Das könnte Ihnen auch gefallen
- Using ARIMA-GARCH Model To Analyze Fluctuation Law of Price OilDokument7 SeitenUsing ARIMA-GARCH Model To Analyze Fluctuation Law of Price OilMatias VargasNoch keine Bewertungen
- Developing a New Approach for Forecasting Oil Price Trends Using ARIMA and ANFIS ModelsDokument13 SeitenDeveloping a New Approach for Forecasting Oil Price Trends Using ARIMA and ANFIS Modelselisabeth_nainggolan12Noch keine Bewertungen
- Does Long Memory Matter in Oil Price Volatility Forecasting?Dokument8 SeitenDoes Long Memory Matter in Oil Price Volatility Forecasting?International Association of Scientific Innovations and Research (IASIR)Noch keine Bewertungen
- Forecasting Steel Prices Using ARIMAX Model: A Case Study of TurkeyDokument7 SeitenForecasting Steel Prices Using ARIMAX Model: A Case Study of TurkeyThe IjbmtNoch keine Bewertungen
- Modeling The Relationship Between Crude Oil and Energy Sector Stock PricesDokument8 SeitenModeling The Relationship Between Crude Oil and Energy Sector Stock PricesHarish Pillu.Noch keine Bewertungen
- J Econlet 2019 05 041Dokument5 SeitenJ Econlet 2019 05 041sonia969696Noch keine Bewertungen
- Https:/poseidon01 SSRN Com/delivery PHPDokument32 SeitenHttps:/poseidon01 SSRN Com/delivery PHPvagablondNoch keine Bewertungen
- An Analysis of Price Spikes and Deviations in The Dereg - 2019 - Energy StrategyDokument7 SeitenAn Analysis of Price Spikes and Deviations in The Dereg - 2019 - Energy StrategyJoao Victor Gomes FreireNoch keine Bewertungen
- IJCAS v6 n5 pp.639-650Dokument12 SeitenIJCAS v6 n5 pp.639-650zkNoch keine Bewertungen
- University of Houston, Houston, TX 77004, USA Texas A&M University, College Station, TX 77843, USADokument21 SeitenUniversity of Houston, Houston, TX 77004, USA Texas A&M University, College Station, TX 77843, USASalma FloresNoch keine Bewertungen
- Modeling Demand For Coal in India: Vector Autoregressive Models With Cointegrated VariablesDokument20 SeitenModeling Demand For Coal in India: Vector Autoregressive Models With Cointegrated Variablesothmane lamzihriNoch keine Bewertungen
- Stock Market Indices Direction Prediction Time Series, Macro Economic Factors and Distributed Lag ModelsDokument9 SeitenStock Market Indices Direction Prediction Time Series, Macro Economic Factors and Distributed Lag ModelsIJRASETPublicationsNoch keine Bewertungen
- Temizel2020 Heavy OilDokument29 SeitenTemizel2020 Heavy OilCarlos Alberto Torrico BorjaNoch keine Bewertungen
- Prediction of Immiscible Gas Flooding Performance: A Modified Capacitance-Resistance Model and Sensitivity AnalysisDokument19 SeitenPrediction of Immiscible Gas Flooding Performance: A Modified Capacitance-Resistance Model and Sensitivity AnalysisTripoli ManoNoch keine Bewertungen
- Computational Modeling of Crude Oil Price PDFDokument13 SeitenComputational Modeling of Crude Oil Price PDFMisLibrosNoch keine Bewertungen
- "Value-at-Risk and Expected Shortfall Estimations Based On GARCH-Type Models: Evidence From Energy Commodities," by Samir MabroukDokument37 Seiten"Value-at-Risk and Expected Shortfall Estimations Based On GARCH-Type Models: Evidence From Energy Commodities," by Samir MabroukThe International Research Center for Energy and Economic Development (ICEED)Noch keine Bewertungen
- Estimating Preference Change in Meat Demand in Saudi ArabiaDokument9 SeitenEstimating Preference Change in Meat Demand in Saudi ArabiaSantiago GonzalezNoch keine Bewertungen
- ID Perbandingan Model Archgarch Model ArimaDokument8 SeitenID Perbandingan Model Archgarch Model ArimaauraNoch keine Bewertungen
- Applied Energy: Zhongfu Tan, Jinliang Zhang, Jianhui Wang, Jun XuDokument5 SeitenApplied Energy: Zhongfu Tan, Jinliang Zhang, Jianhui Wang, Jun XuVamsi KajaNoch keine Bewertungen
- Application of Box-Jenkins Techniques in Modelling and Forecasting Nigeria Crude Oil PricesDokument9 SeitenApplication of Box-Jenkins Techniques in Modelling and Forecasting Nigeria Crude Oil PricesSai RamakanthNoch keine Bewertungen
- 1-s2.0-S0967070X23000331-mainDokument8 Seiten1-s2.0-S0967070X23000331-mainHUY NGÔ NHẤTNoch keine Bewertungen
- Long Memory - Agricultural CommodityDokument34 SeitenLong Memory - Agricultural CommodityGabrielle LimaNoch keine Bewertungen
- Aggarwal 2009Dokument10 SeitenAggarwal 2009Yusuf Ali DanışNoch keine Bewertungen
- Article 4. 41Dokument14 SeitenArticle 4. 41ricardoloureirosoareNoch keine Bewertungen
- Valipour, Mohammad - Long-Term Runoff Study Using SARIMA and ARIMA Models in The United States - 2Dokument7 SeitenValipour, Mohammad - Long-Term Runoff Study Using SARIMA and ARIMA Models in The United States - 23mmahmoodeaNoch keine Bewertungen
- Petro & CerealsDokument10 SeitenPetro & Cerealsபுகழேந்திரன் சிNoch keine Bewertungen
- Mean RevDokument44 SeitenMean RevLameuneNoch keine Bewertungen
- Garch ModelDokument3 SeitenGarch ModelFaroq OmarNoch keine Bewertungen
- Forecasting For Soybean Production in India Using Season Time PDFDokument5 SeitenForecasting For Soybean Production in India Using Season Time PDFAgricultureASDNoch keine Bewertungen
- Macroeconomic Models For Long-Term Energy and Emissions in IndiaDokument34 SeitenMacroeconomic Models For Long-Term Energy and Emissions in IndiaNikhil BhargavaNoch keine Bewertungen
- Forecasting Agricultural Commodities Using ARIMA & Volatility ModelsDokument18 SeitenForecasting Agricultural Commodities Using ARIMA & Volatility ModelsHarshit MahajanNoch keine Bewertungen
- Modeling The Volatility of Exchange Rate Currency Using Garch ModelDokument22 SeitenModeling The Volatility of Exchange Rate Currency Using Garch ModelAdmasuNoch keine Bewertungen
- Climate Policies As A Hedge Against The Uncertainty On Future Oil SupplyDokument6 SeitenClimate Policies As A Hedge Against The Uncertainty On Future Oil SupplyjrozenbergNoch keine Bewertungen
- Of Combustor Aerothermal Models: Assessment, Development, and ApplicationDokument21 SeitenOf Combustor Aerothermal Models: Assessment, Development, and Applicationmoresh85Noch keine Bewertungen
- Modelling Gasoline Demand in Ghana: A Structural Time Series ApproachDokument7 SeitenModelling Gasoline Demand in Ghana: A Structural Time Series ApproachisaNoch keine Bewertungen
- The Conditional Autoregressive Geometric Process Model For Range DataDokument35 SeitenThe Conditional Autoregressive Geometric Process Model For Range Datajshew_jr_junkNoch keine Bewertungen
- Re-Evaluating Natural Resource Investments Under Uncertainty An Alternative To Limited Traditional ApproachesDokument31 SeitenRe-Evaluating Natural Resource Investments Under Uncertainty An Alternative To Limited Traditional ApproachesKevin RiosNoch keine Bewertungen
- Data Cleaning Kalam2019Dokument15 SeitenData Cleaning Kalam2019VeronicaNoch keine Bewertungen
- Econometrics Oil PriceDokument13 SeitenEconometrics Oil Pricehaseeb ahmedNoch keine Bewertungen
- GuiaDokument22 SeitenGuiatruchascorpNoch keine Bewertungen
- Spe 196248 MS PDFDokument31 SeitenSpe 196248 MS PDFdwidwi novryNoch keine Bewertungen
- Market Power and Price Transmission in The Supply Chain Working PaperDokument48 SeitenMarket Power and Price Transmission in The Supply Chain Working PaperIVI THEODOULOUNoch keine Bewertungen
- A Multivariate Arima Model To Forecast Air Transport Demand PDFDokument14 SeitenA Multivariate Arima Model To Forecast Air Transport Demand PDFKevin BunyanNoch keine Bewertungen
- Macroeconomic Determinants of VolatilityDokument19 SeitenMacroeconomic Determinants of VolatilityIzzah Nazatul Nazihah Binti EjapNoch keine Bewertungen
- 提出两种预测铜的新型混合智能模型价格基于极限学习机和元启发式算法Dokument12 Seiten提出两种预测铜的新型混合智能模型价格基于极限学习机和元启发式算法赵一霏Noch keine Bewertungen
- A Switching Threshold Model For Oil Prices: Palombizio Ennio A., Olivares PabloDokument9 SeitenA Switching Threshold Model For Oil Prices: Palombizio Ennio A., Olivares PabloHadiBiesNoch keine Bewertungen
- Energies: Energy Commodity Price Forecasting With Deep Multiple Kernel LearningDokument16 SeitenEnergies: Energy Commodity Price Forecasting With Deep Multiple Kernel LearningKavya AnnapaReddyNoch keine Bewertungen
- Arima-Garch Models in Estimating Market Risk Using Value at Risk For The Wig20 IndexDokument9 SeitenArima-Garch Models in Estimating Market Risk Using Value at Risk For The Wig20 IndexFernando HillNoch keine Bewertungen
- A Multivariate Ari1399 PDFDokument14 SeitenA Multivariate Ari1399 PDFEric 'robo' BaafiNoch keine Bewertungen
- J H: A E M C S F M: Umping Edges N Xamination of Ovements in Opper Pot and Utures ArketsDokument21 SeitenJ H: A E M C S F M: Umping Edges N Xamination of Ovements in Opper Pot and Utures ArketsKumaran SanthoshNoch keine Bewertungen
- Spe-196678-Ms Pso PDFDokument21 SeitenSpe-196678-Ms Pso PDFFABGOILMANNoch keine Bewertungen
- WRAP Linepack Planning Models Gas Network French 2018Dokument35 SeitenWRAP Linepack Planning Models Gas Network French 2018pahdouxe pahdiNoch keine Bewertungen
- Volatility Transmission in The Oil and Natural Gas Markets: Bradley T. Ewing, Farooq Malik, Ozkan OzfidanDokument14 SeitenVolatility Transmission in The Oil and Natural Gas Markets: Bradley T. Ewing, Farooq Malik, Ozkan OzfidanAnum Nadeem GillNoch keine Bewertungen
- 1 s2.0 S027553191830669X MainDokument13 Seiten1 s2.0 S027553191830669X Mainnash al aminNoch keine Bewertungen
- Timeseries ModifiedDokument12 SeitenTimeseries ModifiedsikandarshahNoch keine Bewertungen
- A Flow Maximizing Adaptive Local Ramp MeDokument20 SeitenA Flow Maximizing Adaptive Local Ramp MesalemNoch keine Bewertungen
- Demand Nodel QuebecDokument11 SeitenDemand Nodel QuebecAmir JoonNoch keine Bewertungen
- Road Traffic Noise Prediction Models: A ReviewDokument15 SeitenRoad Traffic Noise Prediction Models: A ReviewMuhammad Imran KhanNoch keine Bewertungen
- Ejsr 43 4 06Dokument12 SeitenEjsr 43 4 06mohsenNoch keine Bewertungen
- Design Parameter Unit Symbol Value RemarksDokument2 SeitenDesign Parameter Unit Symbol Value Remarksraj1508Noch keine Bewertungen
- Clock Spring: Application Note DurabilityDokument4 SeitenClock Spring: Application Note Durabilityraj1508Noch keine Bewertungen
- Application Note Clock Spring® MarkerDokument3 SeitenApplication Note Clock Spring® Markerraj1508Noch keine Bewertungen
- India Today 5 Oct PDFDokument66 SeitenIndia Today 5 Oct PDFraj1508Noch keine Bewertungen
- India Today 5 Oct PDFDokument66 SeitenIndia Today 5 Oct PDFraj1508Noch keine Bewertungen
- Field Marshal Sam Manekshaw On DisciplineDokument13 SeitenField Marshal Sam Manekshaw On DisciplineDeltaForceNoch keine Bewertungen
- Pipeline Cathodic Protection Design ParametersDokument2 SeitenPipeline Cathodic Protection Design Parametersraj1508Noch keine Bewertungen
- 4 6026206739718735498 PDFDokument18 Seiten4 6026206739718735498 PDFraj1508Noch keine Bewertungen
- HSE SPECIFICATIONSDokument6 SeitenHSE SPECIFICATIONSraj1508Noch keine Bewertungen
- Annexure V Bid MatrixDokument17 SeitenAnnexure V Bid Matrixraj1508Noch keine Bewertungen
- Annexure III Scope of Work and Special ConditionsDokument7 SeitenAnnexure III Scope of Work and Special Conditionsraj1508Noch keine Bewertungen
- Annexure VII Bidders Response SheetDokument2 SeitenAnnexure VII Bidders Response Sheetraj1508Noch keine Bewertungen
- Schedule of Rates (Sor) : Section-Vii TENDER NO. GAIL/AGT/FL85/20075421/8000012800Dokument2 SeitenSchedule of Rates (Sor) : Section-Vii TENDER NO. GAIL/AGT/FL85/20075421/8000012800raj1508Noch keine Bewertungen
- Outlook June 2020 PDFDokument56 SeitenOutlook June 2020 PDFraj1508Noch keine Bewertungen
- Annexure Iv BecDokument37 SeitenAnnexure Iv Becraj1508Noch keine Bewertungen
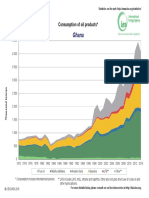
- Ghana: Consumption of Oil ProductsDokument1 SeiteGhana: Consumption of Oil Productsraj1508Noch keine Bewertungen
- Black PowderDokument7 SeitenBlack PowderMarsyaNoch keine Bewertungen
- Composol PipelineDokument1 SeiteComposol Pipelineraj1508Noch keine Bewertungen
- Ghana - Oil and Gas - ExportDokument5 SeitenGhana - Oil and Gas - Exportraj1508Noch keine Bewertungen
- Glossary Trading of Oil and GasDokument136 SeitenGlossary Trading of Oil and Gasprsiva2420034066Noch keine Bewertungen
- Composol Vessel: UsageDokument1 SeiteComposol Vessel: Usageraj1508Noch keine Bewertungen
- Tableau Incoterms 202000Dokument5 SeitenTableau Incoterms 202000souleymane sow100% (6)
- Glossary of Terms Used in Oil IndustryDokument67 SeitenGlossary of Terms Used in Oil Industryhrami2Noch keine Bewertungen
- Key World Energy TrendsDokument19 SeitenKey World Energy TrendsBradley JohnsonNoch keine Bewertungen
- HD-Shell Nederland - USADokument29 SeitenHD-Shell Nederland - USANhuyNoch keine Bewertungen
- Pall - Black Powder FilterDokument12 SeitenPall - Black Powder FilterHeymonth Chandra100% (1)
- Composol Grab-Wrap: UsageDokument1 SeiteComposol Grab-Wrap: Usageraj1508Noch keine Bewertungen
- Composol StructureDokument1 SeiteComposol Structureraj1508Noch keine Bewertungen
- Composol Pipework: UsageDokument1 SeiteComposol Pipework: Usageraj1508Noch keine Bewertungen
- Topic - 7 (Uncertainty)Dokument25 SeitenTopic - 7 (Uncertainty)musabbirNoch keine Bewertungen
- Andesite Lab TestsDokument7 SeitenAndesite Lab TestsCristian A'cNoch keine Bewertungen
- Chapter 5: Sampling Distributions: Solve The ProblemDokument4 SeitenChapter 5: Sampling Distributions: Solve The ProblemEunice WongNoch keine Bewertungen
- MA-2203: Introduction To Probability and Statistics: Lecture SlidesDokument64 SeitenMA-2203: Introduction To Probability and Statistics: Lecture SlidesGaurav Kumar GuptaNoch keine Bewertungen
- Data Analysis for Physics Laboratory MeasurementsDokument5 SeitenData Analysis for Physics Laboratory Measurementsccouy123Noch keine Bewertungen
- ST2131 Ma2216 0910S2Dokument19 SeitenST2131 Ma2216 0910S2Kevin Cai JuntaoNoch keine Bewertungen
- Midterm1 Spring2023 AnswerkeysDokument12 SeitenMidterm1 Spring2023 AnswerkeysSwaraj AgarwalNoch keine Bewertungen
- MAT2377 C Midterm Test-Solution Key Statistics ConceptsDokument9 SeitenMAT2377 C Midterm Test-Solution Key Statistics ConceptsNizar MohammadNoch keine Bewertungen
- EE585 Fall2009 Hw3 SolDokument2 SeitenEE585 Fall2009 Hw3 Solnoni496Noch keine Bewertungen
- STAT515 LectureDokument85 SeitenSTAT515 Lecturecommando1180Noch keine Bewertungen
- An Introduction To Markovchain Package PDFDokument68 SeitenAn Introduction To Markovchain Package PDFJames DunkelfelderNoch keine Bewertungen
- Discrete Probability Distributions Lab ActivityDokument16 SeitenDiscrete Probability Distributions Lab ActivityKarl Vincent BebingNoch keine Bewertungen
- Soal Asis ViDokument7 SeitenSoal Asis ViNadya RahmanitaNoch keine Bewertungen
- Statistics for Data Science AssignmentDokument8 SeitenStatistics for Data Science AssignmentAlok TripathiNoch keine Bewertungen
- Probability and Statistics PDFDokument3 SeitenProbability and Statistics PDFAbsolute ZeroNoch keine Bewertungen
- Reading - Exploratory Data AnalysisDokument33 SeitenReading - Exploratory Data Analysisvaibhavpardeshi55Noch keine Bewertungen
- Understanding Probability DistributionsDokument129 SeitenUnderstanding Probability DistributionsHomero Edwin Mejia CruzNoch keine Bewertungen
- Supp2 2Dokument307 SeitenSupp2 2吳 澍 WU SU F74056297Noch keine Bewertungen
- 4 Distribusi Normal Multivariat-1Dokument26 Seiten4 Distribusi Normal Multivariat-1Nadiyah NisrinaNoch keine Bewertungen
- 004-5-MATH 361 Probability & StatisticsDokument1 Seite004-5-MATH 361 Probability & StatisticssaadahmedkalidaasNoch keine Bewertungen
- Distributions and Expected Values of Random VariablesDokument13 SeitenDistributions and Expected Values of Random VariablesCrystal Mae DomingoNoch keine Bewertungen
- Module 19 - : Distribution of Sample Proportions and MeansDokument6 SeitenModule 19 - : Distribution of Sample Proportions and MeansOlaolu JosephNoch keine Bewertungen
- Syllabus of Ph.D. CourseDokument6 SeitenSyllabus of Ph.D. CourseVicky GuptaNoch keine Bewertungen
- All The Probability and Statistics SheetsDokument20 SeitenAll The Probability and Statistics SheetsAliNoch keine Bewertungen
- HW3 Selected SolutionsDokument5 SeitenHW3 Selected Solutionsgari_teroNoch keine Bewertungen
- Table of Normal DistributionDokument1 SeiteTable of Normal DistributionTanjamulNoch keine Bewertungen
- Solution Manual For Generalized Linear Models 0205377939Dokument38 SeitenSolution Manual For Generalized Linear Models 0205377939eozoicjaggern2ni4100% (16)
- Part-I Central Tendency and Dispersion: Unit-3 Basic StatisticsDokument32 SeitenPart-I Central Tendency and Dispersion: Unit-3 Basic StatisticsSandip MouryaNoch keine Bewertungen
- Section 10 Discrete Time Markov ChainsDokument17 SeitenSection 10 Discrete Time Markov ChainsDylan LerNoch keine Bewertungen
- Uncertainty: CSE-345: Artificial IntelligenceDokument30 SeitenUncertainty: CSE-345: Artificial IntelligenceFariha OisyNoch keine Bewertungen