Das könnte Ihnen auch gefallen
- Content Chapter I: Definition of Bar-Code. Common Types Chapter II: Usage of Bar-Code in Marketing Conclusion ReferencesDokument21 SeitenContent Chapter I: Definition of Bar-Code. Common Types Chapter II: Usage of Bar-Code in Marketing Conclusion ReferencesCray AlisterNoch keine Bewertungen
- Bar CodeDokument13 SeitenBar CodetruckturnerNoch keine Bewertungen
- Barcode Detection From An ImageDokument25 SeitenBarcode Detection From An ImageApoorva JoshiNoch keine Bewertungen
- BarcodeDokument16 SeitenBarcodeChidgana HegdeNoch keine Bewertungen
- BarcodeDokument31 SeitenBarcodeSarthak JainNoch keine Bewertungen
- QR Code Final ReportDokument42 SeitenQR Code Final ReportAnu ChaudharyNoch keine Bewertungen
- An Efficient Bar QR Code Recognition System For Consumer Service ApplicationsDokument5 SeitenAn Efficient Bar QR Code Recognition System For Consumer Service Applicationsizralaimin02Noch keine Bewertungen
- Unit 5 (C)Dokument76 SeitenUnit 5 (C)Raunak GuptaNoch keine Bewertungen
- ReportDokument18 SeitenReportReal GhostNoch keine Bewertungen
- Seminar On BarcodesDokument23 SeitenSeminar On BarcodesMohit Rana100% (5)
- An Introduction To QR Code Technology: December 2016Dokument7 SeitenAn Introduction To QR Code Technology: December 2016Momin Mohd AdnanNoch keine Bewertungen
- A Study On Multiple Barcode Detection From An Image in Business SystemDokument8 SeitenA Study On Multiple Barcode Detection From An Image in Business SystemMaulanaFahmiNoch keine Bewertungen
- Barcode System MCTDokument27 SeitenBarcode System MCTYogi BhimaniNoch keine Bewertungen
- QR Code SecurityDokument6 SeitenQR Code SecurityPrasad Pamidi100% (1)
- Bar Code BasicsDokument40 SeitenBar Code BasicsMARMARA100% (9)
- Barcode ReaderDokument6 SeitenBarcode Readerhsejmal12345Noch keine Bewertungen
- Barcode - WikipediaDokument10 SeitenBarcode - WikipediaTamal DuttaNoch keine Bewertungen
- Presented by Manisha TrivediDokument23 SeitenPresented by Manisha TrivediRahul KumarNoch keine Bewertungen
- 3434 PÉREZ ISLAS - P. Bar and QR Code SystemsDokument13 Seiten3434 PÉREZ ISLAS - P. Bar and QR Code SystemsGladis Viridiana Pérez IslasNoch keine Bewertungen
- Seminar 1Dokument22 SeitenSeminar 1p.bharNoch keine Bewertungen
- TempDokument14 SeitenTemphcNoch keine Bewertungen
- The Effective QR Code Development UsingDokument5 SeitenThe Effective QR Code Development UsingATSNoch keine Bewertungen
- Seminar ON Barcode Reader: Presented By: Phanibhusan Satapathy Regd No-930 Branch-AET 36TH BATCHDokument22 SeitenSeminar ON Barcode Reader: Presented By: Phanibhusan Satapathy Regd No-930 Branch-AET 36TH BATCHphanibhusan satapathyNoch keine Bewertungen
- Ishaque P K Electronics & Communication S3, Roll No 38Dokument18 SeitenIshaque P K Electronics & Communication S3, Roll No 38pandarahulkumar0Noch keine Bewertungen
- Barcode Supply ChainDokument8 SeitenBarcode Supply ChainHamza SidikiNoch keine Bewertungen
- Types of Barcodes - Choosing The Right BarcodeDokument13 SeitenTypes of Barcodes - Choosing The Right BarcodegetrwdyyNoch keine Bewertungen
- This Is The Most Obvious Benefit of Barcode Data Collection. in ManyDokument20 SeitenThis Is The Most Obvious Benefit of Barcode Data Collection. in Manygireesh_mouliNoch keine Bewertungen
- QR Code Final ReportDokument34 SeitenQR Code Final ReportHemant Dange71% (14)
- Barcode ReportDokument22 SeitenBarcode ReportNivedha RituNoch keine Bewertungen
- QRCodeDokument6 SeitenQRCodeNarasimha thirunagaramNoch keine Bewertungen
- BarcodeDokument4 SeitenBarcodeVirag PatilNoch keine Bewertungen
- Project ReportDokument42 SeitenProject ReportMomin Mohd AdnanNoch keine Bewertungen
- Unit 10 Automatic IdentificationDokument21 SeitenUnit 10 Automatic IdentificationKirandeep GandhamNoch keine Bewertungen
- QR CodesDokument18 SeitenQR CodesVishnu ParsiNoch keine Bewertungen
- Barcode Thesis DocumentationDokument4 SeitenBarcode Thesis Documentationgof1mytamev2100% (2)
- Three QR CodeDokument20 SeitenThree QR CodeSaiprasanthi RakeshNoch keine Bewertungen
- QR Code BarcodeDokument23 SeitenQR Code BarcodeKamen Rider100% (1)
- Id System Using Barcode ThesisDokument4 SeitenId System Using Barcode Thesisfjdxfc4v100% (1)
- Three QR CodeDokument20 SeitenThree QR CodeVaishali LadNoch keine Bewertungen
- QR CODE SeminarDokument31 SeitenQR CODE SeminarNavathi Suresh100% (5)
- Barcode ReaderDokument6 SeitenBarcode ReaderVladik SumanNoch keine Bewertungen
- Whitepaper Intro To Barcode VerificationDokument13 SeitenWhitepaper Intro To Barcode VerificationLaura FlorescuNoch keine Bewertungen
- BarcodeDokument4 SeitenBarcode7327 AbcdfgNoch keine Bewertungen
- Automated Examination Using QR Code: Nitish Soman, Ulhas Shelke, Shahanawaj PatelDokument6 SeitenAutomated Examination Using QR Code: Nitish Soman, Ulhas Shelke, Shahanawaj Patelabduldahiru227Noch keine Bewertungen
- CMR Engineering College: "Barcode"Dokument14 SeitenCMR Engineering College: "Barcode"Madhu SravaniNoch keine Bewertungen
- Expanding The Data Capacity of QR Codes Using Multiple Compression Algorithms and Base64 Encode/DecodeDokument7 SeitenExpanding The Data Capacity of QR Codes Using Multiple Compression Algorithms and Base64 Encode/DecodeLabodedexterNoch keine Bewertungen
- Three: QR CodeDokument20 SeitenThree: QR Codechaitanya23Noch keine Bewertungen
- Three QR CodeDokument20 SeitenThree QR CodeNeha BhavsarNoch keine Bewertungen
- Barcode Scanner ThesisDokument6 SeitenBarcode Scanner Thesisafcnzfamt100% (2)
- Barcode ReaderDokument6 SeitenBarcode Readereldhopaul19894886Noch keine Bewertungen
- QR CODE INFORMATION GENERATOR (Autosaved)Dokument15 SeitenQR CODE INFORMATION GENERATOR (Autosaved)Arushi SaklaniNoch keine Bewertungen
- Barcode Technology: Seminar OnDokument20 SeitenBarcode Technology: Seminar OnChidgana Hegde100% (1)
- QR Code Generator and Detector Using PythonDokument8 SeitenQR Code Generator and Detector Using Python18X435 MadhuriNoch keine Bewertungen
- Debugging Systems-on-Chip: Communication-centric and Abstraction-based TechniquesVon EverandDebugging Systems-on-Chip: Communication-centric and Abstraction-based TechniquesNoch keine Bewertungen
- Essentials of Error-Control Coding TechniquesVon EverandEssentials of Error-Control Coding TechniquesBewertung: 5 von 5 Sternen5/5 (1)
- Optical Character Recognition: Fundamentals and ApplicationsVon EverandOptical Character Recognition: Fundamentals and ApplicationsNoch keine Bewertungen
- Mastering the Craft: Unleashing the Art of Software EngineeringVon EverandMastering the Craft: Unleashing the Art of Software EngineeringNoch keine Bewertungen
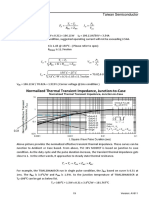
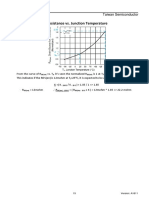
- Understand MOSFET Datasheet-TaiwanSemicon 19Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 19CataNoch keine Bewertungen
- Power MOSFET basics-IXYS 1Dokument1 SeitePower MOSFET basics-IXYS 1CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 20Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 20CataNoch keine Bewertungen
- Power MOSFET basics-IXYS 3Dokument1 SeitePower MOSFET basics-IXYS 3CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 21Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 21CataNoch keine Bewertungen
- Power MOSFET basics-IXYS 2Dokument1 SeitePower MOSFET basics-IXYS 2CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 20Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 20CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 18Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 18CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 16Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 16CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 14Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 14CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 17Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 17CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 15Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 15CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 15Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 15CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 16Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 16CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 18Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 18CataNoch keine Bewertungen
- Hukum Termodinamika IIDokument21 SeitenHukum Termodinamika IIdiky dharmawanNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 21Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 21CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 21Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 21CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 20Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 20CataNoch keine Bewertungen
- Hukum Termodinamika IIDokument21 SeitenHukum Termodinamika IIdiky dharmawanNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 14Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 14CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 11Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 11CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 13Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 13CataNoch keine Bewertungen
- Package Inductance-Infineon 6Dokument1 SeitePackage Inductance-Infineon 6CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 19Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 19CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 10Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 10CataNoch keine Bewertungen
- Understand MOSFET Datasheet-TaiwanSemicon 12Dokument1 SeiteUnderstand MOSFET Datasheet-TaiwanSemicon 12CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 4Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 4CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 6Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 6CataNoch keine Bewertungen
- Understand MOSFET datasheet-TaiwanSemicon 2Dokument1 SeiteUnderstand MOSFET datasheet-TaiwanSemicon 2CataNoch keine Bewertungen
- Assessment Task 2 - BSBITU213Dokument28 SeitenAssessment Task 2 - BSBITU213Chaleamkwan NatungkhumNoch keine Bewertungen
- Volume of An N-Ball - WikipediaDokument15 SeitenVolume of An N-Ball - WikipediabibbiblosNoch keine Bewertungen
- The Mean of The Sample MeanDokument31 SeitenThe Mean of The Sample MeanAngelie Limbago CagasNoch keine Bewertungen
- Desi QnA MentoringDokument9 SeitenDesi QnA MentoringCharan KasanagottuNoch keine Bewertungen
- Interfacing of Blue Tooth With 8051Dokument18 SeitenInterfacing of Blue Tooth With 8051Brindha ManickavasakanNoch keine Bewertungen
- DatasheetDokument127 SeitenDatasheetkiet nguyen trucNoch keine Bewertungen
- 2023 HRTeaching LearningDokument55 Seiten2023 HRTeaching LearningpassanstoiNoch keine Bewertungen
- Java Advantages Over C++Dokument3 SeitenJava Advantages Over C++sures_89Noch keine Bewertungen
- Literature Review Network SecurityDokument8 SeitenLiterature Review Network Securityc5q8g5tz100% (1)
- Introduction M CommerceDokument27 SeitenIntroduction M CommerceAditya NagdaNoch keine Bewertungen
- Resume For Travel AgentDokument8 SeitenResume For Travel Agentafmrnroadofebl100% (1)
- Payloads Ejemplo SDokument2 SeitenPayloads Ejemplo SlmdimasmNoch keine Bewertungen
- Design Failure Mode and Effects Analysis: Design Information DFMEA InformationDokument11 SeitenDesign Failure Mode and Effects Analysis: Design Information DFMEA InformationMani Rathinam Rajamani0% (1)
- Welcome To The Adversarial Robustness Toolbox - Adversarial Robustness Toolbox 1.2.0 DocumentationDokument6 SeitenWelcome To The Adversarial Robustness Toolbox - Adversarial Robustness Toolbox 1.2.0 DocumentationNida AmaliaNoch keine Bewertungen
- Lifecycle Controller Remote Firmware Update ScriptingDokument15 SeitenLifecycle Controller Remote Firmware Update ScriptingOdwori EmmanuelkenNoch keine Bewertungen
- IGMP Multicast WebinarDokument35 SeitenIGMP Multicast Webinaredonat0894Noch keine Bewertungen
- Contract Title Contract No. Contractor Name and Address Original Contract Value (KWD) RFP No. Duration (Days) S. NoDokument2 SeitenContract Title Contract No. Contractor Name and Address Original Contract Value (KWD) RFP No. Duration (Days) S. NoKoteswar MandavaNoch keine Bewertungen
- Matlab Assignment: Submitted By:-Siddhant Raut (6464)Dokument3 SeitenMatlab Assignment: Submitted By:-Siddhant Raut (6464)Prem Swaroop KadavakuduruNoch keine Bewertungen
- Embedded C Coding StandardDokument206 SeitenEmbedded C Coding Standardsantosh rajaNoch keine Bewertungen
- Astro Smart TV Multiroom TTTDokument29 SeitenAstro Smart TV Multiroom TTTSobnavalle KesavanNoch keine Bewertungen
- Code (Edited)Dokument8 SeitenCode (Edited)Khương MaiNoch keine Bewertungen
- IF5200 Project Closure TemplateDokument3 SeitenIF5200 Project Closure TemplateBagus EnggartiastoNoch keine Bewertungen
- Isbn 955Dokument278 SeitenIsbn 955Kushan HettiarachchiNoch keine Bewertungen
- 02-1a Fundamentals of Plant Process Layout & Piping DesignDokument88 Seiten02-1a Fundamentals of Plant Process Layout & Piping DesignNicah Dela Viña BuhiaNoch keine Bewertungen
- Fol500 002 14 Rev04Dokument8 SeitenFol500 002 14 Rev04Franco DeottoNoch keine Bewertungen
- Pik BestDokument3 SeitenPik BestAshley Wu50% (2)
- AZ 900 Questions - Part1to13Dokument70 SeitenAZ 900 Questions - Part1to13Nguyen Tuan Anh100% (1)
- BSBCUS501 Assessment 2Dokument9 SeitenBSBCUS501 Assessment 2Paisan PankaewNoch keine Bewertungen
- Emeter MDM White PaperDokument9 SeitenEmeter MDM White PapernittecatNoch keine Bewertungen
- BMC Remedy It Service Management 9.0 (PDFDrive)Dokument282 SeitenBMC Remedy It Service Management 9.0 (PDFDrive)Omar EhabNoch keine Bewertungen