Das könnte Ihnen auch gefallen
- High Performance GCM Architecture For The Security of High Speed NetworkDokument19 SeitenHigh Performance GCM Architecture For The Security of High Speed NetworkAnand Parakkat ParambilNoch keine Bewertungen
- Applied Sciences: PAGE-Practical AES-GCM Encryption For Low-End MicrocontrollersDokument14 SeitenApplied Sciences: PAGE-Practical AES-GCM Encryption For Low-End MicrocontrollersAnand Parakkat ParambilNoch keine Bewertungen
- An End-To-End Hardware Approach Security For The GPRS: Direction CB, AndcearebedDokument4 SeitenAn End-To-End Hardware Approach Security For The GPRS: Direction CB, AndcearebedgermanojoseNoch keine Bewertungen
- An FPGA Implementation of 30Gbps Security Model For GPON SystemsDokument5 SeitenAn FPGA Implementation of 30Gbps Security Model For GPON SystemsNitheshksuvarnaNoch keine Bewertungen
- Design and Implementation of Real Time Aes-128 On Real Time Operating System For Multiple Fpga CommunicationDokument6 SeitenDesign and Implementation of Real Time Aes-128 On Real Time Operating System For Multiple Fpga Communicationmussadaqhussain8210Noch keine Bewertungen
- Hardware Implementation of AES Encryption and Decryption System Based On FPGADokument5 SeitenHardware Implementation of AES Encryption and Decryption System Based On FPGAاليزيد بن توهاميNoch keine Bewertungen
- CRYPTACUS 2018 Paper 30 PDFDokument4 SeitenCRYPTACUS 2018 Paper 30 PDFMircea PetrescuNoch keine Bewertungen
- GCM SpecDokument43 SeitenGCM SpecjdhffszlagsxyvNoch keine Bewertungen
- Abstract - The Choice of A Platform, Software, ASIC Or: Ntroduction Algorithm Analysis and ImplementationDokument4 SeitenAbstract - The Choice of A Platform, Software, ASIC Or: Ntroduction Algorithm Analysis and ImplementationMustafamna Al SalamNoch keine Bewertungen
- Homomorphic Evaluation of The AES CircuitDokument18 SeitenHomomorphic Evaluation of The AES CircuitDavid CoxNoch keine Bewertungen
- V1.IJETAE 0318 49paperpublicationDokument7 SeitenV1.IJETAE 0318 49paperpublicationMohamed SolimanNoch keine Bewertungen
- Image Encryption Based On AES Stream Cipher in Counter ModeDokument5 SeitenImage Encryption Based On AES Stream Cipher in Counter ModeReferatScoalaNoch keine Bewertungen
- An Efficient Hardware Design and Implementation of Advanced Encryption Standard (AES) AlgorithmDokument5 SeitenAn Efficient Hardware Design and Implementation of Advanced Encryption Standard (AES) AlgorithmmianNoch keine Bewertungen
- Study of Data Security Algorithms Using Verilog HDL: International Journal of Electrical and Computer Engineering (IJECE)Dokument10 SeitenStudy of Data Security Algorithms Using Verilog HDL: International Journal of Electrical and Computer Engineering (IJECE)murali036Noch keine Bewertungen
- Data EncrytipnDokument5 SeitenData EncrytipnRajan MiglaniNoch keine Bewertungen
- Brief Contributions: Packed AES-GCM Algorithm Suitable For AES/PCLMULQDQ InstructionsDokument4 SeitenBrief Contributions: Packed AES-GCM Algorithm Suitable For AES/PCLMULQDQ InstructionsAnand Parakkat ParambilNoch keine Bewertungen
- An Efficient and High-Speed Overlap-Free Karatsuba-Based Finite-Field Multiplier For FGPA ImplementationDokument10 SeitenAn Efficient and High-Speed Overlap-Free Karatsuba-Based Finite-Field Multiplier For FGPA ImplementationReza BarkhordariNoch keine Bewertungen
- Sobhiafshar 2009Dokument14 SeitenSobhiafshar 2009mohamedezzelden30Noch keine Bewertungen
- 6614 Ijcsit 03Dokument21 Seiten6614 Ijcsit 03Anonymous Gl4IRRjzNNoch keine Bewertungen
- Performance of Symmetric Ciphers and One-Way Hash Functions: 1 RationaleDokument7 SeitenPerformance of Symmetric Ciphers and One-Way Hash Functions: 1 RationaleThanh PhamNoch keine Bewertungen
- Ieee 2007zk2Dokument6 SeitenIeee 2007zk2Yonas GhiwotNoch keine Bewertungen
- Parallel AES Encryption EnginesDokument12 SeitenParallel AES Encryption EnginesmohamedNoch keine Bewertungen
- Arm Recognition Encryption by Using Aes AlgorithmDokument5 SeitenArm Recognition Encryption by Using Aes AlgorithmInternational Journal of Research in Engineering and TechnologyNoch keine Bewertungen
- 18 Parul Rajoriya v2 I2Dokument4 Seiten18 Parul Rajoriya v2 I2arthi pandiNoch keine Bewertungen
- Hardware Implementation of Aes-Ccm For Robust Secure Wireless NetworkDokument8 SeitenHardware Implementation of Aes-Ccm For Robust Secure Wireless NetworkMustafamna Al SalamNoch keine Bewertungen
- Simple Error Detection Methods For Hardware Implementation of Advanced Encryption StandardDokument12 SeitenSimple Error Detection Methods For Hardware Implementation of Advanced Encryption StandardMn RajuNoch keine Bewertungen
- Zede 26Dokument84 SeitenZede 26sumi_phdNoch keine Bewertungen
- Implementation of Aes and Rsa Algorithm On Hardware PlatformDokument5 SeitenImplementation of Aes and Rsa Algorithm On Hardware PlatformHanin TANoch keine Bewertungen
- FPGA Implementation of AES Encryption and DecryptionDokument16 SeitenFPGA Implementation of AES Encryption and DecryptionSatya NarayanaNoch keine Bewertungen
- An Efficient Multimode Multiplier Supporting AES and Fundamental Operations of Public-Key CryptosystemsDokument11 SeitenAn Efficient Multimode Multiplier Supporting AES and Fundamental Operations of Public-Key CryptosystemsVimala PriyaNoch keine Bewertungen
- A Comparative Analysis ofDokument4 SeitenA Comparative Analysis ofMajid KhanNoch keine Bewertungen
- Efficient Aes-Gcm For Vpns Using FpgasDokument4 SeitenEfficient Aes-Gcm For Vpns Using FpgasAnand Parakkat ParambilNoch keine Bewertungen
- Comparison of Encryption Algorithms: AES, Blowfish and Twofish For Security of Wireless NetworksDokument5 SeitenComparison of Encryption Algorithms: AES, Blowfish and Twofish For Security of Wireless NetworksPuji SetiadiNoch keine Bewertungen
- Pipeline Dae S With FeedbackDokument10 SeitenPipeline Dae S With Feedbackyame asfiaNoch keine Bewertungen
- A New Lightweight Cryptographic Algorithm For Enhancing Data Security in Cloud ComputingDokument5 SeitenA New Lightweight Cryptographic Algorithm For Enhancing Data Security in Cloud Computingraounek arifNoch keine Bewertungen
- On Modes of Operations of A Block Cipher For Authentication and Authenticated EncryptionDokument46 SeitenOn Modes of Operations of A Block Cipher For Authentication and Authenticated EncryptionNguyễn ThắngNoch keine Bewertungen
- Hamming Code PDFDokument4 SeitenHamming Code PDFFind ProgrammerNoch keine Bewertungen
- Cast AES IP OverviewDokument10 SeitenCast AES IP OverviewMn RajuNoch keine Bewertungen
- Peformance Analysis and Implementation of Scalable Encryption Algorithm On FpgaDokument6 SeitenPeformance Analysis and Implementation of Scalable Encryption Algorithm On FpgaVijay KannamallaNoch keine Bewertungen
- Encryption Implementation of Rock Cipher Based On FPGA: Murtada Mohamed Abdelwahab, Abdul Rasoul Jabar AlzubaidiDokument7 SeitenEncryption Implementation of Rock Cipher Based On FPGA: Murtada Mohamed Abdelwahab, Abdul Rasoul Jabar AlzubaidiIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNoch keine Bewertungen
- Mix Colomns Using Galois FeildDokument10 SeitenMix Colomns Using Galois Feildbit09486Noch keine Bewertungen
- Crypto AssignmentDokument9 SeitenCrypto AssignmentEdinamobongNoch keine Bewertungen
- Design and Implementation of Area Optimized AES With Modified S-Box Using Pipelining TechnologyDokument6 SeitenDesign and Implementation of Area Optimized AES With Modified S-Box Using Pipelining Technologysudhakar5472Noch keine Bewertungen
- TASTY-Tool For Automating Secure Two-partYDokument16 SeitenTASTY-Tool For Automating Secure Two-partYShah AzNoch keine Bewertungen
- Simulation of Image Encryption Using AES AlgorithmDokument8 SeitenSimulation of Image Encryption Using AES AlgorithmSunil ChoudharyNoch keine Bewertungen
- Secure Arithmetic CodingDokument10 SeitenSecure Arithmetic CodingAnil Kumar BNoch keine Bewertungen
- Implementation of Aes-128 Cryptography On Unmanned Aerial Vechile and Ground Control SystemDokument9 SeitenImplementation of Aes-128 Cryptography On Unmanned Aerial Vechile and Ground Control Systempaney93346Noch keine Bewertungen
- Design and Implementation of Efficient Advanced Encryption Standard Composite S-Box With CM-ModeDokument9 SeitenDesign and Implementation of Efficient Advanced Encryption Standard Composite S-Box With CM-Modegunasekaran kNoch keine Bewertungen
- Aes 256 FpgaDokument4 SeitenAes 256 FpgaabhishekNoch keine Bewertungen
- Final PPT of CCSDS TC SystemDokument38 SeitenFinal PPT of CCSDS TC SystemNavakanth Bydeti0% (1)
- A VHDL Implementation of The Hummingbird Cryptographic AlgorithmDokument4 SeitenA VHDL Implementation of The Hummingbird Cryptographic Algorithmanon_287498671Noch keine Bewertungen
- Ieee 05486259Dokument6 SeitenIeee 05486259Abolfazl MazloomiNoch keine Bewertungen
- General Packet Radio Service Physical-Layer Performance SimulationDokument6 SeitenGeneral Packet Radio Service Physical-Layer Performance SimulationAdeeb HusnainNoch keine Bewertungen
- Fast But Approximate Homomorphic Technique: K-Means Based On MaskingDokument15 SeitenFast But Approximate Homomorphic Technique: K-Means Based On MaskingkumaranurupamNoch keine Bewertungen
- Parallel Implementation of AES On 2.5D Multicore PlatformDokument4 SeitenParallel Implementation of AES On 2.5D Multicore Platformg.divya0612Noch keine Bewertungen
- The Tweakable Block Cipher Family: Qarmav2Dokument49 SeitenThe Tweakable Block Cipher Family: Qarmav2Nirban DasNoch keine Bewertungen
- Fast Falcon Signature Generation and Verification pqc2022Dokument29 SeitenFast Falcon Signature Generation and Verification pqc2022VentuSarasaLabordaNoch keine Bewertungen
- Efficient and High-Throughput Implementations of AES-GCM FpgasDokument8 SeitenEfficient and High-Throughput Implementations of AES-GCM FpgasAnand Parakkat ParambilNoch keine Bewertungen
- Application and Implementation of DES Algorithm Based on FPGAVon EverandApplication and Implementation of DES Algorithm Based on FPGANoch keine Bewertungen
- A SECURE DATA AGGREGATION TECHNIQUE IN WIRELESS SENSOR NETWORKVon EverandA SECURE DATA AGGREGATION TECHNIQUE IN WIRELESS SENSOR NETWORKNoch keine Bewertungen
- 14 - Chapter 6 PDFDokument25 Seiten14 - Chapter 6 PDFrene_brookeNoch keine Bewertungen
- HjgfvyjfviDokument19 SeitenHjgfvyjfvirene_brookeNoch keine Bewertungen
- Wright1189835736 PDFDokument74 SeitenWright1189835736 PDFrene_brookeNoch keine Bewertungen
- 11 - Chapter 3 PDFDokument48 Seiten11 - Chapter 3 PDFrene_brookeNoch keine Bewertungen
- 10 - Chapter 2 PDFDokument22 Seiten10 - Chapter 2 PDFrene_brookeNoch keine Bewertungen
- 10 - Chapter 1 PDFDokument6 Seiten10 - Chapter 1 PDFrene_brookeNoch keine Bewertungen
- Cost Current Coverage Capacity Four C's of LPWA : Standards-Based AdvantagesDokument1 SeiteCost Current Coverage Capacity Four C's of LPWA : Standards-Based Advantagesrene_brookeNoch keine Bewertungen
- Words Can't Espresso How Much You Bean To MeDokument2 SeitenWords Can't Espresso How Much You Bean To Merene_brookeNoch keine Bewertungen
- Test 54745Dokument17 SeitenTest 54745rene_brookeNoch keine Bewertungen
- Chara's Physical ChemDokument3 SeitenChara's Physical Chemrene_brookeNoch keine Bewertungen
- Group 10 CT Assignment 1Dokument36 SeitenGroup 10 CT Assignment 1rene_brookeNoch keine Bewertungen
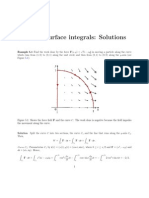
- Line and Surface Integrals: Solutions: Example 5.1Dokument7 SeitenLine and Surface Integrals: Solutions: Example 5.1Paul Reyna RojasNoch keine Bewertungen
- Chara's Physical ChemDokument3 SeitenChara's Physical Chemrene_brookeNoch keine Bewertungen
- Moparm Action - December 2014 USADokument100 SeitenMoparm Action - December 2014 USAenricoioNoch keine Bewertungen
- G JaxDokument4 SeitenG Jaxlevin696Noch keine Bewertungen
- How Can You Achieve Safety and Profitability ?Dokument32 SeitenHow Can You Achieve Safety and Profitability ?Mohamed OmarNoch keine Bewertungen
- Financial StatementDokument8 SeitenFinancial StatementDarwin Dionisio ClementeNoch keine Bewertungen
- Karmex 80df Diuron MsdsDokument9 SeitenKarmex 80df Diuron MsdsSouth Santee Aquaculture100% (1)
- Tle 9 Module 1 Final (Genyo)Dokument7 SeitenTle 9 Module 1 Final (Genyo)MrRightNoch keine Bewertungen
- h6811 Datadomain DsDokument5 Seitenh6811 Datadomain DsChristian EstebanNoch keine Bewertungen
- Business Occupancy ChecklistDokument5 SeitenBusiness Occupancy ChecklistRozel Laigo ReyesNoch keine Bewertungen
- ADS Chapter 303 Grants and Cooperative Agreements Non USDokument81 SeitenADS Chapter 303 Grants and Cooperative Agreements Non USMartin JcNoch keine Bewertungen
- CC Anbcc FD 002 Enr0Dokument5 SeitenCC Anbcc FD 002 Enr0ssierroNoch keine Bewertungen
- Computer System Sevicing NC Ii: SectorDokument44 SeitenComputer System Sevicing NC Ii: SectorJess QuizzaganNoch keine Bewertungen
- Expected MCQs CompressedDokument31 SeitenExpected MCQs CompressedAdithya kesavNoch keine Bewertungen
- Atom Medical Usa Model 103 Infa Warmer I - 2 PDFDokument7 SeitenAtom Medical Usa Model 103 Infa Warmer I - 2 PDFLuqman BhanuNoch keine Bewertungen
- Introduction To Radar Warning ReceiverDokument23 SeitenIntroduction To Radar Warning ReceiverPobitra Chele100% (1)
- SPIE Oil & Gas Services: Pressure VesselsDokument56 SeitenSPIE Oil & Gas Services: Pressure VesselsSadashiw PatilNoch keine Bewertungen
- MOL Breaker 20 TonDokument1 SeiteMOL Breaker 20 Tonaprel jakNoch keine Bewertungen
- T R I P T I C K E T: CTRL No: Date: Vehicle/s EquipmentDokument1 SeiteT R I P T I C K E T: CTRL No: Date: Vehicle/s EquipmentJapCon HRNoch keine Bewertungen
- Change Language DynamicallyDokument3 SeitenChange Language DynamicallySinan YıldızNoch keine Bewertungen
- DTMF Controlled Robot Without Microcontroller (Aranju Peter)Dokument10 SeitenDTMF Controlled Robot Without Microcontroller (Aranju Peter)adebayo gabrielNoch keine Bewertungen
- Project 1. RockCrawlingDokument2 SeitenProject 1. RockCrawlingHằng MinhNoch keine Bewertungen
- Jainithesh - Docx CorrectedDokument54 SeitenJainithesh - Docx CorrectedBala MuruganNoch keine Bewertungen
- Alphacenter Utilities: Installation GuideDokument24 SeitenAlphacenter Utilities: Installation GuideJeffersoOnn JulcamanyanNoch keine Bewertungen
- Lps - Config Doc of Fm-BcsDokument37 SeitenLps - Config Doc of Fm-Bcsraj01072007Noch keine Bewertungen
- Marshall Baillieu: Ian Marshall Baillieu (Born 6 June 1937) Is A Former AustralianDokument3 SeitenMarshall Baillieu: Ian Marshall Baillieu (Born 6 June 1937) Is A Former AustralianValenVidelaNoch keine Bewertungen
- SWOT AnalysisDokument6 SeitenSWOT AnalysisSSPK_92Noch keine Bewertungen
- 7933-Article Text-35363-1-10-20230724Dokument8 Seiten7933-Article Text-35363-1-10-20230724Ridho HidayatNoch keine Bewertungen
- DevelopersDokument88 SeitenDevelopersdiegoesNoch keine Bewertungen
- Labor Law 1Dokument24 SeitenLabor Law 1Naomi Cartagena100% (1)
- European Steel and Alloy Grades: 16Mncr5 (1.7131)Dokument3 SeitenEuropean Steel and Alloy Grades: 16Mncr5 (1.7131)farshid KarpasandNoch keine Bewertungen
- Company Law Handout 3Dokument10 SeitenCompany Law Handout 3nicoleclleeNoch keine Bewertungen