Beruflich Dokumente
Kultur Dokumente
Lecture 2
Hochgeladen von
Sanjay S Ray0 Bewertungen0% fanden dieses Dokument nützlich (0 Abstimmungen)
8 Ansichten28 SeitenOriginaltitel
lecture2
Copyright
© © All Rights Reserved
Verfügbare Formate
TXT, PDF, TXT oder online auf Scribd lesen
Dieses Dokument teilen
Dokument teilen oder einbetten
Stufen Sie dieses Dokument als nützlich ein?
Sind diese Inhalte unangemessen?
Dieses Dokument meldenCopyright:
© All Rights Reserved
Verfügbare Formate
Als TXT, PDF, TXT herunterladen oder online auf Scribd lesen
0 Bewertungen0% fanden dieses Dokument nützlich (0 Abstimmungen)
8 Ansichten28 SeitenLecture 2
Hochgeladen von
Sanjay S RayCopyright:
© All Rights Reserved
Verfügbare Formate
Als TXT, PDF, TXT herunterladen oder online auf Scribd lesen
Sie sind auf Seite 1von 28
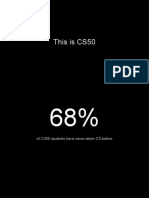
[MUSIC PLAYING] DAVID J. MALAN: All right.
This is CS50 and this is the start of
week two. And you'll recall that over the past couple of weeks, we've been building
up. First initially from Scratch, the graphical programming language that we then,
just last week, translated to the equivalent program NC. And of course, there's a
lot more syntax now. It's entirely text but the ideas, recall, were fundamentally
the same. The catch is that computers don't understand this. They only understand
what language? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: zeros and ones or binary. And
so there's a requisite step in order for us to get from this code to binary. And
what was that step or that program or process called? AUDIENCE: [INAUDIBLE] DAVID
J. MALAN: Yeah, so compiling. And of course, recall as you've now experimented with
this past week that to compile a program, you can use clang for C, language. And
you can just say clang and then the name of the file that you want to compile. And
that outputs by default a pretty oddly named program. Just a dot out. Which stands
for assembler output. More on that in just a moment. But recall too that you can
override that default behavior. And you can actually say, Output instead a program
called, hello instead of just a dot out. But you can go one step further, and you
actually use Make. And Make it self is not a compiler, it's a build utility. But in
layman's terms, what does it do for us? AUDIENCE: [INAUDIBLE] DAVID J. MALAN:
compiles it. And it essentially figures out all of those otherwise cryptic looking
command line arguments. Like dash-o something, and so forth. So that the program is
built just the way we want it without our having to remember those seemingly
magical incantations. And though that only works for programs as simple as this. In
fact, some of you with the most recent problems that might have encountered
compilation errors that we actually did not encounter deliberately in class because
Make was helping us out. In fact, as soon as you enhance a program to actually take
user input using CS50's library by including CS50 dot H, some of you might have
realized that all of a sudden the sandbox, and more generally Clang, didn't know
what get_string was. And frankly, Clang might not even known what a string was. And
that's because those two are features of CS50's library that you have to teach
Clang about. But it's not enough to teach Clang what they look like, as by
including CS50.h. Turns out there's a missing step that Make helps us solve but
that you too can just solve manually if you want. And by that I mean this, instead
of compiling a program with just Clang, hello.c. When you want to use CS50's
library, you actually need to add this additional command line argument.
Specifically at the end, can't go in the beginning like dash-O. And dash-L stands
for link. And this is a way of telling Clang, by the way when compiling my program,
please link in CS50's zeros and ones that we the staff wrote some weeks ago and
installed in the sandbox for you. So you've got your zeros and ones and then you've
got our zeros and ones so to speak. And dash-LCS50 says to link them together. So
if you were getting some kind of undefined reference error to get_string or you
didn't-- you weren't able to compile a program that just used any of the get
functions from CS50's library. Odds are, this simple change dash-LCS50 would have
fixed. But of course, this isn't interesting stuff to remember, let alone
remembering how to use dash-0 as well, at which point the command gets really
tedious to type. So here comes, Make again. Make automates all of this for us. And
in fact, if you henceforth start running Make and then pay closer attention to the
fairly long line of output that it outputs, you'll actually see mention of dash-
LCS50, you'll see mention of even dash-LM, which stands for math. So if you're
using round, for instance, you might have discovered that round two also doesn't
work out of the box unless you use Make itself or this more nuanced approach. So
this is all to say that compiling is a bit of a white lie. Like, yes you've been
compiling and you've been going from source code to machine code. But it turns out
that there's been a number of other steps happening for you that we're going to
just slap some labels on today. At the end of the day, we're just breaking the
abstraction. So compiling is this abstraction from source code to machine code.
Let's just kind of zoom in briefly to appreciate what it is that's going on in
hopes that it makes the code we're compiling a little more understandable. So step
one of four, when it comes to actually compiling a program is called Pre-
processing. So recall that this program we just looked at had a couple of includes
at the top of the file. These are generally known as pre-processor directives. Not
a particularly interesting term but they're demarcated by the hash at the start of
these lines. That's a signal to Clang that these things should be handled first.
Preprocessed. Process before everything else. And in fact, the reason for this we
did discuss last week, inside of CS50.h is what, for instance? AUDIENCE:
[INAUDIBLE] DAVID J. MALAN: Specifically, the declaration of get strings. So
there's some lines of code, the prototype if you recall, that one line of code that
teaches Clang what the inputs to get_string are and what the outputs are. The
return type and the arguments, so to speak. And so when you have include CS50.h at
the top of the file, what is happening when you first run Clang during this so-
called pre-processing step, is Clang looks on the hard drive for the file literally
called CS50.h. It grabs its contents and essentially finds and replaces this line
here. So somewhere in CS50.h is a line like this yellow one here that says
get_string, is a function that returns a string. And it takes as input, the so-
called argument, a string that we'll call prompt. Meanwhile, with include standard
I/O. What's the point of including that? What is declared inside of that file
presumably? Yeah? AUDIENCE: It's the standard inputs and outputs. DAVID J. MALAN:
Standard inputs and outputs. And more specifically, what example there of? What
function? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: So printf. The other function we
keep using. So inside of standard io.h, somewhere on the sandbox's hard drive is
similarly a line of code that frankly looks a little more cryptic but we'll come
back to this sort of thing down the road, that says print if is a function. Happens
to return on int, but more on that another time. Happens to take a char* format.
But more on that another time. Indeed, this is one of the reasons we hide this
detail early on because there's some syntax that's just a distraction for now. But
that's all that's going on. The sharp include sign is just finding and replacing
the contents. Plus dot, dot, dot, a bunch of other things in those files as well.
So when we say pre-processing, we just mean that that's getting substituted in so
you don't have to copy and paste this sort of thing manually yourself. So
"compiling" is a word that actually has a well-defined meaning. Once you've
preprocessed your code, and your code looks essentially like this, unbeknownst to
you, then comes the actual compilation step. And this code here gets turned into
this code here. Now this is scary-looking, and this is the sort of thing that if
you take a class like CS61 at Harvard, or, more generally, systems programming, so
to speak, you might see something like this. This is x86 64-bit assembly
instructions. And the only thing interesting about that claim for the moment is
that assembly-- I kind of alluded to that earlier-- assembler output, a.out.
There's actually a relationship here, but long story short, these are the lower
level instructions that only the CPU, the brain inside your computer, actually
understands. Your CPU does not understand C. It doesn't understand Python or C++ or
Java or any language with which you might be familiar. It only understands this
cryptic-looking thing. But frankly, from the looks of it, you might glean that
probably not so much fun to program in this. I mean, arguably, it's not that much
fun to program yet in C, So this looks even more cryptic. But that's OK. C and lots
of languages are just these abstractions on top of the lower level stuff that the
CPUs do actually understand so that we don't have to worry about it as much. But if
we highlight a few terms, here you'll see some familiar things. So main is
mentioned in this so-called assembly code. You see mention of get string and
printf, so we're not losing information. It's just being presented in really a
different language, assembly language. Now you can glean, perhaps, from some of the
names of these instructions, this is what Intel Inside means. When Intel or any
brand of CPU understands instructions, it means things like pushing and moving and
subtracting and calling. These are all low level verbs, functions, if you will, but
at the level of the CPU. But for more on that, you can take entire courses. But
just to take the hood off of this for today, this is a step that's been happening
for us magically unbeknownst to us, thanks to Clang. So assembling-- now that
you've got this cryptic-looking code that we will never see again-- we'll never
need to output again-- what do you do with it? Well, you said earlier that
computers only understand zeros and ones, so the third step is actually to convert
this assembly language to actual zeros and ones that now look like this. So the
assembling step happening, unbeknownst to you, every time you run Clang or, in
turn, run make, we're getting zeros and ones out of the assembly code, and we're
getting the assembly code out of your C-code. But here's the fourth and final step.
Recall that we need to link in other people's zeros and ones.
If you're using printf you didn't write that. Someone else created those zeros and
ones, the patterns that the computer understands. You didn't create get string. We
did, so you need access to those zeros and ones so that your program can use them
as well. So linking, essentially, does this. If you've written a program-- for
instance, hello.c-- and it happens to use a couple of other libraries, files that
other people wrote of useful code for you, like cs50.c, which does exist somewhere,
and even stdio.c, which does exist somewhere, or technically, Standard IO is such a
big library, they actually put printf in a file specifically called printf.c. But
somewhere in the sandbox's hard drive, in all of our Macs and PCs, if they support
compiling, are, for instance, files like these. But we've got to convert this to
zeros and ones, this, and this, and then somehow combine them. So pictorially, this
just looks a bit like this. And this is all happening automatically by Clang.
Hello.c, the code you wrote, gets compiled to assembly, which then gets assembled
into zeros and ones, so-called machine code or object code. Cs50.c-- we did this
for you before the semester started. Printf was done way before any of us started
decades ago and looks like this. These are three separate files, though, so the
linking step literally means, link all of these things together, and combine the
zeros and ones from, like, three, at least, separate files, and just combine them
in such a way that now the CPU knows how to use not just your code but printf and
get string and so forth. So last week, we introduced compiling as an abstraction,
if you will, and this is all that we've really meant this whole time. But now that
we've seen what's going on underneath the hood, and we can stipulate that my CPU
that looks physically like this, albeit smaller in a laptop or desktop, knows how
to deal with all of that. So any questions on these four steps-- pre-processing,
compiling, assembling, linking? But generally, now, we can just call them
compiling, as most people do. Any questions? Yeah. AUDIENCE: How does the CPU know
that [INAUDIBLE] is there? Is that [INAUDIBLE]? DAVID J. MALAN: Not in the pre-
processing step, so the question is, how does the computer know that printf is the
only function that's there? Essentially, when you're linking in code, only the
requisite zeros and ones are typically linked in. Sometimes you get more than you
actually need, if it's a big library, but that's OK, too. Those zeros and ones are
just never used by the CPU. Good question. Other questions? OK, all right. So now
that we know this is possible, let's start to build our way back up, because
everyone here probably knows now that when writing in C, which is kind of up here
conceptually, like, it is not without its hurdles and problems and bugs and
mistakes. So let's introduce a few techniques and tools with which you can
henceforth, starting this week and beyond, trying to troubleshoot those problems
yourself rather than just trying to read through the cryptic-looking error messages
or reach out for help to another human. Let's see if software can actually answer
some of these questions for you. So let me go ahead and do this. Let me go ahead
and open up a sandbox here, and I'm going to go ahead and create a new file called
buggy0.c in which I will, this time, deliberately introduce a bug. I'm going to go
ahead and create my function called main, which, again, is the default, like when
green flag is clicked. And I'm going to go ahead and say, printf, quote, unquote,
"Hello world/m." All right. Looks pretty good. I'm going to go ahead and compile
buggy0, Enter, and of course, I get a bunch of error messages here. Let me zoom in
on them. Fortunately, I only have two, but remember, you have to, have to, have to
always scroll up to look at the first, because there might just be an annoying
cascading effect from one earlier bug to the later. So buggy0.c, line 5, is what
this means, character 5, so like 5 spaces in, implicitly declaring library function
printf with dot, dot, dot. So you're going to start to see this pretty often if you
make this particular mistake or oversight. Implicitly declaring something means you
forgot to teach Clang that something exists. And you probably know from experience,
perhaps now, what the solution is. What's the first mistake I made here? AUDIENCE:
[INAUDIBLE]. DAVID J. MALAN: Yeah, I didn't include the header file, so to speak,
for the library. I'm missing, at the top of the file, include stdio.h, in which
printf is defined. But let's propose that you're not quite sure how to get to that
point, and how can we get, actually, some help with this? Let me actually increase
the size of my terminal here, and recall that just a moment ago, I ran makebuggy0,
which yielded the errors that I saw. It turns out that installed in the sandbox is
a command that we, the staff, wrote called help50. And this is just a program we
wrote that takes as input any error messages that your code or some program has
outputted. We kind of look for familiar words and phrases, just like a TF would in
office hours, and if we recognize some error message, we're going to try to
provide, either rhetorically or explicitly, some advice on how to handle. So if I
go ahead and run this command now, notice there's a bit more output. I see exactly
the same output in white and green and red as before, but down below is some
yellow, which comes specifically from help50. And if I go ahead and zoom in on
this, you'll see that the line of output that we recognized is this one, that same
one I verbally drew attention to before-- buggy0.c, line 5, error, implicitly
declaring library function printf, and so forth. So here, without the background
highlighting, but still in yellow, is our advice or a question a TF or CA might ask
you in office hours. Well, did you forget to include stdio.h in which printf is
declared atop your file? And hopefully, our questions, rhetorical or otherwise, are
correct, and that will get you further along. So let's go ahead and try that
advice. So include stdio.h. Now let me go ahead and go back down here. And if you
don't like clutter, you can type "clear," or hit Control+L in the terminal window
to keep cleaning it like I do. If you want to go ahead now and run makebuggy0,
Enter, fewer errors, so that's progress, and not the same. So this one's, perhaps,
a little easier. Reading the line, what line of code is buggy here? AUDIENCE:
Forgot the semicolon. DAVID J. MALAN: Yeah, so this is now still on line 5, it
turns out, but for a different reason. I seem to be missing a semi-colon. But I
could similarly ask help50 for help with that and hope that it recognizes my error.
So this, too, should start being your first instinct. If on first glance, you don't
really understand what an error message is doing, even though you've scrolled to
the very first one, like literally ask this program for help by rerunning the exact
same command you just ran, but prefix it with help50 and a space, and that will run
help50 for you. Any questions on that process? All right, let's take a look at one
other program, for instance, that, this time, has a different error involved in it.
So how about-- let me go ahead and whip up a quick program here. I'll call this
buggy2.c for consistency with some of the samples we have online for you later. And
in this example, I'm going to go ahead and write the correct thing at first,
stdio.h, and then I'm going to have int main void, which just gets my whole program
started. And then I'm going to have a loop, and recall for-- [CLEARS THROAT] excuse
me-- Mario or some other program, you might have done something like int i get 0, i
is less than or equal to-- let's do this 10 times, and then i++. And all I want to
do in this program is print out that value of i, as I can do, with the %i
placeholder-- so a simple program. Just want it to count from 0 to 10. So let's go
ahead and run buggy2, or rather, I want to-- let's not print up-- rewind. Let's go
ahead and just print out a hash symbol and not spoil the solution this way. So
here, I go ahead and print out buggy2. My goal is now I will stipulate to print out
just 10 hash symbols, one per line, which is what I want to do here. And now I'm
going to go ahead and run ./buggy2, and I should see, hopefully, 10 hashes. And I
kind of spoiled this a little bit, but what do I instead see? Yeah, I think I see
more than I expect. And we can kind of zoom in here and double check, so 1, 2, 3,
4, 5, 6, 7, 8, 9, 10, ooh, 11. 11. Now some of your eyes might already be darting
to what the solution should be, but let's just propose that it's not obvious. And
if it is actually not obvious, all the better, so how might you go about diagnosing
this kind of problem, short of just reaching out and asking a human for help. This
is not a problem that help50 can help with, because it's not an error message. Your
program is working. It's just not outputting what you wanted it to work, but it's
not an error message from the compiler with which help50 can help. So you want to
kind of get eyes into what your program is doing, and you want to understand, why
are you printing 11 when you really are setting this up from 0 to 10? Well, one of
the most common techniques in C or any language, honestly, is to use printf for
just other purposes-- diagnostic purposes. For instance, there's not much going on
in this program, but I'd argue that it would be interesting for me to know, and
therefore understand my program, by just, let's print out this value of i on each
iteration, as by doing the line of code that I earlier did, and just say something
literally like, i is %i. I'm going to remove this ultimately, because it's going to
make my program look a little silly, but it's going to help me understand what's
going on. Let me go ahead
and recompile buggy2, ./bugg2, and this time, I see a lot more output. But if I
zoom in, now it's kind of-- now the computer is essentially helping me understand
what's going on. When i is 0, here's one of them. When i is 1, here's another. I is
2, 3, 4, 5, 6, 7, 8, 9, and that looks good. But if we scroll a little further, it
feels a little problematic that i can also be 10. So what's logically the bug in
this program? AUDIENCE: [INAUDIBLE]. DAVID J. MALAN: Yeah. I use less than or equal
to, because I kind of confuse the paradigm. Like programmers tend to start counting
at zero, apparently, but I want to do this 10 times, and in the human world, if I
want to do something 10 times, I might count up to and including 10. But you can't
have it both ways. You can't start at zero and end at 10 if you want to do
something exactly 10 times. So there's a couple of possibilities here. How might we
fix this? Yeah, so we could certainly change it to less than. What's another
correct approach? Yeah, so we could leave this alone and just start counting at
one, and if you're not actually printing the values in your actual program, that
might be perfectly reasonable, too. It's just not conventional. Get comfortable
with, quickly, just counting from zero, because that's just what most everyone does
these days. But the technique here is just use printf. Like, when in doubt,
literally use printf on this line, on this line, on this line. Anywhere something
is interesting maybe going on in your program, just use it to print out the strings
that are in your variables, print out the integers that are in your variables, or
anything else. And it allows you to kind of see, so to speak, what's going on
inside of your program, printf. One last tool-- so it's not uncommon, when writing
code, to maybe get a little sloppy early on, especially when you're not quite
familiar with the patterns. And for instance, if I go ahead and do this by deleting
a whole bunch of whitespace, even after fixing this mistake by going from zero to
10, is this program now correct, if the goal is to print 10 hashes? Yeah, I heard
yes. Why is it correct? In what sense? Yeah, exactly. It still works. It prints out
the 10 hashes, one per line, but it's poorly written in the sense of style. So
recall that we tend to evaluate, and the world tends to think about code in at
least three ways. One, the correctness-- does it do what it's supposed to do, like
print 10 hashes? And yes, it does, because all I did was delete whitespace. I
didn't actually change or break the code after making that fix. Two is design, like
how thoughtful, how well-written is the code? And frankly, it's kind of hard to
write this in too many ways, because it's so few lines. But you'll see over time,
as your programs grow, the teaching fellows and staff can provide you with feedback
on the design of your code. But style is relatively easy. And I've been teaching it
mostly by way of example, if you will, because I've been very methodically
indenting my code and making sure everything looks very pretty, or at least pretty
to a trained eye. But this, let's just stipulate, is not pretty. Like, left
aligning everything still works, not incorrect, but it's poorly styled. And what
would be an argument for not writing code like this and, instead, writing code the
way I did a moment ago, albeit after fixing the bug? Yeah. AUDIENCE: It'll help you
identify each little subroutine that goes through the thing, so you know this
section is here. DAVID J. MALAN: Yeah. AUDIENCE: [INAUDIBLE] next one, so you know
where everything is. DAVID J. MALAN: Exactly. Let me summarize this. It allows you
to see, more visually, what are the individual subroutines or blocks of code doing
that are associated with each other? Scratch is colorful, and it has shapes, like
the hugging shape that a lot of the control blocks make, to make clear visually to
the programmer that this block encompasses others, and, therefore, this repeats
block or this forever block is doing these things again and again and again. That's
the role that these curly braces serve, and indentation in this and in other
contexts just helps it become more obvious to the programmer what is inside of what
and what is happening where. So this is just better written, because you can see
that the code inside of main is everything that's indented here. The code that's
inside the for loop is everything that's indented here. So it's just for us human
readers, teaching fellows in the case of a course, or colleagues in the case of the
real world. But suppose that you don't quite see these patterns too readily
initially. That, too, is fine. CS50 has on its website what we call a style guide.
It's just a summary of what your code should look like when using certain features
of C-- loops, conditions, variables, functions, and so forth. And it's linked on
the course's website. But there's also a tool that you can use when writing your
code that'll help you clean it up and make it consistent, not just for the sake of
making it consistent with the style guide, but just making your own code more
readable. So for instance, if I go ahead and run a command called style50 on this
program, buggy2.c, and then hit Enter, I'm going to see some output that's
colorful. I see my own code in white, and then I see, anywhere I should have
indented, green spaces that are sort of encouraging me to put space, space, space,
space here. Put space, space, space, space here. Put eight spaces here, four spaces
here, and so forth, and then it's reminding me I should add comments as well. This
is a short program-- doesn't necessarily need a lot of commenting to explain what's
going on. But just one //, like we saw last week to explain, maybe at the top of
the file or top the block of the code, would make style50 happy as well. So let's
do that. Let me go ahead and take its advice and actually indent this with Tab,
this with Tab, this with Tab, this with Tab, and this once more. And you'll notice
that on your keyboard, even though you're hitting Tab, it's actually converting it
for you, which is very common to four spaces, so you don't have to hit the spacebar
four times. Just get into the habit of using Tab. And let me go ahead and write a
comment here. "Print 10 hashes." This way, my colleagues, my teaching fellow,
myself in a week don't have to read my own code again and figure out what it's
doing. I can read the comments alone per the //. If I run style50 again, now it
looks good. It's in accordance with the style guide, and it's just more prettily
written, so pretty printed would be a term of art in programming when your code
looks good and isn't just correct. Any questions then? Yeah. AUDIENCE: I tried
using [INAUDIBLE] this past week and it said I needed a new program. DAVID J.
MALAN: That's-- it wasn't enabled for the first week of the class. It's enabled as
of right now and henceforth. Other questions? No. All right, so just to recap then,
three tools to have in the proverbial toolbox now are help50 anytime you see an
error message that you don't understand, whether it's with make or Clang or,
perhaps, something else. Printf-- when you've got a logical program-- a bug in your
program, and it's just not working the way it's supposed to or the way the problem
set tells you it should, and then style50 when you want to make sure that, does my
code look right in terms of style, and is it as readable as possible? And honestly,
you'll find us at office hours and the like often encouraging you, hey, before we
answer this question, can you please run style50 on your code? Can you please clean
up your code, because it just makes our lives, too, as other humans so much easier
when we can understand what's going on without having to visually figure out what
parentheses and curly braces line up. And so do get into that habit, because it
will save you time from having to waste time parsing things visually yourself. All
right. So there's not just CPUs in computers. CPUs are the brains, central
processing unit, and that's why we keep emphasizing the instructions that computers
understand. There's also this, which we saw last time, too. This is an example of
what type of hardware? AUDIENCE: RAM. DAVID J. MALAN: RAM, or Random Access Memory.
This is the type of memory that laptops, desktops, servers have that is used
whenever you run a program or open a file. There's another type of memory called
hard drives or solid state drives, which you're probably familiar as a consumer,
and that's just where your files are stored permanently. Your battery can die. You
can pull the plug from your laptop or desktop, and any files saved on a hard drive
are persistent. They stay there because of the technology being used to implement
that. But RAM is more ephemeral. RAM is powered only by electricity. It's only used
when the power is on or the battery is charged, and it's where your files and
programs live effectively when you double click on them and open them. So when you
double click on something like Microsoft Word, it is copied from your hard drive
long term into this type of memory, because this type of memory, though smaller in
capacity-- you don't have as many bytes of it-- but it is much, much, much, much
faster. Similarly, when you open a document, or you go to a web page, the contents
of the file you're seeing are stored in this type of hardware, because even though
you don't have terribly many bytes of it, it's just much, much, much, much faster.
And so this will be thematic in computer science and in hardware. You sort of have
lots of cheap, slow stuff, like hard disk space, relatively speaking, and you have
a little less of the more expensive but faster stuff like RAM. And you have just
one, usually, CPU, which is the really fast thing that can do a billion things per
second. But it, too, is more expensive. So there's
four visible chips on this thing, if you will. And we won't get into the details
of how these things work, but let's just zoom in on this one black chip here and
focus on it as being representative as some amount of memory. Maybe it's one
megabyte, one million bytes. Maybe it's even one gigabyte these days, one billion
bytes. But this is to say that this chip can be thought of as just having a bunch
of bytes in it. This is not to scale. You have many more bytes than these, but let
me propose that you just think of each of these squares here as representing one
byte. So the very first byte of memory I have access to is here. Next one is here,
and so forth. And the fact that they wrap around is just an artist rendition. These
things you can think of just virtually as going left to right, not in any kind of
grid, but physically, they look like this. So when you actually create a variable
in a program like C, like you need a char. A char tends to be one byte or eight
bits, and so that means when you have a variable of type char in a C program, it
goes, literally, physically in one of these boxes, inside of your computer's RAM.
So for instance, it might take up this much space at top left. If you have a bigger
type of data, so you have an integer, which tends to be four bytes or 32 bits, you
might need more than one square, so the computer might give you access to four
squares instead. And you have 32 bits spanning that region of memory. But honestly,
I chose those boxes arbitrarily. They could be anywhere in that chip or in any of
the other chips. It's up to the computer to just remember where they are for you.
You don't need to remember that, per se. But if we think about this grid, it turns
out this is actually very valuable that we have chunks of memory-- bytes, if you
will-- that are back to back to back to back. And in fact, there's a word for this
technique. This is contiguous memory-- back to back to back to back to back. And in
general, in programming, this is referred to as an array. You might recall from
Scratch, if you use this feature, it actually has things called lists, which are
exactly that-- lists of values, lists of words, lists of strings. An array is just
a contiguous chunk of memory, such that you can store something here, something
here, something here, something here, and so forth. So it turns out an array, this
super simple primitive, is actually incredibly powerful. Just being able to store
things in my computer's memory back to back to back to back enables so many
possibilities, both design-wise, like how well I can write my code, and also how
fast I can make my code run. So let me go ahead and take out an example. Let me go
ahead and open up, for instance, a new file in a sandbox, and we'll call this
score0. So let me go ahead and close this one, create a new file called scores0.c.
And in this file, let's go ahead and write a relatively simple program. Let me go
ahead and, as usual, give myself access to some helpful functions-- cs50.h and
stdio.h. And no need to copy all this down verbatim, if you don't like. Everything
will have or is already on the course's website. Let me start my program as usual
with int main void. And then let me write a program, as this program's name
implies, that, like, asks the user for three scores on recent problem sets,
quizzes, whatever, and then kind of creates a very simple chart of them, like a bar
chart to kind of help me visualize how well or how poorly I did on something. So if
I want to get an integer, no surprise, we can use the get int function, and I can
just ask the user for their first score. But I should probably do something with
this score, and on the left hand side of this, what do I typically put? Yeah. So
int-- sure, score 1 equals this, and then my semi-colon. So you might not have had
many occasions to use ints just yet, but get int is in the cs50 library. This is
the so-called prompt that the human sees, and let me actually fix my space, because
I want the human to see the space after the colon. But that's just an aesthetic
detail. And then when I get back this value, its return value-- just like Aaron,
last week, handed me a piece of paper, so does get int hand me a virtual piece of
paper with a number that I'm going to store in a variable called Score 1. And now
just to be clear, what has just happened effectively is this. The moment you create
a variable of type int, which is four bytes, literally, this is what Clang or, more
generally, the computer has done for you. That int that the human typed in is
stored literally in four contiguous bytes back to back to back, maybe here, maybe
here, but together. So that's all that's going on when you're actually using C. So
let me go back into my code here, and now I want to-- it's not interesting to plot
one score. So let's go ahead and do another. So int Score 2, get int, get int, and
I'll ask the user for score 2, semi-colon, and then let's get one more, Score 3,
get int, call it Score 3, semi-colon. All right, so now let me go ahead and
generate a bar, like a bar chart of this. I'm going to use what we'll call ASCII
art. ASCII, of course, is just text, recall-- very simple text in a computer. And I
can kind of make a bar chart pretty simply by just printing out like a bunch of
hashes horizontally, so a short bar will represent a small number, and a long bar
will represent a big number. So let me go ahead and say to the user, all right,
here's your Score 1. I'm going to go ahead, then, and say, for int i get 0. I is
less than Score 1, i++. And now if I scroll down and give myself a bit of room
here, let me go ahead and implement just a simple print. So go ahead and print out
a hash, and then when you're all done with that, print out a new line at the end of
that loop. And let's just pause there. Just to recap, I've asked the human for
three scores. I'm only doing something with one of them at the moment, so in fact,
just as a quick check, let me delete those so as to not get ahead of myself. Let me
do make score 0. Cross my fingers. OK, no errors. Now let me go ahead and do
./score0, and your first score on a pset this year out of 100 has been? OK, 100.
And good job. So it's a really long bar, and if we count those up, hopefully,
there's actually 100 bars. And if we run it again and say, eh, it didn't go so
well. I got a 50. That's half as big a bar. So it seems like we're on our way
correctness-wise. So now let me go ahead and get the other scores. Well, I had them
here a moment ago. So let me go ahead and just, well, copy, paste, and change this
to two, change this to three, change this to three, this to three. All right, I
know how to print bars clearly, so let me go ahead and do this, and then do this,
and then fix the indentation. I don't want to say Score 1 everywhere. I want to say
a Score 2, Score 2. I mean you're probably being rubbed the wrong way that this is
both tedious and sloppy, and why? What am I doing poorly now design-wise? AUDIENCE:
Copying and pasting code. DAVID J. MALAN: Like copy-pasting almost always bad,
right? There's redundancy here, but that's fine. Let's prioritize correctness, at
least, for now. So let me go ahead and make Score 0. All right, no mistakes--
./score0. And then Tab it. Let me go ahead now and run-- OK, we got 100 the first
time. We got 50 the-- oh, that's a bug. What did I do there? See, this is what
happens when you copy-paste. So let's fix this. That should say Score 2, so
Control+C will quit a program. Make score 0 will recreate it. ./0, Enter-- all
right, here we go. 100, 50. Let's split the difference-- 75. All right, so this is
a simple bar chart horizontally drawn of each of my three scores, where this is
100, this is 50, and this is 75. But there's opportunities for improvement here. So
one, it rubbed some folks the wrong way already that we were literally copying and
pasting code. So where is one opportunity for improvement here? What should I do
instead of copying and pasting that code again and again? What ingredient can you
bring? OK, so we can use a loop and actually just do the same thing three times. So
let's try that. Let me go ahead and do this. So let's go ahead and delete the copy-
paste I did, and let me go ahead and say, OK, well, for int i get zero, i less than
3, i++. Let me create a bracket. I can highlight multiple lines and hit Tab, and
they'll all indent for me, which is convenient. And can I do this now, for
instance? Say it a little louder. AUDIENCE: If you [INAUDIBLE] to a specific
[INAUDIBLE].. DAVID J. MALAN: Yeah, I'm a little worried. As you're noting here,
we're using on line 13 here the same variable, so mm. So it's good instincts, but I
feel like the fact that this program, unlike last week, we're now collecting
multiple pieces of data. Loops are breaking down for us. Yeah. AUDIENCE:
[INAUDIBLE] function [INAUDIBLE] takes in-- like you can have it [INAUDIBLE]. DAVID
J. MALAN: OK. AUDIENCE: So like an input of how many scores you wanted to enter.
DAVID J. MALAN: OK. AUDIENCE: And then [INAUDIBLE]. DAVID J. MALAN: Yeah, we can
implement another function that factors out some of this functionality. Any other
thoughts? AUDIENCE: Store your scores in an array. DAVID J. MALAN: OK, so we could
also store our scores in an array. So let's do these in order then, in fact. So
loops are wonderful when you want to do something again and again and again, but
the whole purpose of a function, fundamentally, is to factor out common
functionality. And there might still be a loop in the solution, but the real
fundamental problem with what I was doing a moment ago was I was copying and
pasting functionality-- shouldn't need to do that, because in both C and Scratch,
we had the ability to make our own functions. So let's do that. Let me undo my loop
changes here, just to get us back to where we were a moment ago. And let me go
ahead
and, instead, clean this up a little bit. Let me go ahead and create a new
function down here that I'm going to call, say, Chart, just to create a chart for
myself. And it's going to take as input a score, but I could call this anything I
want. It's void as its return type, because I don't need it to hand me something
back. Like I'm not getting a string from the user. I'm just printing a char. It's a
so-called side effect or output. Now I'm going to go ahead and do my loop here for
int i get 0. I is less than-- how many hashes do I want to print if I'm being
passed in the user score? Like, is this 3 here? AUDIENCE: The score. DAVID J.
MALAN: The score, so if I'm being handed a number that's 0 to 100, that's what I
want to iterate over. If my goal here, ultimately-- let me finish this thought-- i+
+ is [? 2 ?] inside this loop print out one hash per point in 1's total score. And
just to keep things clean, I'm going to go ahead and put a new line at the very end
of this. But I think now, I factored out a good amount of the redundancy. It's not
everything, but I've at least now given myself a function called Chart. So up here,
it looks like I can kind of remove this loop, which is what I factored out. That's
almost identical, except the variable name was hardcoded. And I think I could now
do chart like this, and then I maybe could do a little copy-paste, if that's OK,
like if maybe I can get away with just doing this, and then say 2, and then say 3,
and then say 3, and then say 2. So it's still copy-paste, but it's less. And it
looks better. It literally fits on the screen, so it's progress-- not perfect, but
progress. Better design, but not perfect. So is this going to compile? I'm going to
have errors why? AUDIENCE: Essentially, it's [INAUDIBLE] the program [INAUDIBLE]..
DAVID J. MALAN: OK. Yeah. AUDIENCE: We need to declare a [INAUDIBLE].. DAVID J.
MALAN: OK, good. So let me induce the actual error, just so we know what problem
we're solving. Let me go ahead and sort of innocently go ahead and compile Score 0
hoping all is well, but of course, it's not because of a familiar error up here. So
notice, implicit declaration of function chart is invalid in C99. So again,
implicit declaration of function just tends to mean Clang does not know what you're
talking about. And you could run help50, and it would probably provide you with
similar advice. But the gist of this is that chart is not a C function. It doesn't
come with C. I wrote it. I just wrote it a little too late. So one solution that we
didn't used last week would be, OK, well, if you don't know what chart is, let me
just go put it where you'll know about it. And now run make score 0. OK, problem
solved. So that fixes it, but we fixed it in a different way last week. And why
might we want to stick with last week's approach and not just copy-paste my
function and put it at the top instead of the bottom? AUDIENCE: [INAUDIBLE]. DAVID
J. MALAN: Yeah, I mean it's kind of a minor concern at the moment, because this is
a pretty short program. But I'm pushing the main part of my program, literally
called Main, farther and farther down. And the whole point of reading code is to
understand what it's doing. So if I open this file, and I have to scroll, scroll,
scroll, scroll, scroll, just looking for the main function, it's just bad style.
It's just kind of nice, and it's a good human convention. Put the main code, the
main function, when green flag clicks equivalent, at the very top. So C does offer
us a solution here. You just have to provide it with a little hint. Let me go ahead
and cut this from here, put it back down at the bottom here, and then go ahead and
copy-paste only or retype only the value-- whoops-- the value of that first line,
which is its so-called prototype. Give Clang enough information so that it knows
what arguments the function takes, what its return type is, and what its name is,
semi-colon, and that's the so-called declaration or-- and then implement it with
the curly braces and all the logic down below. So let's go ahead and run this. And
if I scroll up here, we'll see-- whoops. We'll see make score 0. All right, now
we're on our way, score 0. Enter. Score 1 is 100, 50, 75, and now we seem to have
some good functionality. But there's still an opportunity, I dare say, for
improvement. And I think the fundamental problem is that I'm still copy-pasting the
little stuff, but I think the fundamental problem is that I don't have the
expressiveness to store multiple values, unless I, in advance, as the programmer,
give them all unique names, because if I use the same variable for everything, I
couldn't collect all three variables at the top, and then iterate over all three at
the bottom, if I only have one variable. So I do need three variables, but this
doesn't scale very well. And who knows? If I want to take in five scores, 10
scores, or more scores, then I'm really copying and pasting excessively. So it
turns out, indeed, the answer is an array. So an array, at the end of the day, is
just a side effect of storing stuff in memory back to back to back to back. But
what's powerful about this reality of memory is the following. I can go ahead here
and in, say, a new and more improved version of this program, do this. Let me go
ahead and open this one, which I wrote in advance, called scores2.c. And in
scores2.c, notice we have the following code. In my main function, I've got a new
feature and a new bit of syntax. This line here that I've highlighted says, hey,
Clang, give me a variable called Scores of type integer, but please give me three
of them. So the new syntax are your square brackets, and inside of which is the
number of variables you want of that type. And you don't have to give them unique
names. You literally call them collectively, Scores, and in English, I deliberately
chose a plural to connote as much. This is an array of values, not a single value.
What can I do next? Well, here's my for loop for int i get zero i is less than 3 i+
+, and now I've solved that earlier problem that was proposed. Well, just put it in
a loop. Now I can, because now my variables are not called Score 1, Score 2, Score
3, which I literally had to hard code. They're just called Scores, and now that
they're called Scores, and I have this square bracket notation, notice what I can
do. I can get an int, and I can say, give me score%i, and plug in i plus 1. I
didn't want to say "zero," because humans don't count from zero in general. So this
is counting from one, two, and three, but the computer is doing this. So Scores is
a variable. Bracket, i, close bracket says store the i-th value there. So i-th is
just non-English. That means go to bracket 0, bracket 1, bracket 2. So what this
effectively means is on the first iteration of the loop, when i equals 0, this
looks like this, effectively. When i then becomes 1 on the next iteration, then
you're doing this. When i becomes 2 on the final iteration, it looks like this.
When i becomes 3, well, 3 is not less than 3, and so it doesn't execute again. So
by using i inside of these square brackets, am I indexing into an array? To index
into an array means go to a specific location, the so-called i-th location, but you
start counting at zero. Just to make this more real, then, if you go back to this
picture of your computer's memory, this might, therefore, be bracket i, bracket 1--
bracket 0, bracket 1, bracket 2, bracket 3, bracket 4, bracket 50, or wherever. You
can now, using square brackets, get at any of these blocks of memory to store
values for you. Any questions on what we've just done? All right, then on the flip
side, we can do the exact same thing. Now when I print my scores, I can similarly
iterate from 0 to 3, and then print out the scores by passing to chart the same
value, the i-th score. Again, the only new syntax here is variable name, square
bracket, and then a number, like 0, 1, 2, or a variable like i, and then my chart
function down here is exactly the same. It has no idea an array is even involved,
because I'm just passing in one score at a time. Now it turns out there's still one
bad design decision in this program. There's still some redundancy, something that
I keep typing again and again and again. Do any values jump out at you as repeated?
AUDIENCE: The for loop. DAVID J. MALAN: The for loop. OK, so I've got the for loop
in multiple places. Sure. And what other value seems to be in multiple places? It's
subtle. Total number. Yeah, 3. Three is in a few places. It's up here. It's when I
declare the array and ask myself for three scores. It's here when I'm iterating.
It's here when I'm iterating. It's not here, because this is a different iteration.
That's just for the hashes. So in, ironically, three places, have I written 3. So
what does this mean? Well, suppose next year you take more tests or whatever, and
you need more scores. You open up your program, and all right, now I've got five
scores and five-- whoops, typo already-- five, like this kind of pattern where
you're typing the same thing again and again. And now the onus is on me, the
programmer, to remember to change the same [? damn ?] value in multiple places--
bad, bad, bad design. You're going to miss one of those values. Your program's
going to get more complex. You're going to leave one at 3 and change the other to
5, and logical errors are eventually going to happen. So how do we solve this? The
function's not the solution here, because it's not functionality. It's just a
value. Well, we could use a variable, but a certain type of variable. These numbers
here-- 5, 5, 5 or 3, 3, 3-- are what humans generally refer to as magic numbers.
Like they're numbers, but they're kind of magical, because you just arbitrarily
hardcoded them in random places. But a better convention would be, often as a
global variable, to do this-- int, let's call
it "count," equals 3. So declare a variable of type int that is the number of
things you want, and then type that variable name all throughout your code so that
later on, if you ever want to change this program, you change it-- whoops-- in one
place, and you're done after recompiling the program. And actually, I should do a
little better than this. It turns out that if you know you have a variable that
you're never going to change, because it's not supposed to change-- it's supposed
to be a constant value-- C also has a special keyword called const, where before
the data type, you say, const int, and then the name and then the value, and this
way, the compiler, Clang, will make sure that you, the human, don't screw up and
accidentally try to change the count anywhere else. There's one other thing
notable. I also capitalize this whole thing for some reason-- human convention.
Anytime you capitalize all of the letters in a variable name, the convention is
that that means it's global. That means it's defined way up top, and you can use it
anywhere, therefore, because it's outside all curly braces. But it's meant to imply
and remind you that this is special. It's not just a so-called local variable
inside of a function or inside of a loop or the like. Any questions on that? Yeah.
AUDIENCE: What is [INAUDIBLE]? Why do you have i plus 1? DAVID J. MALAN: Oh, why do
I have i plus 1? Let me run this program real quick. Why do I have i plus 1 in this
line here, is the question. So let me go ahead and run make scores 2-- whoops-- in
my directory. Make scores 2 ./scores2, Enter. I wanted just the human to see Score
1 and Score 2 and Score 3. I didn't want him or her to see Score 0, Score 1, Score
2, because it just looks lame to the human. The computer needs to think in terms of
zeros. My humans and my users do not, so just an aesthetic. Other questions. Yeah.
AUDIENCE: [INAUDIBLE]. DAVID J. MALAN: Ah, really good question. And I actually
thought about this last night when trying to craft this example. Why don't I just
combine these two for loops, because they're clearly iterating an identical number
of times? Was this a hand or just a stretch? No, stretch. So this is actually
deliberate. If I combine these, what would change logically in my program? Yeah.
AUDIENCE: After every [INAUDIBLE] input, you would [INAUDIBLE].. DAVID J. MALAN:
Yeah, so after every human input of a score, I would see that user's chart, the row
of hashes. Then I'd ask them for another value. They'd see the chart, another
value, and they'd see the chart. And that's fine, if that is the design you want.
Totally acceptable. Totally correct. I wanted mine to look a little more
traditional with all of the bars together, so I effectively had to postpone
printing the hashes. And that's why I did have a little bit of redundancy by
getting the user's input here and then iterating again to actually print the user's
output as a chart, so just a design decision. Good question. Other questions? All
right, so what does this look like? Actually, you know what? I can probably do a
little better. Let me open up one final example involving scores and this thing
called an array. In Scores 4 here, let me go ahead and do this. Now I've changed my
chart function to do a little bit more, and you might recall from week 0 and 1, we
had the call function, and we kept enhancing it to do more and more, like putting
more and more logic into it. Notice this. Chart function now takes a second
argument, which is kind of interesting. It takes one argument, which is a number,
and then the next argument is an array of scores. So long story short, if you want
to have a function that takes as input an array, you don't have to know in advance
how big that array is. You should not, in fact, put a number in between the square
brackets in this context. But the thing is you do need to know, at some point, how
many items are in the array. If you've programmed in Java, took AP CS, Java just
gives you .length, if you recall that feature of objects. C does not have this.
Arrays do not have an inherent length associated with them. You have to tell
everyone who uses your array how long it is. So even though you don't do that
syntactically here, you literally just say, I expect an argument called scores that
is an array per the square brackets. You have to pass and almost always a second
variable that is literally called whatever you want, but is the number of things in
that array, because if the goal of this function is just to iterate over the number
of scores that are passed in, and then iterate over the number of points in that
score in order to print out the hashes, you need to know this count. So what does
this function do, just to be clear? This iterates over the total number of scores
from 0 to count, which is probably 3 or 5 or whatever. This loop here, using J,
which is just a convention, instead iterates from 0 to whatever that i-th score is.
So this is what's convenient. Now I've passed in the array, and I can still get at
individual values just by using i, because I'm on my i-th iteration here. So you
might recall this from Mario, for instance, or any other example in which you had
nested loops-- just very conventional to use i on the outside, j on the inside. But
again, the only point here is that you can, indeed, pass around arrays, even as
arguments, which we'll see why that's useful before long. Any questions? OK, so
this was a lot, but we can do so much more still with arrays. It gets even more and
more cool. In fact, we'll see, in just a bit, how arrays have actually been with us
since last week. We just didn't quite realize it under the hood, but let's go ahead
and take a breather, five minutes. We'll come back and dive in. All right. So I
know that was a bit of a cliffhanger. Where else could arrays have actually been?
But, of course, this is how we might depict it pictorially. We called it an array,
and it turns out that last week, when we introduced strings, strings, sequences of
characters, are literally just an array by another name. A string is an array of
chars, and chars, of course, is another data type. Now what are the actual
implications of this, both in terms of representation, like how a computer's
representing information, and then fundamentally, programmatically, what can we do
when we know all of our data is so back to back to back or so proximal to one
another? Well, it turns out that we can apply this logic in a few different ways.
Let me go ahead and open up, for instance, an example here called String 0. So in
our code for today, in our Source 2 folder, let me go ahead and open up String 0,
and this example looks like this. Notice that we first, on line 9, get a string
from the user. Just say, input, please. We store that value in a string, s, and
then we say, here comes the output. And notice what I'm doing in the following
line. I'm iterating over i from 0 to strlen, whatever that is. And then in line 13,
I'm printing a character one at a time. But notice the syntax I'm using, which we
didn't use last week. If you have a string called s, you can index into a string
just like it's an array, because it, indeed, is underneath the hood. So s bracket
i, where i starts at 0 and goes up to whatever this value is is just a way of
getting character 0, then character 1, then character 2, then character 3, and so
the end result is actually going to look like this. Let me go ahead and do, make
string-- whoops-- make string 0. Oops. Not in the directory. Make string 0,
./string0, Enter, and I'll type in, say, Zamyla, and the output now is Z-A-M-Y-L-A.
It's a little messy, because I don't have a new line here, so let me actually--
let's clean that up, because this is unnecessarily sloppy. So let me go ahead and
print out a new line. Let me recompile with make string 0, dot-- whoops--
./string0. Input shall be Zamyla, Enter, and now Z-A-M-Y-L-A. So why is that
happening? Well, if I scroll down on this code, it seems that I am, via this printf
line here, just getting the i-th character of the name in s, and then printing out
one character at a time per the %c, followed by a new line. So you might guess,
what is this function here doing? Strlen-- slightly abbreviated, but you can,
perhaps, glean what it means. Yeah, so it's actually string length. So it turns out
there is a function that comes with C called strlen, and humans back in the day and
to this day like to type as few characters when possible. And so strlen is string
length, and the way you use it is you just need one more header file. So there's
another library, the so-called string library that gives you string-related
functions beyond what CS50's library provides. And so if you include string.h, that
gives you access to another function called strlen, that if you pass it, a variable
containing a string, it will pass you back as a return value the total number of
characters. So I typed in Z-A-M-Y-L-A, and so that should be returning to me six,
thereby printing out the six characters in Zamyla's name. Yeah. AUDIENCE:
[INAUDIBLE]. DAVID J. MALAN: Uh-huh. AUDIENCE: [INAUDIBLE] useful to get the
individual digits [INAUDIBLE].. DAVID J. MALAN: Really good question. In the credit
problem of the problem set, would this have been useful? Yes, absolutely. But
recall that in the credit pset, we encourage you to actually take in the number as
a long, so as an integral value, which thereby necessitated arithmetic. But yes, if
you had, instead, in a problem involving credit card numbers, gotten the human's
input as a long string of characters and not as an actual number like an int or a
long, then, yes, you could actually get at those individual characters, which
probably would have made things even easier but deliberate. Yeah. AUDIENCE:
[INAUDIBLE]. DAVID J. MALAN: Really good question. If we're defining string in
CS50, are
we redefining it in string? No. So string, even though it's named string.h,
doesn't actually define something called a string. It just has string-related
functions. More on that soon. Yeah. AUDIENCE: [INAUDIBLE] individual values
[INAUDIBLE]?? DAVID J. MALAN: Ah, really good question. Could you edit the
individual values? So short answer, yes. We could absolutely change values, and
we'll soon do that in another context. Other questions? All right, so turns out
this is correct, if my goal is to print out all of the characters in Zamyla's name,
but it's not the best design. And this one's a little subtle, but this is, again,
what we mean by design. And to a question that came up during the break, did we
expect everyone to be writing good style and good design last week? No. Up until
today, like we've introduced the notion of correctness in both Scratch and in C
last week, but now we're introducing these other axes of quality of code like
design, how well-designed it is, and how pretty does it look in the context of
style. So expectations are here on out meant to be aligned with those
characteristics, but not in the past. So there's a slight inefficiency here. So on
the first iteration of this loop, I first initialize i to 0, and then I check if i
less than the length of the string, which hopefully, it is, if it's Zamyla, which
is longer than 0. Then I print the i-th character. Then I increment i. Then I check
this condition. Then I print the i-th character. Then I increment i. Then I check
this condition and so forth. We looped through loops last week, and you've used
them, perhaps, by now in problems. What question am I redundantly asking seemingly
unnecessarily? I have to check a condition again and again, because i is getting
incremented. But there's another other question that I don't need to keep asking
again just to get the same answer. AUDIENCE: What is the length [? of the
string? ?] DAVID J. MALAN: Yeah, there's this function call in my loop of strlen s,
which is fine. This is correct. I'm checking the length of the string, but once I
type in Zamyla, her name is not changing in length. I'm incrementing i, so I'm
moving in the string, if you will. But the string itself, Z-A-M-Y-L-A, is not
changing. So why am I asking the computer, again and again, get me the strlen of s,
get me the strlen of s, get me the strlen of s. So I can actually fix this. I can
improve the design, because that must take some amount of time. Maybe it's fast,
but it's still a non-zero amount of time. So you know what I could do? I could do
something like this-- int n get string length of s. And now just do this. This
would be better design, because now I'm only asking the question once of the
function. I'm remembering or caching, if you will, the answer, and then I'm just
using a variable. And just comparing variables is just faster than comparing a
variable against a function, which has to be called, which has to return a value,
which you can then compare. But honestly, it doesn't have to be this verbose. We
can actually be a little elegant about this. If you're using a loop, a secret
feature of loops is that you can have commas after declaring variables. And you can
actually do this and make this even more elegant, if you will, or more confusing-
looking, depending on your perspective. But this now does the same thing but
declares n inside of the loop, just like I'm declaring i, and it's just a little
tighter. It's one fewer lines of code. Any questions, then? AUDIENCE: [INAUDIBLE].
DAVID J. MALAN: Good question. In the way I've just done it cannot reuse this
outside of the curly braces. The scope of i and n exists only in this context right
now. The other way, yes. I could have used it elsewhere. AUDIENCE: What if you
[INAUDIBLE] other loops, and you also had [INAUDIBLE]?? DAVID J. MALAN: Absolutely.
AUDIENCE: Using different letters of the alphabet, you could just use n and not be
[INAUDIBLE].. DAVID J. MALAN: Correct. If I want to use the length of s again,
absolutely. I can declare the variable, as I did earlier, outside of the loop, so
as to reuse it. That's totally fine. Yes. And even i-- i exists only inside of this
loop, so if I have another loop, I can reuse i, and it's a different i, because
these variables only exist inside the for loop in which they're declared. So it
turns out that these strings don't have anything in them other than character after
character after character. And in fact, let me go ahead here and draw a picture of
what's actually going on underneath the hood of the computer here. So when I type
in Zamyla's name, I'm, of course, doing something like Z-A-M-Y-L-A. But where is
that actually going? Well, we know now that inside of your computer is RAM or
memory, and you can think of it like a grid. And honestly, I can think of this
whole screen as just being in a different orientation, a grid of memory. So for
instance, maybe we can divide it into rows and columns like this, not necessarily
to scale, and there's more rows and columns. So on the screen here, I'm just
dividing things into the individual bytes of memory that we saw a moment ago. And
so, indeed, underneath the hood of the computer is this layout of memory. The
compiler has somehow figured out or the program has somehow figured out where to
put the z and where the a and the m and the y and the l and the a, but the key is
that they're all contiguous, back to back to back. But the catch is if I'm typing
other words into my program or scores into my program or any data into my program,
it's going to end up elsewhere in the computer's memory. So how do you know where
Zamyla begins and where Zamyla ends, so to speak, in memory? Well, the variable,
called s, essentially is here. There's some remembrance in the computer of where s
begins. But there's no obvious way to know where Zamyla ends, unless we ourselves
tell the computer. So unbeknownst to us, any time a computer is storing a string
like Z-A-M-Y-L-A, it turns out that it's not using one, two, three, four, five, six
characters. It's actually using seven secretly. It's actually putting a special
character of all zeros in the very last bytes. Every byte is eight bits, so it's
putting secretly eight zeros there, or we can actually draw this more
conventionally as /0. It's what's called the null character, and it just means all
zeros. So the length of the string, Zamyla, is six, but how many bytes does it
apparently take up, just to be clear? So it actually takes up seven. And this is
kind of a secret implementation detail that we don't really have to care about, but
eventually, we will, because if we want to implement certain functionality, we're
going to need to know what is actually going on. So for instance, let me go ahead
and do this. Let me go ahead and create a program called strlen itself. So this is
not a function but a program called strlen.c. Let me go ahead and include the CS50
library at the top. Let me go ahead and include stdio.h. Let me go ahead and type
out main void, so all this is same as always. And then let me go ahead and prompt
the user for, say, his or her name, like so. And then you know what? Let me
actually, this time, not just print their name out, because we've done that ad
nauseam. Let's just count the number of letters in his or her name. So how could we
do that? Well, we could just do this-- int n get strlen of s, and then say, printf
"The length of your name is %i." And then we can plug in n, because that's the
number we stored the length in. But to use strlen, I have to include what header
file? String.h, which is the new one, so string.h. And now if I type this all
correctly, make strlen, make strlen, good. ./strlen-- let's try it-- Zamyla. Enter.
OK, the length of her name is six. But what is strlen doing? Well, strlen is just
an abstraction for us that someone else wrote, and it's wonderfully convenient, but
you know, we don't strictly need it. I can actually do this myself. If I understand
what the computer is doing, I can implement this same functionality myself as
follows. I can declare a variable called n and initialize it to 0, and then you
know what? I'm going to go ahead and do this. While s bracket n does not equal all
zeros, but you don't write all zeros like this. You literally do this-- that /0 to
which I referred earlier in single quotes. That just means all zeros in the bytes.
And now I can go ahead and do n++. If I'm familiar with what this means, remember,
that this is just n equals n plus 1, but it's just a little more compact to say, n+
+. And then I can print out the name of your n-- the name of your n-- the name of--
the length of your name is %i, plugging in n. So why does this work? It's a little
funky-looking, but this is just demonstrating an understanding of what's going on
underneath the proverbial hood. If n is initialized to zero, and I look at s
bracket n, well, that's like looking at s bracket 0. And if the string, s, is
Zamyla, what is s bracket 0? Z. And then it does not equal /0. It equals z,
obviously. So we increment n. So now n is 1. Now n is 1. So what is s bracket 1 in
Zamyla's name? A and so forth, and we get to Z-A-M-Y-L-A, then all zeros, the so-
called null character, or /0. That, of course, does equal /0, so the loop stops,
thereby leaving the total count or value of n at what it previously was, which was
6. So that's it. Like all underneath the hood, all we have is memory laid out like
this, top to bottom, left to right, and yet all of the functionality we've been
using for a week now and henceforth just boils down to some relatively simple
primitives, and if you understand those primitives, you can do anything you want
using the computer, both computationally code-wise, but also memory-wise. We can
actually see, in fact, some of the stuff we looked at two weeks ago as follows. Let
me go ahead and open up an example called
ASCII 0. Recall that ASCII is the mapping between letters and numbers in a
computer. And notice what this program's going to do. Make-- let me go into this
folder. Make ascii0, ./ascii0, Enter. The string shall be, let's say, Zamyla,
Enter. Well, it turns out that if you actually look up the ASCII code for Zamyla's
name, z is 90, lowercase a is 97, m is 109, and so forth. There are those
characters, and actually, we can play the same game we did last week. If I do this
again on "hi," there's your 72, and there's your 73. Where is this coming from?
Well, now that I know how to manipulate individual strings, notice what I can do. I
can get a string from the user, just as we always have. I can iterate over the
length of that string, albeit inefficiently using strlen here. And then notice this
new feature today. I can now convert one data type to another, because a char, a
character is just eight bits, but presented in the context of characters. Bytes is
also just eight bits that you could treat as an integer, a number. It's totally
context-sensitive. If you use Photoshop, it's a graphic. If you use a text program,
it's a message and so forth. So you can encode-- change the context. So notice
here, s bracket i is, of course, the i-th character of Zamyla's name, so Z or A or
M or whatever. But I can convert that i-th character to an integer doing what's
called casting. You can literally, in parentheses, specify the data type you want
to convert one data type to, and then store it in exactly that data type. So s
bracket i-- convert it to a number. Then store it in an actual number variable, so
I can print out its value. So c-- this is show me the character. Show me the letter
as by plugging in the character, and then the letter-- sorry, the character and the
number that I've just converted it to. And you don't actually even have to be
explicit. This is called explicit casting. Technically, we can do this implicitly,
too. And the computer knows that numbers are characters, and characters are a
number. You don't have to be so pedantic and even do the explicit casting in
parentheses. You can just do it implicitly with data types, and honestly, at this
point, I don't even need the variable. I can get rid of this, and down here, I can
literally just print the same thing twice, but tell printf to print the first in
the context of a character and the second in the context of an int, just treating
the exact same bits differently. That's implicit casting. And it just demonstrates
what we did in week 0 when we claimed that letters are numbers, and numbers can
also be colors, and colors can be images, and so forth. Is this a question?
AUDIENCE: Would've been useful for credit. DAVID J. MALAN: Also, yes. It all comes
back to credit. Yeah. Indeed. Other questions? No. All right, so what else can we
actually do with this appreciation? So super simple feature that all of us surely
take for granted, if we even use it anymore these days. Google Docs, Microsoft
Word, and such can automatically capitalize words for you these days. I mean your
phone can do it nowadays. They just sort of AutoCorrect your messages. Well, how is
that actually working? Well, once you know that a string is just a bunch of
characters back to back to back, and you know that these characters have numbers
representing them, and like capital A is 65, and lowercase A is 97, apparently, and
so forth, we can leverage these patterns. If I go ahead and open up this other
example here called Capitalize 0, notice what this program is going to do for me
first by running it. Make capitalize 0 ./capitalize0. Let me go ahead and type in
Zamyla's name just as before, but now it's all capital. So this is a little
extreme. Hopefully, your phone is not capitalizing every letter, but you can
imagine it capitalizing just the first, if you wanted it. So how does this work?
Well, let me go ahead and open up this example here. And so what we did-- so here,
I'm getting a string from the user, just as we always do. Then I'm saying, after,
just to kind of format the output nicely. Here, I'm doing a loop pretty efficiently
from i equals 0 up to the length of the string. And now notice this neat
application of logic. It's a little cryptic, certainly, at first glance. But
whoops. And now it's gone. And what am I doing exactly with these lines of code?
Well, with every iteration of this loop, I'm asking the question, is the i-th
character of s, so the current character, is it greater than or equal to lowercase
A, and is it less than or equal to lowercase Z? Put another way, how do you say
that more colloquially in English? Is it lowercase, literally. But this is the more
programmatic way of expressing, is it lowercase? All right, if it is, go ahead and
do this. Now this is a little funky, but print out a character, specifically the i-
th character, but subtract from that lowercase letter whatever the difference is
between little A and big A. Now where did that come from? So it turns out-- OK,
capital A is 65. Lowercase A is 97. So the difference between those is 32. And
that's true for B, so capital B is 66, and lowercase B is 98. Still 32, and it
repeats for the whole alphabet. So I could just do this. If I know that lowercase
letters have bigger numbers, like 97, 98, and I know that lowercase numbers have
lower letters, like 65, 66, I can just literally subtract off 32 from my lowercase
letters. As you point out, it's a lowercase letter. Subtract 32, and that gives us
what result? The capitalized version. It uppercases things for us. But honestly,
this feels a little hackish that, like, OK, yes, I can do the math correctly, but
you know what? It's better practice, generally, to abstract this away. Don't get
into the weeds of counting how many characters are away from each other. Math is
cheap and easy in the computer. Let it do the math for you by subtracting whatever
the value of A is, of capital A is from the value of lowercase A. Or we could just
write 32. Otherwise, go ahead and just print the character unchanged. So in this
case, the A-M-Y-L-A in Zamyla's name got uppercased, and everything else, the Z,
got left alone, just by understanding what's going on with how the computer's
represented. But honestly, God, I don't want to keep writing code like this. Like,
I'm never going to get this. I'm new to programming, perhaps. I'm never going to
get this sort of sequence of all the cryptic symbols together, and that's OK,
because we can actually implement this same program a little more easily, thanks to
functions and abstractions that others have written for us. So in this program,
turns out I can simplify the questions I'm asking by literally calling a function
that says, is lower. And there's another one called, is upper, and there's bunches
of others that just literally are called, is something or other. So is lower takes
an argument like the i-th character of s, and it just returns a bull-- true or
false. How is it implemented? Well, honestly, if we looked at the code that someone
else wrote decades ago for is upper, odds are-- or is lower-- odds are he or she
wrote code that looks almost like this. But we don't need to worry about that level
of detail. We can just use his or her function, but how do we do that? Turns out
that this function-- and you would only know this by having been told or Googling
or reading a reference-- is in a library called ctype.h. And you need the header
file called ctype.h in order to use it. And we'll almost always point you to
references and documentation to explain that to you. Toupper is another feature,
right? This math-- like, my god. I just want to uppercase a letter. I don't want to
really keep thinking about how far apart uppercase letters are from lowercase.
Turns out that in the C type library, there's another function called toupper that
literally does the exact same thing in the previous program we wrote. And so that,
too, is OK. But you know what? This feels a little verbose. It would be nice if I
could really tighten this program up. So how those toupper work? Well, it turns out
some of you might be familiar with CS50 Reference Online, our web-based app that we
have that helps you navigate available functions in C. Turns out that all of the
data for that application comes from an older command line program that comes in
Linux and comes in the sandbox called Man for manual. And anytime you type "man" at
the command prompt, and then the name of a function you're interested in, if it
exists, it will tell you a little something about it. So if I go to toupper, man
toupper, I get slightly cryptic documentation here. But notice, toupper and some
other functions convert uppercase or lowercase. That's the summary. Notice that in
the synopsis, the man page, so to speak, is telling me what header file I have to
include. Notice that under Synopsis, it's also telling me what the signature or
prototype is of the function. In other words, the documentation in Man, the Linux
programmer's manual, is very terse. So it's not going to hold your hand in this
black and white format. It's just going to convey, well, implicitly, you better put
this on top of your file. And by the way, this is how you use the function. It
takes an argument called C, returns a value of type int. Why is it int? Let me wave
my hands at that. It effectively returns a character for our purposes today. And if
we scroll down, OK, description. Ugh, I don't really want to read all of this, but
OK, here we go. If c is a lowercase letter, toupper returns its uppercase
equivalent, if an uppercase representation exists in the current locale. That just
means if it's punctuation, it's not going to do anything. Otherwise, it returns C,
And that's kind of the key detail. If I pass it lowercase A, it's going to give me
capital A, but if I pass it capital A, what's it going to give me? AUDIENCE:
Capital
A. DAVID J. MALAN: Also, capital A. It returns the original character, c. That's
the only detail I cared about. When in doubt, read the manual. And it might be a
little cryptic, and this is why CS50 Reference takes somewhat cryptic documentation
and tries to simplify it into more human-friendly terms. But at the end of the day,
these are the authoritative answers. And if I or one of the staff don't know, we
literally pull up the Man page or CS50 Reference to answer these kinds of
questions. Now what's the implication? I don't need any of this. I can literally
get rid of the condition and just let toupper do all of the legwork, and now my
program is so much more compact than the previous versions were, because I've read
the documentation. I know what the function does, and I can let toupper uppercase
something or just pass it through unchanged. We can better design, because we're
writing fewer lines of code that are just as clear, and so we can now actually
tighten things up. Any questions on this particular approach? All right. So we're
getting very low level. Now let's make these things more useful, because clearly,
other people have solved some of these problems for us, as by having these
functions and the C type library and the string library. What more is there? Well,
recall that every time we run Clang, or even run make, we're typing multiple words
at the command prompt. You're typing make hello or make Mario, a second word, or
you're typing clang-o, hello, hello.c, like lots of words at the prompt. Well, it
turns out that all this time, you're using, indeed, command line arguments. But in
C, you can write programs that also accept words and numbers when the user runs the
program. Think back, after all. When you ran Mario, you did ./mario, Enter. You
couldn't type any more words at the prompt. When you did credit, you did ./credit,
Enter. No more words at the prompt. You used get string or get long to get more
input, but not at the command line. And it turns out that we can, relatively
simply, in C, but it's a little cryptic at first glance. Let me go ahead and-- let
me go ahead and, here, pull up this signature here, which looks like this. This is
the function that we're all used to by now for writing a main function. And up
until now, we've said void. Main doesn't take any inputs, and indeed, it just runs.
But it turns out if you change your existing programs or future programs, not to
say void, but to say, int argc, string argv, it's a little cryptic at first glance.
But what's a recognizable symbol now? Yeah, there's brackets here. So it turns out
that every time you write a program, if you don't just say void, you actually
enable this feature by writing int argc, string argv. You can actually tell Clang,
you know what? I want this program to accept one or more words or numbers after the
name of the program, so I can do ./hellodavid, or ./hellozamyla. I don't have to
wait for the program to be running to use string. And just as with the earlier
example, where you were able to chart an array, main is defined as taking an array,
called argv historical reasons-- argument vector. Vector means array. Argument
vector, bracket, closed bracket just means this is-- this contains one or more
words, each of which is a string. Argc is argument count, so this is the variable
that main gets access to that tells it how many arguments, how many strings are
actually in argv. So how can we use this in a useful way? Well, let me go ahead
here and open up the sandbox. And let me go ahead and create a new file called,
say, argv0, argv0.c-- again, argument vector, just list or array of arguments. And
let me go ahead and, as usual, include cs50.h, include stdio.h, and then int main
not void, but int argc, string argv-- argv-- open bracket, closed bracket. And even
if that doesn't come naturally at first, it will eventually. And I'm going to do
this. If the number of arguments passed in equals 2, then I'm going to go ahead and
do this-- printf, hello %s, comma, and here in the past, I've typed a variable
name. And I now actually have access to a variable. Go ahead and do argv bracket 1.
Else, if the user does not type, apparently, two words, let me go ahead and just by
default, say, hello world, as we always have. Now why-- what is this doing, and how
is it doing it? Well, let's quickly run it. So make-- whoops. Make argv0, ./argv0,
Enter, Hello World. But if I do Hello-- or dot-- the program would be better named
if we called it Hello, but Zamyla, Enter. Hello Zamyla. If I change it to David,
now I have access to David. If I had David Malan, no. It doesn't support that. So
what's going on? If you change main in any program write to take these two
arguments, argc and argv of type string int and then an array of strings, argc
tells you how many words were typed at the prompt. So if the human typed two words,
I presume the first word is the name of the program, dot slash argv0, the second
word is presumably my name, if he or she is actually providing their name at the
prompt. And so I print out argv bracket 1. Not 0 because that's the name of the
program, but argv bracket 1. Else, down here, if the human doesn't provide just
Zamyla, or just David, or just one word more generally, I just print the default,
"Hello world." But what's neat about this now is notice that argv is an array of
strings. What is a string? It's an array of characters. And so let's enter just one
last piece of syntax that gets kind of powerful here. Let me go ahead and do this.
Let me go ahead and, in a new file here, argv 1 dot c. Let me go ahead and paste
this in. Close this. Let me go ahead and do this. Rather than do this logical
checking, let me do this, for-- let's say for int, i get 0. i is less than argc--
i++. Let's go ahead and, one per line, print out every word that the human just
typed, just to reinforce that this is indeed what's going on. So argv bracket 0,
save. Make argv 1, enter. And now let's go ahead and run this program-- dot slash,
argv 1, David Malan. OK, you see all three words. If we change it to Zamyla, we see
just those two words. If we change it to Zamyla Chan, we see those three words. So
we clearly have access to all of the words in the array, but let's take this one
step further. Rather than just print out every word in a string, let's go ahead and
do this. For intj get 0. n equals the string length of the current argument, like
this-- j is less than n, j++-- oops, oops, oops-- j++. Now let me go ahead and
print out not the full string, but let me do-- oops, oops-- let me go ahead and
print out this-- not a string, but a character, n bracket i bracket j, like this.
All right. So what's going on? One, this outer loop, and let's comment it, iterate
over strings in argv. This inner loop, iterate over chars in argv bracket i. So the
outer loop iterates over all of the strings in argv. And the inner loop, using a
different variable, starting at 0, iterates over all of the characters in the ith
argument, which itself is a string. So we can call string length on it. And then we
do this up until n, which is the length of that string. And then we print out each
character. So just to be clear-- when I run arv1 and correct it, at first glance,
why it's implicitly declaring library function sterling, what's almost always the
solution when you do this wrong? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: Yeah. So I
forgot this, so include string.h and help50 would help with that as well. Let's
recompile with make argv1. All right. When I run argv1, of, say, Zamyla Chan, what
am I going to see? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: Yeah. Is that the right
intuition? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: I'm going to see Zamyla Chan,
but-- AUDIENCE: [INAUDIBLE] DAVID J. MALAN: One character on each line, including
the program's name. So in fact, let me scroll this up so it's a little bigger.
Enter. OK, it's a little stupid, the program, but it does confirm that using arrays
do I have access not only to the words, but I can kind of have the second
dimension. And within each word, I can get at each character within. And we do
this, again, just by using not just single square brackets, but double. And again,
just break this down into the first principles. What is this first bracket? This is
the ith argument, the ith string in the array. And then if you take it further,
with bracket j, that gives you the j character inside of this. Now, who cares about
any of this kind of functionality? Well, let me scroll back and propose one
application here. So recall that CS is really just problem solving. But suppose the
problem that you want to solve is to actually pass a secret message in class or
send someone a secret for whatever reason. Well, the input to that problem is
generally called plain test, a message you want to send to that other person. You
ideally want ciphertext to emerge from it, which is enciphered and scrambled,
somehow encrypted information so that anyone in the room, like the teacher, can't
just grab the note and read what you're sending to your secret crush or love across
the room, or in any other context as well. But the problem is that if the message
you want to send, say, is our old friend Hi!, with an exclamation point, you can
encode it in certain contexts as just 72, 73, 33. And I daresay most classes on
campus if you wrote on a piece of paper 72, 73, 33, passed it through the room, and
whatever professor intercepts it, they're not going to know what you're saying
anyway. But this is not a good system. This is not a cryptosystem. Why? It's not
secure. [INAUDIBLE] [INTERPOSING VOICES] DAVID J. MALAN: Yeah. Anyone has access to
this, right, so long as you attend like week 1 or 0 of CS50, or you just have
general familiarity with Ascii. Like this is just a code. I mean Ascii is a system
that maps letters to numbers. And anyone else who knows
this code obviously knows what your message is, because it's not a unique secret
to you and the recipient. So that's probably not the best idea. Well, you can be a
little more sophisticated. And this is back-- actually, a photograph from World War
I of a message that was sent from Germany to Mexico that was encoded in a very
similar way. It wasn't using Ascii. The numbers, as you can perhaps glean from the
photo, are actually much larger. But in this system, in a militaristic context,
there was a code book. So similar in spirit to Ascii, where you have a column of
numbers and a column of letters to which they correspond, a codebook more generally
has like numbers, and then maybe even letters or whole words that they correspond
to, sometimes thousands of them, like literally a really big book of codes. And so
long as only, in this context the Germans and the recipients, the Mexicans, had
access to that same book, only they could encrypt and decrypt, or rather encode and
decode information. Of course, in this very specific context-- you can read more
about this in historical texts-- this was intercepted. This message, seemingly
innocuous, though definitely suspicious looking with all these numbers, so
therefore not innocuous, the British, in this case actually, intercepted it. And
thanks to a lot of efforts and cryptanalysis, the Bletchley Park style code
breaking, albeit further back, were they able to figure out what those numbers
represented in words and actually decode the message. And in fact, here's a
photograph of some of the words that were translated from one to the other. But
more on that in any online or textual references. Turns out in this poem too there
was a similar code, right? So apropos of being in Boston here, you might recall
this one. "Listen my children, and you shall hear of the midnight ride of Paul
Revere. On the 18th of April in '75, hardly a man is now alive who remembers that
famous day and year. He said to his friend, if the British march by land or sea
from the town tonight night, hang a lantern aloft in the belfry arch of the North
Church tower as a signal light, one if by land, and two if by sea. And I on the
opposite shore will be ready to ride and spread the alarm through every Middlesex
village and farm for the country folk to be up and to arm." So it turns out some of
that is not actually factually correct, but the one if by land and the two if by
sea code were sort of an example of a one-time code. Because if the revolutionaries
in the American Revolution kind of decided secretly among themselves literally
that-- we will put up one light at the top of a church if the British are coming by
land. And we will instead use two if the British are instead coming by sea. Like
that is a code. And you could write it down in a book, unless you have a code book.
But of course, as soon as someone figures out that pattern, it's compromised. And
so code books tend not to be the most robust mechanisms for encoding information.
Instead, it's better to use something more algorithmic. And wonderfully, in
computer science is this black box to-- we keep saying, the home of algorithms. And
in general, encryption is a problem with inputs and outputs, but we just need one
more input. The input is what's generally called the key, or a secret. And a secret
might just be a number. So for instance, if I wanted my secret to be 1, because
we'll keep the example simple, but it could really be any number. And indeed, we
saw with the photograph a moment ago, the Germans used much larger than this,
albeit in the context of codes. Suppose that you now want to send a more private
message to someone across the room in a class that, I love you. How do you go about
encoding that in a way that isn't just using Ascii and isn't just using some simple
code book? Well, let me propose that now that we understand how strings are
represented, right-- we're about to make love really, really lame and geeky-- so
now that you know how to express strings computationally, well, let's just start
representing "I love you" in Ascii. So I is 73. L is 76. O-V-E Y-O-U. That's just
Ascii. Should not send it this way, because anyone who knows Ascii is going to know
what you're saying. But what if I enciphered this message, I performed an algorithm
on it? And at its simplest, an algorithm can just be math-- simple arithmetic, as
we've seen. So you know, let me just use my secret key of 1. And let me make sure
that my crush knows that I am using a secret value of 1. So he or she also knows to
expect that value. And before I send my message, I'm going to add 1 to every
letter. So 73 becomes 74. 76 becomes 77. 80, 87, 70, 90, 80, 86. Now this could
just be sent in the clear. But then, I could actually send it as a textual message.
So let's convert it back to Ascii. 74 is now J. 77 is now M. 80 is now P. And you
can perhaps see the pattern. This message was, I love you. And now, all of the
letters are off by one, I think. I became J. L became M. O became P, and so forth.
So now the claim would be, cryptographically, I'm going to send this message across
the room. And now no one who has a code book is going to be able to solve this. I
can't just steal the book and decode it, because now the key is only up here, so to
speak. It's just the number 1 that he or she and I had to agree upon in advance
that we would use for sending our secret messages. So if someone captures this
message, teacher in the room or whoever, how would they even go about decoding this
or decrypting it? Are there any techniques available to them? I daresay we can kind
of chip away at this love note. AUDIENCE: [INAUDIBLE] DAVID J. MALAN: What's that?
Guess and check. OK, we could try all-- there still kind of some spacing. So you
know honestly, we could do like kind of a cryptanalysis of it, a frequency attack.
Like, I can't think of too many words in English that have a single letter in them.
So what does J probably represent? [INTERPOSING VOICES] DAVID J. MALAN: I,
probably. Maybe A, but probably I. And there's not too many other options. So we've
attacked one part of the message already. I see a commonality. There's two what in
here? Two P. And I don't necessarily know that that maps to O, but I do know it's
the same character. So if I kind of continue this thoughtful process or this trial
and error, and I figure out, oh, what if that's an O? And then that's an O. And
then wait a minute. They're passing from one to another. Maybe this says, I love
you. Like you actually can, with some probability, decrypt a message by doing this
kind of analysis on it. It's at least more secure than the code book, because
you're not compromised if the book itself is stolen. And you can change the key
every time, so long as you and the recipient actually agree on something. But at
least we now have this mechanism in place. So with just the understanding of what
you can do with strings, can you actually now do really interesting domain-specific
things to them? And in fact, back in the day, Caesar, back in militaristic times
literally used a cipher quite like this. And frankly, when you're the first one to
use these ciphers, they actually are kind of secure, even if they're relatively
simple. But hopefully, not just using a key of 1, maybe 2, or 13, or 25, or
something larger. But this is an example of a substitution cipher, or a rotational
cipher where everything's kind of rotating-- A's becoming B, B's becoming C. Or you
can kind of rotate it even further than that. Well, let's take a look at one last
example here of just one other final primitive of a feature today, before we then
go back high level to bring everything together. It turns out that printing out
error messages is not the only way to signal that something has gone wrong. There's
a new keyword, a new use of an old keyword in this example, that's actually a
convention for signaling errors. So this is an example called exit.c. It apparently
wants the human to do what, if you infer from the code? AUDIENCE: Exit [INAUDIBLE].
DAVID J. MALAN: Yes. Say again? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: Well, it
wants the-- well, what does it what the human to do implicitly, based on the
printf's here? How should I run this program? Yeah? AUDIENCE: [INAUDIBLE] just
apply [INAUDIBLE].. DAVID J. MALAN: Yeah. So for whatever reason, this program
implicitly wants me to write exactly two words at the prompt. Because if I don't,
it's going to yell at me, missing command line argument. And then it's going to
return 1, whatever that is. Otherwise, it's going to say, Hello, such and such. So
if I actually run this program-- let me go back over here and do make exit-- oops--
in my directory, make exit. OK, dot slash exit, enter, I'm missing a command line
argument. All right, let me put Zamyla's name. Oh, Hello Zamyla. Let me put Zamyla
Chan. Nope, missing command line argument. It just wants the one, so in this case
here. I'm seeing visually the error message, but it turns out the computer is also
signaling to me what the so-called exit code is. So long story short, we've already
seen examples last week of how you can have a function return a value. And we saw
how [? Erin ?] came up on stage, and she returned to me a piece of paper with a
string on it. But it turns out that main is a little special. If main returns a
value like 1 or 0, you can actually see that, albeit in a kind of a non-obvious
way. If I run exit, and I run it correctly with Zamyla as the name, if I then type
echo, dollar sign, question mark, of all things, enter, I will then see exactly
what main returned with, which in this case is 0. Now, let me try and be
uncooperative. If I actually run just dot slash exit, with no word, I see, missing
command line argument. But if I do the same cryptic command, echo, dollar sign,
question mark, I see that main exited with 1. Now, why is this
useful? Well, as we start to write more complicated programs, it's going to be a
convention to exit from main by returning a non-zero value, if anything goes wrong.
0 happens to mean everything went well. And in fact, in all of the programs we've
written thus far, if you don't mention return anything, main automatically for you
returns 0. And it has been all this time. It's just a feature, so you don't have to
bother typing it yourself. But what's nice about this, or what's real about this,
is if on your Mac or PC, if you've ever gotten an annoying error message that says,
error negative 29, system error has occurred, or something freezes, but you very
often see numbers on the screen, maybe. Like those error codes actually tend to map
to these kinds of values. So when a human is writing software and something goes
wrong and an error happens, they typically return a value like this. And the
computer has access to it. And this isn't all that useful for the human running the
program. But as your programs get more complex, we'll see that this is actually
quite useful as a way of signaling that something indeed went wrong. Whew. OK,
that's a lot of syntax wrapped in some loving context. Any questions before we look
at one final domain? No? All right. So it turns out that we can answer the "who
cares" question in yet another way too. It turns out-- let me go ahead and open up
an example of our array again here-- that arrays can actually now be used to solve
problems more algorithmically. And this is where life gets more interesting. Like
we were so incredibly in the weeds today. And as we move forward in the class,
we're not going to spend so much time on syntax, and dollar signs, and question
marks, and square brackets, and the like. That's not the interesting part. The
interesting part is when we now have these fundamental building blocks, like an
array, with which we can solve problems. So it turns out that an array, you know,
you can kind of think of it as a series of lockers, a series of lockers that might
look like this, inside of which are values-- strings, or numbers, or chars, or
whatnot. But the lockers is an apt metaphor because a computer, unlike us humans,
can only see and do one thing at a time. It can open one locker and look inside,
but it can't kind of take a step back, like we humans can, and look at all of the
lockers, even if all of the doors are open. So it has to be a more deliberate act
than that. So what are the actual implications? Well, all this time-- we had that
phone book example in the first week, and the efficiency of that algorithm, of
finding Mike Smith in this phone book, all assumed what feature of this phone book?
AUDIENCE: That it's ordered alphabetically. DAVID J. MALAN: That it was ordered
alphabetically. And that was a huge plus, because then I could go to the middle,
and I could go to the middle of the middle, and so forth. And that was an
algorithmic possibility. On our phones, if you pull up your contacts, you've got a
list of first names, or last names, all alphabetically sorted. That is because,
guess what data structure or layout your phone probably uses to store your
contacts? It's an array of some sort, right? It's just a list. And it might be
displayed vertically, instead of horizontally, as I've been drawing it today. But
it's just values that are back, to back, to back, to back, to back, that are
actually sorted. But how did they actually get into that sorted order? And how do
you actually find values? Well, let's consider what this problem is actually like
for a computer, as follows. Let me go ahead here. Would a volunteer mind joining us
up here? I can throw in a free stress ball. OK, someone from the back? OK, come on
up here. Come on. What's your name? ERIC: Eric. DAVID J. MALAN: Aaron. All right.
So Aaron's going to come on up. And-- ERIC: Eric. DAVID J. MALAN: I'm sorry? Oh,
Eric. Nice to meet you. All right. Come on over here. So Eric, now normally, I
would ask you to find the number 23. But seeing is that's a little easy, can you go
ahead and just find us the number 50 behind these doors, or really these yellow
lockers? 8? Nope. 42? Nope. OK. Pretty good. That's three, three out of seven. How
did you get it so quickly? ERIC: I guessed. DAVID J. MALAN: OK, so he guessed. Is
that the best algorithm that Eric could have used here? ERIC: Probably not. DAVID
J. MALAN: Well, I don't know. Yes? No? AUDIENCE: Yeah. DAVID J. MALAN: Why? Why
yes? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: He has no other information. So yes,
like that was the best you can do. But let me give you a little more information.
You can stay here. And let me go ahead and reload the screen here. And let me go
ahead and pull up a different set of doors. And now suppose that, much like the
phone book, and much like the phones are sorted, now these doors are sorted. And
find us the number 50. All right. So good. What did you do that time? AUDIENCE:
Well, [INAUDIBLE]. It was 50 is 116. So I just-- DAVID J. MALAN: Right. So you
jumped to the middle, initially, and then to the right half. And then technically--
so we're technically off by 1, right? Because like binary search would have gone to
the middle of the-- that's OK, but very well done to Eric. Here, let me at least
reinforce this with a stress ball. So thank you. Very well done. So with that
additional information, as you know, Eric was able to do better because the
information was sorted on the screen. But he only had one insight to a locker at a
time, because only by revealing what's inside can he actually see it. So this seems
to suggest that once you do have this additional information in Eric's example, in
your phone example, in the phone book example, you open up possibilities for much
much, much more efficient algorithms. But to get there, we've kind of been
deferring this whole time in class how you actually sort these elements. And if you
wouldn't mind-- and this way, we'll hopefully end on a more energized note here
because I know we've been in the weeds for a while-- can we get like eight
volunteers? OK, so 1, 2, 3, 4-- how about 5, 6, 7, 8, come on down. Oh, I'm sorry.
Did I completely overlook the front row? OK. All right, next time. Next time. Come
on down. Oh, and Colton, do you mind meeting them over there instead? All right.
Come on up. What's your name? [? CAHMY: ?] [? Cahmy. ?] DAVID J. MALAN: [?
Cahmy? ?] David. Right over there. What's your name? MATT: Matt. DAVID J. MALAN:
Matt? David. [? JUHE: ?] [? Juhe. ?] DAVID J. MALAN: [? Juhe? ?] David. MAX: Max.
DAVID J. MALAN: Max, nice to meet you. JAMES: James. DAVID J. MALAN: James, nice to
see you. Here, I'll get more chairs. What's your name? ,PEYTON: Peyton. DAVID J.
MALAN: Peyton? David. And two more. Actually can what have you come down to this
end here? What's your name. ANDREA: Andrea. DAVID J. MALAN: Andrea, nice to see
you. And your name? [? PICCO: ?] [? Picco. ?] DAVID J. MALAN: [? Picco, ?] David.
Nice to see you. OK, Colton has a T-shirt for each of you, very Harvard-esque here.
And each of these shirts, as you're about to see, has a number on it. And that
number is-- well, go ahead put them on, if you wouldn't mind. OK, thank you so
much. So I daresay we've arranged our humans much like the lockers in an array.
Like we have humans back, to back, to back, to back. But this is actually both a
blessing and a constraint, because we only have eight chairs. So there's really not
much room here, so we're confined to just this space here. And I see we have a 4,
8, 5, 2, 3, 1, 6, 7. So this is great. Like they are unsorted. By definition, it's
pretty random. So that's great. So let's just start off like this. Sort yourselves
from 1 to 8, please. OK. All right. Well, what algorithm was that? [LAUGHTER]
AUDIENCE: Look around, figure it out. DAVID J. MALAN: Look around, figure it out.
OK, well-- MATT: Human ingenuity. DAVID J. MALAN: Human ingenuity? Very well done.
So can we-- well, what was like a thought going through any of your minds? MATT:
Find a chair and sit down. DAVID J. MALAN: Find the chair-- find the right chair.
So go to a location. Good. So like an index location, right? Arrays have indices,
so to spea-- 0, 1, 2, all the way up to 7. And even though our shirts are numbered
from 1 to 8, you can think in terms of 0 to 7. So that was good. Anyone else? Other
thoughts? [? CAHMY: ?] I mean, this is something we implicitly think of, but no one
told us that it was ordered right to left. Like we could have done it left to
right. DAVID J. MALAN: OK. Absolutely. Could have gone from right to left, instead
of left to right. But at least we all agreed on this convention too, so that was in
your mind. OK. So good. So we got this sorted. Go ahead and re-randomize yourself,
if you could. And what algorithm was this? Just random awkwardness? OK, so that's
fine. So it looks pretty random. That will do. Let's see if we can now reduce the
process of sorting to something a little more algorithmic so that, one, we can be
sure we're correct and not just kind of get lucky that everyone kind of figured it
out and no one was left out, and two, then start to think about how efficient it
is, right? Because if we've been gaining so much efficiency for the phone book, for
our contacts, for [? error ?] coming up, we really should have been asking the
whole time, sure, you save time with binary search and divide and conquer, but how
much did it cost you to get to a point where you can use binary search and divide
and conquer? Because sorting, if it's super, super, super expensive and time-
consuming maybe it's a net negative. And you might as well just search the whole
list, rather than ever sort anything. All right. So let's see here. 6 and 5, I
don't like this. Why? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: 6 is supposed to come
after 5. And so, can we fix this, please? All right. And then let's see.
OK, 6 and 1-- ugh, don't really like this. Yeah, can we fix this? Very nice. 6 and
3, OK, you really got the short end of the stick here. So 6 and 3, could we fix
this? And 6-- yeah, OK. Ooh, OK, 6 and 7-- good. All right, so that's pretty good.
7 and 8, nice. 8 and 4, sorry. Could we switch here? All right. And then 8 and 2?
OK, could we switch here? OK. And let me ask you a somewhat rhetorical question.
OK, am I done? OK, no. Obviously not, but I did fix some problems, right? I fixed
some transpositions, numbers being out of order. And in fact, I-- what's your name
again? [? CAHMY: ?] [? Cahmy. ?] DAVID J. MALAN: [? Cahmy, ?] kind of bubbled to
the right here, if you will. Like you were kind of farther down, and now you're
over here. And like the smaller numbers, kind of-- yeah 1. Like, my god, like he
kind of bubbled his way this way. So things are percolating, in some sense. And
that's a good thing. And so you know what? Let Me try to fix some remaining
problems. So 1 and 5-- good. Oh 3 and 5, could you switch? 5 and 6, OK. 6 and 7? 7
and 4, could you switch? OK. And 7 and 2, could you switch? And now, I don't have
to speak with [? Cahmy ?] again, because we know you're in the right place. So I
actually don't have to do quite as much work this time, which is kind of nice. But
am I done? No, obviously not. But what's the pattern now? Like what's the
fundamental primitive? If I just compare pairwise humans and numbers, I can
slightly improve the situation each time by just swapping them, swapping them. And
each time now-- I'm sorry, [? Picco ?] is in number 7's place. I don't have to talk
to him anymore, because he's now bubbled his way all the way up to the top. So even
though I'm doing the same thing again and again, and looping again and again isn't
always the best thing, so long as you're looping fewer and fewer times, I will
eventually stop, it would seem. Because 6 is going to eventually go in the right
place, and then 5, and then 4, and so forth. So if we can just finish this
algorithm. Good. Good. Good. Not good. OK, 6 and 2, not good. If you could swap?
OK, and what's your name again? PEYTON: Peyton. DAVID J. MALAN: Peyton is now in
the right place. I have even less work now ahead of me. So if I can just continue
this process-- 1 and 3, 3 and 5, 4 and 5, OK, and then 2 and 5. And then, what's
your name again? MATT: Matt. DAVID J. MALAN: Matt is now in the right place. Even
less work. We're almost there. 1 and 3, 3 and 4, 4 and 2, if you could swap. OK,
almost done. And 1 and 3, 3 and 2, if you could swap. Nice. So this is interesting.
It would seem that-- you know, in the first place, I kind of compared seven pairs
of people. And then the next time I went through, I compared how many pairs of
people maximally? AUDIENCE: [INAUDIBLE] DAVID J. MALAN: Just six, right? Because we
were able to leave [? Cahmy ?] out. And then we were able to leave [? Picco ?] out,
and then Peyton. And so the number of comparisons I was doing was getting fewer and
fewer. So that feels pretty good. But you know what? Before We even analyze that,
can you just randomize yourselves again? Any human algorithm is fine. Let's try one
other approach, because this feels kind of non-obvious, right? I was fixing things,
but I had to keep fixing things again and again. Let me try to take a bigger bite
out of the problem this time by just selecting the smallest person. OK, so your
name again is? [? JUHE: ?] [? Juhe. ?] DAVID J. MALAN: [? Juhe, ?] number 2--
that's a pretty small number, so I'm going to remember that in sort of a mental
variable. 4? No, you're too big. Too big. Too big. Too big. Oh, what was your name
again? JAMES: James. DAVID J. MALAN: James. James is a 1. That's pretty nice. Let
me keep checking. OK, James, in my mental variable is the smallest number. I know I
want him at the beginning. So if you wouldn't mind coming with me. And I'm sorry,
we don't have room for you anymore. If you could just-- oh, you know what? Could
you all just shuffle down? Well, hm, I don't know if I like that. That's a lot of
work, right? Moving all these values, let's not do that. Let's not do that. Number
2, could you mind just going where-- where-- JAMES: It's James. DAVID J. MALAN:
--James was? OK, so I've kind of made the problem a little worse in that, now,
number 2 is farther away from the goal. But I could have gotten lucky, and maybe
she was number 7 or 8. And so let me just claim that, on average, just evicting the
person is going to kind of be a wash and average out. But now James is in the right
place. Done. Now I have a problem that's of size 7. So let me select the next
smallest person. 4 is the next smallest, not 8, not 5, not 7-- ooh, 2. Not 3, 6.
OK, so you're back in the game. All right, come on back. And can we evict number 4?
And on this algorithm, if you will, I just interpretively select the smallest
person. I'm not comparing everyone in quite the same way and swapping them
pairwise, I'm doing some of more macroscopic swaps. So now I'm going to look for
the next smallest, which is 3. If you wouldn't mind popping around here? [?
Cahmy, ?] we have to, unfortunately, evict you, but that works out to our favor.
Let me look for the next smallest, which is 4. OK, you're back in. Come on down.
Swap with 5. OK, now I'm looking for 5. Hey, 5, there you are. OK. So go here. OK,
looking for 6. Oh, 6, a little bit of a shuffle. OK. And now looking for 7. Oh, 7,
if you could go here. But notice, I'm not going back. And this is what's important.
Like my steps are getting shorter and shorter. My remaining steps are getting
shorter and shorter. And now we've actually sorted all of these humans. So two
fundamentally different ways, but they're both comparative in nature, because I'm
comparing these characters again, and again, and again, and swapping them if
they're out of order. Or at a higher level, going through and swapping them again,
and again, and again. But how many steps am I taking each time? Even though I was
doing fewer and fewer and I wasn't doubling back, the first time, I was doing like
n minus 1 comparisons. And then I went back here. And in the first algorithm, I
kind of stopped going as far. In the second algorithm, I just didn't go back as
far. So it was just kind of a different way of thinking of the problem. But then I
did what? Like seven comparisons? Then six, then five, then four, then three, then
two, then one. It's getting smaller, but how many comparisons is that total? I've
got like n people, n being a number. AUDIENCE: [INAUDIBLE] DAVID J. MALAN: Is not
as bad as factorial. We'd be here all day long. But it is big. It is big. Let's
go-- a round of applause, if we could, for our volunteers. You can keep the shirts,
if you'd like, as a souvenir. [APPLAUSE] Thank you, very much. Let me see if we
can't just kind of quantify that-- thank you, so much-- and see how we actually got
to that point. If I go ahead and pull up not our lockers, but our answers here, let
me propose that what we just did was essentially two algorithms. One has the name
bubble. And I was kind of deliberately kind of shoehorning the word in there.
Bubble sort is just that comparative sort, pair by pair, fixing tiny little
mistakes. But we needed to do it again, and again, and again. So those steps kind
of add up, but we can express them as pseudocode. So in pseudocode-- and you can
write this any number of ways-- I might just do the following. Just keep doing the
following, until there's no remaining swaps-- from i from 0 to n -2, which is just
n is the total number of humans. n -2 is go up from that person to this person,
because I want to compare him or her against the person next to them. So I don't
want to accidentally do this. That's why it's n -2 at the end here. Then I want to
go ahead and, if the ith and the ith +1 elements are out of order, swap them. So
that's why I was asking our human volunteers to exchange places. And then just keep
doing that, until there's no one left to swap. And by definition, everyone is in
order. Meanwhile, the second algorithm has the conventional name of selection sort.
Selection sort is literally just that, where you actually select the smallest
person, or number of interest to you, intuitively, again and again. And the number
keeps getting bigger, but you start ignoring the people who you've already put into
place. So the problem, similarly, is getting smaller and smaller. Just like in
bubble sort, it was getting more and more sorted. The pseudocode for selection sort
might look like this. For i from 0 to n -1, so that's 0 in an array. And this is n
-1. Just keep looking for the smallest element between those two chairs, and then
pull that person out. And then just evict whoever's there-- swap them, but not
necessarily adjacently, just as far away as is necessary. And in this way, I keep
turning my back on more and more people because they are then in place. So two
different framings of the problem, but it turns out they're actually both the same
number of steps, give or take. It turns out they're roughly the same number of
steps, even though it's a different way of thinking about it. Because if I think
about bubble sort, the first iteration, for instance, what just-- actually, well,
let's consider selection sort even. In selection sort, how many comparisons did I
have to do? Well, once I found my smallest element, I had to compare them against
everyone else. So that's n -1 comparisons the first time. So n -1 on the board.
Then I can ignore them, because they're behind me now. So now I have how many
comparisons left out of n people? n -2, because I subtracted one. Then again, n -3,
then n -4, all the way down to just one person remaining. So I'll express that sort
of generally, mathematically, like this. So n -1 plus n -2 plus whatever plus one
final comparison, whatever that is. It turns out that if you
actually read the back of the math book or your physics textbooks where they have
those little cheat sheets as to what these recurrences are, turns out that n -1
plus n -2 plus n -3 and so forth can be expressed more succinctly as literally just
n times n -1 divided by 2. And if you don't recall that, that's OK. I always look
these things up as well. But that's true-- fact. So what does that equal out to?
Well, it's like n squared minus n, if you just multiply it out. And then if you
divide the two, then it's n squared divided by 2 minus n over 2. So that's the
total number of steps. And I could actually plug this in. We could plug in 8, do
the math, and get the total number of comparisons that I was verbally kind of
rattling off. So is that a big deal? Hm, it feels like it's on the order of n
squared. And indeed, a computer scientist, when assessing the efficiency of an
algorithm, tends not to care too much about the precise values. All we're going to
care about it's the biggest term. What's the value in the formula that you come up
with that just dominates the other terms, so to speak, that has the biggest effect,
especially as n is getting larger and larger? Now, why is this? Well, let's just do
sort of proof by example, if you will. If this is the expression, technically, but
I claim that, ugh, it's close enough to say on the order of, big O of n squared, so
to speak, let's use an example. If there's a million people on stage, and not just
eight, that math works out to be like a million squared divided by 2 steps minus a
million divided by 2, total. So what does that actually work out to be? Well,
that's 500 billion minus 500,000. And what does that work out to be? Well, that's
499 billion, 999 million, 500,000. That feels pretty darn close to like n squared.
I mean, that's a drop in the bucket to subtract 500,000 from 500 billion. So you
know what? Eh, it's on the order of n squared. It's not precise, but it's in that
general order of magnitude, so to speak. And so this symbol, this capital 0, is
literally a symbol used in computer science and in programming to just kind of
describe with a wave of the hand, but some good intuition and algorithm, how fast
or slow your algorithm is. And it turns out there's different ways to evaluate
algorithms with just different similar formulas. n squared happens to be how much
time both bubble sort and selection sort take. If I literally count up all of the
work we were doing on stage with our volunteers, it would be roughly n squared, 8
squared, or 64 steps, give or take, for all of those humans. And that would be
notably off. There's a good amount of rounding error there. But if we had a million
volunteers on stage, then the rounding error would be pretty negligible. But we've
actually seen some of these other orders of magnitude, so to speak, before. For
instance, when we counted someone, or we searched for Mike Smith one page at a
time, we called that a linear algorithm. And that was big O of n. So it's on the
order of n steps. It's 1,000. Maybe it's 999. Whatever. It's on the order of n
steps. The [? twosies ?] approach was twice as fast, recall-- two pages at a time.
But you know what? That's still linear, right? Like two pages at a time? Let me
just wait till next year when my CPU is twice as fast, because Intel and companies
keep speeding up computers. The algorithm is fundamentally the same. And indeed, if
you think back to the picture we drew, the shapes of those curves were indeed the
same. That first algorithm, finding Mike one page at a time looked like this.
Second algorithm finding him looked like this. Only the third algorithm, the divide
and conquer, splitting the phone book was a fundamentally different shape. And so
even though we didn't use this fancy phrasing a couple of weeks ago, these first
algorithms, one page at a time, two pages at a time, eh, they're on the order of n.
Technically, yes, n versus n divided by 2, but we only care about the dominating
factor, the variable n. We can throw away everything in the denominator, and we can
throw away everything that's smaller than the biggest term, which in this case is
just n. And I alluded to this two weeks ago-- logarithmic. Well, it turns out that
any time you divide something again, and again, and again, you're leveraging a
logarithmic type function, log base 2 technically. But on the order of log base n
is a common one as well. The beautiful algorithms are these-- literally, one step,
or technically constant number of steps. For instance, like what's an algorithm
that might be constant time? Open phone book. OK, one step. Doesn't really matter
how many pages there are, I'm just going to open the phone book. And that doesn't
vary by number of pages. That might be a constant time algorithm, for instance. So
those are the lowest you can go. And then there's somewhere even in between here
that we might aspire to with certain other algorithms. So in fact, let's just see
if-- just a moment-- let's just see if we can do this a little more succinctly.
Let's go ahead and use arrays in just one final way, using merge sorts. So it turns
out, using an array, we can actually do something pretty powerfully, so long as we
allow ourselves a couple of arrays. So again, when we just add sorting with bubble
sort and selection sort, we had just one array. We had eight chairs for our eight
people. But if I actually allowed myself like 16 chairs, or even more, and I
allowed these folks to move a bit more, I could actually do even better than that
using arrays. So here's some random numbers that we'll just do visually, without
any humans. And they're in an array, back, to back, to back, to back. But if I
allow myself a second array, I'm going to be able to shuffle these things around
and not just compare them, because it was those comparisons and all of my footsteps
in front of them that really started to take a lot of time. So here's my array. You
know what? Just like the phone book-- that phone book example got us pretty far in
the first week-- let me do half of the problem at a time and then kind of combine
my answer. So here's an array-- 4, 2, 7, 5, 6, 8, 3, 1-- randomly sorted. Let me go
ahead and sort just half of this, just like I searched for Mike initially in just
half of the phone book. So 4, 2, 7, 5-- not sorted. But you know what? This feels
like too big of a problem, still. Let me sort just the left half of the left half.
OK, now it's a smaller problem. You know what? 4 and 2, still out of order. Let me
just divide this list of two into two tiny arrays, each of size 1. So here's a
mini-array of size 1, and then another one of like size 7, but they're back to
back, so whatever. But this array of size 1, is it sorted? AUDIENCE: No. DAVID J.
MALAN: I'm sorry? AUDIENCE: No. DAVID J. MALAN: No? If this array has just one
element and that element is 4-- AUDIENCE: There's only one thing you can do. DAVID
J. MALAN: Yes, then it is sorted, by definition. All right, so done. Making some
progress. Now, let me kind of mentally rewind. Let me sort the right half of that
array. So now I have another array of size 1. Is this array sorted? Yeah, kind of
stupidly. We don't really seem to be doing anything. We're just making claims. But
yes, this is sorted. But now, this was the original half. And this half is sorted.
This half is sorted. What if I now just kind of merge these sorted halves? I've got
two lists of size 1-- 4 and 2. And now if I have extra storage space, if I had like
extra benches, I could do this a little better. don't I go ahead and merge these
two as follows? 2 will go there. 4 will go there. So now I've taken two sorted
lists and made one bigger, more sorted list by just merging them together,
leveraging some additional space. Now, let me mentally rewind. How did I get to 4
and 2? Well, I started with the left half, then the left half of the left half. Let
me now do the right half of the left half, if you will. All right, let me divide
this again. 7, list of size 1, is it sorted? Yes, trivially. 5, is it sorted? Yes.
7 and 5, let's go ahead and merge them together. 5 is, of course, going to go here.
7, of course, is going to go here. OK. Now where do we go? We originally sorted the
left half. Let's go sort the right-- oh, right. Sorry. Now, we have the left half.
And the right half of the left half are sorted. Let's go ahead and merge these. We
have two lists now of size 2-- 2, 4 and 5, 7, both of which are sorted. If I now
merge 2, 4 and 5, 7, which element should come first in the new longer list,
obviously? 2. And then 4, then 5, and then 7. That wasn't much of anything. But OK,
we're just using a little more space in our array. Now what comes next? Now, let's
do the right half. Again, we started by taking the whole problem, doing the left
half, the left half of the left half, the left half of the left half of the left
half. And now we're going back in time, if you will. So let's divide this into two
halves, now the left half into two halves still. 6 is sorted. 8 is sorted. Now I
have to merge them-- 6, 8. What comes next? Right half-- 3 and 1. Well, left half
is sorted, right half is sorted-- 1 and 3. All right, now how do I merge these? 6,
8, 1, 3, which element should obviously come first? 1, then 3, then 6, then 8. And
then lastly, I have two lists of size four. Let me give myself a little more space,
one more array. Now let me go ahead and put 1, and 2, and 3, and 4, and 5, and 6,
and 7, and 8. What just happened? Because it actually happened a lot faster, even
though we were doing this all verbally. Well notice, how many times did each number
change locations? Literally three, right? Like one, two, three, right? It moved
from the original array, to the secondary array, to the tertiary array, to the
fourth array, whatever that's called. And then it was ultimately in place. So each
number had to move
one, two, three spots. And then how many numbers are there? AUDIENCE: [INAUDIBLE]
DAVID J. MALAN: Well, they were already in the original array. So how many times do
they have to move? Just one, two, three. So how many total numbers are there, just
to be clear? There's eight. So 8 times 3. So let's generalize this. If there's n
numbers, and each time we moved the numbers we did like half of them, than half,
then half, well, how many times can you divide 8 by 2? 8 goes to 4. 4 goes to 2. 2
goes to 1. And that's why we bottomed out at one element, lists of size 1. So it
turns out whenever you divide something by half, by half, by half, what is that
function or formula? Not power, that's bad. That's the other direction. AUDIENCE:
[INAUDIBLE] DAVID J. MALAN: It's a logarithm. So again, logarithm is just a
mathematical description for any function that you keep dividing something again,
and again, and again. In half, in half, in half, in third, in third, in third,
whatever it is, it just means division by the same proportional amounts again, and
again, and again. And so if we move the numbers three times, or more generally log
of n times, which again just means you divided n things again, and again, and
again, you just call that log n. And there's n numbers, so n numbers moved log n
times, the total arithmetic here in question is one of those other values on our
little cheat sheet, which looked like this. In our other cheat sheet, recall that
we had formulas that looked like this, not just n squared and n, and log n, and 1,
we have this one in the middle-- n times log n. So again, we're kind of jumping
around here. But again, each number moves log n places. There's n total numbers. So
n times log n is just, by definition, n log n. But why is this sorted this way?
Well log n, recall from week 0 with the phone book example, the green curve is
definitely smaller than n. n was the straight lines, log n was the green curved
one. So this indeed belongs in between, because this is n times n. This is n. This
is n times something smaller than n. So what's the actual implication? Well, if we
were to run these algorithms side by side and actually compare them with something
like this-- let me go ahead and compare these algorithms using this demo here-- if
I go ahead and hit play, we'll see that the bars in this chart are actually
horizontal. And the small bars represent small numbers, large bars represent long
numbers. And then each of these is going to run a different algorithm-- selection
sort on the left, bubble sort in the middle, merge sort, as we'll now call it, on
the right. And here's how long each of them take to sort those values. Bubble's
still going. Selection's still going. And so that's the appreciable difference,
albeit with a small demo, between n squared and something like log n. And so what
have we done here? We've really, really, really got into the weeds of what arrays
can actually do for us and what the relationships are with strings, because all of
it kind of reduces to just things being back, to back, to back, to back. But now
that we kind of come back, and we'll continue along this trajectory next time to be
able to talk at a much higher level about what's actually going on. And we can now
take this even further, by applying other sort of forms of media to these same
kinds of questions. And we'll conclude it's about 60 seconds long. These bars are
vertical, instead of horizontal. And what you'll see here is a visualization of
various sorting algorithms, among them selection sort, bubble sort, and merge sort,
and a whole assortment of others, each of which has even a different sound to it
because of the speed and the pattern by which it actually operates. So let's take a
quick look. [VIDEO PLAYBACK] [MUSIC PLAYING] This is bubble sort. And you can see
how the larger elements are indeed bubbling up to the top. [? And you can kind of
hear the ?] periodicity, or the cycle that it's going in. And there's less, and
less, and less, and less work to do, until almost-- This is selection sort now. So
it starts off random, but we keep selecting the smallest human or, in this case,
the shortest bar. And you'll see here the bars correlate with frequency, clearly.
So it's getting higher and higher and taller and taller. This is merge sort now
which, recall, does things in halves, and then halves of halves, and then merges
those halves. So we just did all the left work, almost all the right work. That
one's very gratifying. [LAUGHS] This is something called [? nom ?] sort, which is
improving things. Not quite perfectly, but it's always making forward progress, and
then kind of doubling back and cleaning things up. [END PLAYBACK] Whew. That was a
lot. Let's call it a day. I'll stick around for one-on-one questions. We'll see you
next time. [APPLAUSE]
Das könnte Ihnen auch gefallen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- An Honest Review of HDFC Life Sanchay Par Advantag+Dokument11 SeitenAn Honest Review of HDFC Life Sanchay Par Advantag+Sanjay S RayNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Lemon Coriander Soup Recipe VegDokument21 SeitenLemon Coriander Soup Recipe VegSanjay S RayNoch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Win or Lose, Trump Was The Mirror America NeededDokument3 SeitenWin or Lose, Trump Was The Mirror America NeededSanjay S RayNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Capital Markets Professional Certificate: Course InfoDokument2 SeitenCapital Markets Professional Certificate: Course InfoSanjay S RayNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- MentalModel ResearchPublication PDFDokument3 SeitenMentalModel ResearchPublication PDFSanjay S RayNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The Creativity ParadoxDokument3 SeitenThe Creativity ParadoxSanjay S RayNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- CS50 Lecture0 PDFDokument54 SeitenCS50 Lecture0 PDFSanjay S RayNoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- What Is Cryptojacking - How To Prevent, Detect, and Recover From It - CSO OnlineDokument7 SeitenWhat Is Cryptojacking - How To Prevent, Detect, and Recover From It - CSO OnlineSanjay S RayNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Naukri Murali (8y 0m)Dokument3 SeitenNaukri Murali (8y 0m)Main Shayar BadnamNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Performance and Best Practices Guide For IBM Spectrum Virtualize 85Dokument784 SeitenPerformance and Best Practices Guide For IBM Spectrum Virtualize 85lebbadoNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- How Valuable Is Company's Data?: What Is Business Intelligence?Dokument26 SeitenHow Valuable Is Company's Data?: What Is Business Intelligence?Arindam MondalNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- VCM Operations ReviewerDokument6 SeitenVCM Operations ReviewerjaneNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Experiment-1 Environment SetupDokument3 SeitenExperiment-1 Environment SetupSrinu ReddyNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Support Packages For TIA Portal V17: October 2021Dokument8 SeitenSupport Packages For TIA Portal V17: October 2021Henry Hasadiah Sanchez AguilarNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- User Manual Foi Voice Recording (Funcrowd)Dokument14 SeitenUser Manual Foi Voice Recording (Funcrowd)mjv.judsonNoch keine Bewertungen
- CSPFDokument38 SeitenCSPFNhan BienNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Purchase Request: Fund ClusterDokument148 SeitenPurchase Request: Fund ClusterAlex SibalNoch keine Bewertungen
- Software and Software EngineeringDokument24 SeitenSoftware and Software EngineeringCv Bc D IspNoch keine Bewertungen
- Final Math Problem SetDokument12 SeitenFinal Math Problem SettrielamiguelNoch keine Bewertungen
- 7SS52xx Manual PIXIT A2 V046101 enDokument48 Seiten7SS52xx Manual PIXIT A2 V046101 enwilliam jaimesNoch keine Bewertungen
- Internship ReportDokument45 SeitenInternship ReportPARTH KOTHARINoch keine Bewertungen
- A Little Less Talk - Inventor Professional Tube & Pipe Demo: Learning ObjectivesDokument54 SeitenA Little Less Talk - Inventor Professional Tube & Pipe Demo: Learning ObjectivesIsaac WabbiNoch keine Bewertungen
- Masusi Ngbanghayar Al I Nsafi L I Pi No1 0pani T I Kan:Mi T ODokument10 SeitenMasusi Ngbanghayar Al I Nsafi L I Pi No1 0pani T I Kan:Mi T OMellow YellowNoch keine Bewertungen
- User Manual For Registration - v1.2Dokument35 SeitenUser Manual For Registration - v1.2sdworks24Noch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- JavaScript - Errors & Exceptions Handling - TutorialspointDokument8 SeitenJavaScript - Errors & Exceptions Handling - Tutorialspointglen4uNoch keine Bewertungen
- Lesson Plan LAN CablingDokument3 SeitenLesson Plan LAN CablingAlfred Terre Llasos100% (3)
- AWS SolutionsArchitect-Associate Version 3.0-2Dokument6 SeitenAWS SolutionsArchitect-Associate Version 3.0-2Ashok Kumar R AsaithambiNoch keine Bewertungen
- ASIC Design of MIPS Based RISC Processor For High PerformanceDokument7 SeitenASIC Design of MIPS Based RISC Processor For High PerformanceShrinidhi RaoNoch keine Bewertungen
- WinCC Unified - Calendar - ManualDokument102 SeitenWinCC Unified - Calendar - ManualTamas LorinczNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Translate - Google SearchDokument1 SeiteTranslate - Google SearchCOSMIN PRUTEANUNoch keine Bewertungen
- Randi Rajput 5. Microprocessor Mod (CPU, & Parts)Dokument16 SeitenRandi Rajput 5. Microprocessor Mod (CPU, & Parts)aliNoch keine Bewertungen
- Age and Gender Detection Using CNNDokument5 SeitenAge and Gender Detection Using CNNdtssNoch keine Bewertungen
- CH 02Dokument35 SeitenCH 02ojaym alojaymNoch keine Bewertungen
- Purdue Model and ICS410 Model SANSDokument7 SeitenPurdue Model and ICS410 Model SANSRuchirNoch keine Bewertungen
- India Information Technology ReportDokument43 SeitenIndia Information Technology Reportprateeksri10Noch keine Bewertungen
- Docker SwarmDokument6 SeitenDocker SwarmSanthosh0% (1)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Msi Trident 3 Datasheet PDFDokument1 SeiteMsi Trident 3 Datasheet PDFAvinash VyasNoch keine Bewertungen
- MiroC110manual PDFDokument44 SeitenMiroC110manual PDFronaldo cordeiroNoch keine Bewertungen