Das könnte Ihnen auch gefallen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Direct Automatic Generation of Mind Maps From Text With M2GenDokument6 SeitenDirect Automatic Generation of Mind Maps From Text With M2Gensrik37Noch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- 2020 University of Bradford OfS Funded Scholarships For MSC in AIDA Guidance Notes 19082020Dokument5 Seiten2020 University of Bradford OfS Funded Scholarships For MSC in AIDA Guidance Notes 19082020srik37Noch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Mrprintables Alphabet Flashcards Extra Words CardsDokument1 SeiteMrprintables Alphabet Flashcards Extra Words Cardssrik37Noch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Auth0 A Cloud Guru Case StudyDokument6 SeitenAuth0 A Cloud Guru Case Studysrik37Noch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
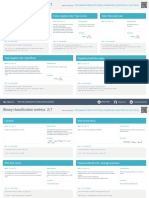
- Binary ClassificationMetrics CheathsheetDokument7 SeitenBinary ClassificationMetrics CheathsheetPedro PereiraNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Nicolaides The 11-13 Weeks Scan 2004Dokument113 SeitenNicolaides The 11-13 Weeks Scan 2004ScopulovicNoch keine Bewertungen
- Benefits of Single Ci CDDokument9 SeitenBenefits of Single Ci CDVinay DesaiNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- 15-10-27 MK City CentreDokument32 Seiten15-10-27 MK City Centresrik37Noch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- CBP Study GuideDokument24 SeitenCBP Study Guidenatecv890% (10)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- MR Srikanth Gedela TDDWLVJD: Driving Status EndorsementsDokument1 SeiteMR Srikanth Gedela TDDWLVJD: Driving Status Endorsementssrik37Noch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Storage Special Report 7 OpenStack PDFDokument11 SeitenStorage Special Report 7 OpenStack PDFsrik37Noch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- RCDokument5 SeitenRCAnonymous lfw4mfCmNoch keine Bewertungen
- Joe O Business PlanDokument21 SeitenJoe O Business Plansrik37Noch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Gowri PowranamiDokument5 SeitenGowri Powranamisrik37Noch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Introduction Cloud Computing Canonical UbuntuDokument9 SeitenIntroduction Cloud Computing Canonical Ubuntusrik37Noch keine Bewertungen
- TSD DW BI CGRefund Surveillance2WDokument8 SeitenTSD DW BI CGRefund Surveillance2WArifRahmanHakimNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Week5 Unit 2 Webi On Mobile Exercise-Pre-requisitesDokument5 SeitenWeek5 Unit 2 Webi On Mobile Exercise-Pre-requisitesOthniel MurrayNoch keine Bewertungen
- Project ReportDokument44 SeitenProject ReportAkash kolheNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- 9 Best Marketing Analytics ToolsDokument3 Seiten9 Best Marketing Analytics ToolsHonNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Desain Data Warehouse Penjualan Menggunakan NineDokument10 SeitenDesain Data Warehouse Penjualan Menggunakan NineAlvido SatriaNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Project ProposalDokument7 SeitenProject Proposalshams ur rehmanNoch keine Bewertungen
- Hana Syllabus PDFDokument5 SeitenHana Syllabus PDFsaibalaji2kNoch keine Bewertungen
- Asp .Net MaterialDokument337 SeitenAsp .Net Materialhanu1988100% (1)
- 8.4.2.3 Unsuccessful Operation: Handover Request MME Handover Failure Target eNBDokument14 Seiten8.4.2.3 Unsuccessful Operation: Handover Request MME Handover Failure Target eNBBijaya RanaNoch keine Bewertungen
- Dbms - Assignment by Devendra DarjiDokument8 SeitenDbms - Assignment by Devendra DarjiDevendra DarjiNoch keine Bewertungen
- BomDokument848 SeitenBompereuse100% (1)
- EasyEPD2 DatasheetDokument2 SeitenEasyEPD2 DatasheetFilipe LaínsNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (120)
- BIP User Manual PDFDokument82 SeitenBIP User Manual PDFSandip KarmakarNoch keine Bewertungen
- MNR School OF Excellence: "Parking Management System"Dokument23 SeitenMNR School OF Excellence: "Parking Management System"Guruji GamingNoch keine Bewertungen
- Module Pool TipsDokument1 SeiteModule Pool TipsDeepak NandikantiNoch keine Bewertungen
- What Is ASP? ASP Is Acronym For Active Server Page. It's Server Side Script Language DevelopedDokument20 SeitenWhat Is ASP? ASP Is Acronym For Active Server Page. It's Server Side Script Language Developedrajendra_samyNoch keine Bewertungen
- Importing Suppliers r12Dokument37 SeitenImporting Suppliers r12Sai Krishna AravapalliNoch keine Bewertungen
- CPM - SapDokument14 SeitenCPM - SapOscarAnibalAbantoCondori0% (1)
- SAP PP - How To Create Production VersionDokument5 SeitenSAP PP - How To Create Production VersionKoustubha KhareNoch keine Bewertungen
- Infrastructure Audit ChecklistDokument3 SeitenInfrastructure Audit ChecklistLinn Ni AungNoch keine Bewertungen
- Source Code Program in C Implement Symbol TableDokument6 SeitenSource Code Program in C Implement Symbol TableSachin SharmaNoch keine Bewertungen
- All Quiz DMDokument20 SeitenAll Quiz DMRahul RaoNoch keine Bewertungen
- Wowcoin LaunchDokument18 SeitenWowcoin LaunchVpsinghNoch keine Bewertungen
- CH03-User Authentication - 2Dokument50 SeitenCH03-User Authentication - 2Ahmad RawajbehNoch keine Bewertungen
- WRIV201 Unit 1 Study Guide PDFDokument5 SeitenWRIV201 Unit 1 Study Guide PDFSamanthaNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Fedarated Repostires PDFDokument30 SeitenFedarated Repostires PDFvenkatreddyNoch keine Bewertungen
- AWS & SANS - 2023 Cloud Security Trends (Shackleford)Dokument23 SeitenAWS & SANS - 2023 Cloud Security Trends (Shackleford)David BeyNoch keine Bewertungen
- AzureSecurityCenter BaselineRules Windows Linux V3Dokument28 SeitenAzureSecurityCenter BaselineRules Windows Linux V3anjana vNoch keine Bewertungen
- Splunk-7.0.0-Knowledge - Knowledge Manager Manual 2Dokument426 SeitenSplunk-7.0.0-Knowledge - Knowledge Manager Manual 2tedNoch keine Bewertungen
- Brett W Oliver (C Developer)Dokument4 SeitenBrett W Oliver (C Developer)Pavnendra SinghNoch keine Bewertungen
- Blockchain Basics: A Non-Technical Introduction in 25 StepsVon EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsBewertung: 4.5 von 5 Sternen4.5/5 (24)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLVon EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLBewertung: 4.5 von 5 Sternen4.5/5 (46)