokument41 SeitenVerilog HDL Synthesis and ImplementationAlexandru OleinicNoch keine Bewertungen
- Control LED Integrated Light Source with 40 CharactersDokument5 SeitenControl LED Integrated Light Source with 40 CharactersMathavanSekarNoch keine Bewertungen
- Microprocessor Systems Laboratory Project DescriptionsDokument22 SeitenMicroprocessor Systems Laboratory Project DescriptionsAlexandru OleinicNoch keine Bewertungen
- ATmega128 DatasheetDokument389 SeitenATmega128 Datasheetakalakalan6747Noch keine Bewertungen
- FirebaseDokument23 SeitenFirebaseAlexandru OleinicNoch keine Bewertungen
- 16F877ADokument234 Seiten16F877AMarius PauletNoch keine Bewertungen
- 5.0mm DIA LED Lamp Spec SheetDokument8 Seiten5.0mm DIA LED Lamp Spec SheetAlexandru OleinicNoch keine Bewertungen
- Erasmus+ Institutional Data SheetDokument1 SeiteErasmus+ Institutional Data SheetAlexandru OleinicNoch keine Bewertungen
- VTP Troubleshooting PDFDokument2 SeitenVTP Troubleshooting PDFputri nabilaNoch keine Bewertungen
- Operating System File ManagementDokument79 SeitenOperating System File ManagementLaxmiPantNoch keine Bewertungen
- Networking Interview BasicsDokument39 SeitenNetworking Interview BasicsKrsna Parmar0% (1)
- Nokia Live PresentationDokument27 SeitenNokia Live PresentationwasiffarooquiNoch keine Bewertungen
- OTR Messages HandlingDokument14 SeitenOTR Messages HandlingDineshkumar AkulaNoch keine Bewertungen
- Module Description CPR-041Dokument15 SeitenModule Description CPR-041trantienNoch keine Bewertungen
- Lead DevOps Engineer ResumeDokument1 SeiteLead DevOps Engineer ResumeAnil KumarNoch keine Bewertungen
- MINI DV Camera Lighter User Manual: Product InfoDokument2 SeitenMINI DV Camera Lighter User Manual: Product InfoAleksandar JovanovicNoch keine Bewertungen
- Design Phase in OOADDokument28 SeitenDesign Phase in OOADAnkit KhandelwalNoch keine Bewertungen
- MCQ - MPMCDokument9 SeitenMCQ - MPMCRanganayaki RamkumarNoch keine Bewertungen
- Cloud Adoption Report FINAL PDFDokument8 SeitenCloud Adoption Report FINAL PDFLucy Kyule-NgulaNoch keine Bewertungen
- GFDSKJDokument5 SeitenGFDSKJSanjiv MainaliNoch keine Bewertungen
- How To - Sales Order Simulation From C4C To ECC Using HCI - SAP BlogsDokument8 SeitenHow To - Sales Order Simulation From C4C To ECC Using HCI - SAP BlogsJohnEguiluzNoch keine Bewertungen
- Eth Adapter CN User ManualDokument34 SeitenEth Adapter CN User Manualfahim47Noch keine Bewertungen
- V-REP Quick User ManualDokument16 SeitenV-REP Quick User Manualgfrutoss100% (1)
- Hot Features of OSN 1832 01 - Planning PDFDokument441 SeitenHot Features of OSN 1832 01 - Planning PDFPravin PawarNoch keine Bewertungen
- PD41 PD42 Spec WebDokument2 SeitenPD41 PD42 Spec WebHồ ThànhNoch keine Bewertungen
- Fundamentals of Power System Protection by Paithankar Solution Manual PDFDokument3 SeitenFundamentals of Power System Protection by Paithankar Solution Manual PDFSuvom Roy33% (3)
- SICAM PAS - Overview - Final - ENDokument11 SeitenSICAM PAS - Overview - Final - ENAldo Bona HasudunganNoch keine Bewertungen
- Tm1 Deployment Options and Bandwidth ConsiderationsDokument10 SeitenTm1 Deployment Options and Bandwidth ConsiderationsFFARALNoch keine Bewertungen
- Compactmax-2: Dvb-S/S2 To Dvb-T2Dokument2 SeitenCompactmax-2: Dvb-S/S2 To Dvb-T2Carroza BikersNoch keine Bewertungen
- Websphere Basics: What Is WASDokument17 SeitenWebsphere Basics: What Is WASSai KrishnaNoch keine Bewertungen
- Tuxedo AdminDokument336 SeitenTuxedo AdminNguyễn CươngNoch keine Bewertungen
- Tg-16 Pce Component Mod GuideDokument13 SeitenTg-16 Pce Component Mod GuideJose Eduardo Sanchez LarretaNoch keine Bewertungen
- T3TAFJ-T24 and TAFJ Upgrade-R16Dokument21 SeitenT3TAFJ-T24 and TAFJ Upgrade-R16adyani_0997Noch keine Bewertungen
- Simatic S7-200 Micro PLC: Ordering Information DescriptionDokument13 SeitenSimatic S7-200 Micro PLC: Ordering Information DescriptionVinicius ViniNoch keine Bewertungen
- AirWatch (v8.0) - On-Premise Configuration GuideDokument41 SeitenAirWatch (v8.0) - On-Premise Configuration GuideTony Y100% (2)
- How to install Aspen HYSYS V9 and configure licensing in less than 40 stepsDokument21 SeitenHow to install Aspen HYSYS V9 and configure licensing in less than 40 stepsMitzgun AjahNoch keine Bewertungen
- 2-3 WLAN OverviewDokument45 Seiten2-3 WLAN OverviewSatish KumarNoch keine Bewertungen
- ISP Franchise Overview 10Dokument11 SeitenISP Franchise Overview 10Bnaren Naren100% (1)