Das könnte Ihnen auch gefallen
- ItgcDokument14 SeitenItgckadimustapha05Noch keine Bewertungen
- Cours EchantillonnageDokument90 SeitenCours Echantillonnagefourat.zarkounaNoch keine Bewertungen
- Signification StatistiqueDokument13 SeitenSignification StatistiqueSalim H.Noch keine Bewertungen
- StatistiquesDokument104 SeitenStatistiquesalibenhamida5725100% (1)
- Le Data MiningDokument5 SeitenLe Data MiningizmNoch keine Bewertungen
- Culture Champignon Au CongoDokument6 SeitenCulture Champignon Au CongoladjoNoch keine Bewertungen
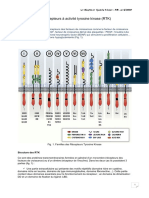
- Récepteurs À Activité Tyrosine Kinase DefDokument12 SeitenRécepteurs À Activité Tyrosine Kinase DefFatima ZahraNoch keine Bewertungen
- Angrais Atouts Et Fléau-1Dokument8 SeitenAngrais Atouts Et Fléau-1Jovanie Kouedji100% (1)
- Etude de Faisabilite D Une Plantation D Agrume Variete Washington Sanguine PDFDokument13 SeitenEtude de Faisabilite D Une Plantation D Agrume Variete Washington Sanguine PDFMouslehOuazzaniNoch keine Bewertungen
- Modele CVDokument6 SeitenModele CVMamadou GueyeNoch keine Bewertungen
- Cours Biostatistique - M1 - ENSAF - 2020-2021Dokument61 SeitenCours Biostatistique - M1 - ENSAF - 2020-2021Gervais Mbahouka100% (1)
- PreDokument21 SeitenPreManelNoch keine Bewertungen
- Cours SVT-Inter TC - ECO-Chap 2 PDFDokument15 SeitenCours SVT-Inter TC - ECO-Chap 2 PDFGauss Must40% (5)
- Mesures de La BiodiversiteDokument79 SeitenMesures de La BiodiversiteSitta LedantiNoch keine Bewertungen
- Elévage Des LapinsDokument45 SeitenElévage Des LapinsLeo JospinhoNoch keine Bewertungen
- Amélioration GénétiqueDokument46 SeitenAmélioration GénétiqueISSAMNoch keine Bewertungen
- Champignons Culture Et Integration Dans Les Pratiques Agricoles PDFDokument32 SeitenChampignons Culture Et Integration Dans Les Pratiques Agricoles PDFMaurice Siloe MbilanjiNoch keine Bewertungen
- Décision Et Prévision Statistique Mines Nancy Résumés de CoursDokument12 SeitenDécision Et Prévision Statistique Mines Nancy Résumés de CoursPascal GuihéneufNoch keine Bewertungen
- TPNutritionMinérale 09 10Dokument4 SeitenTPNutritionMinérale 09 10[AE]100% (1)
- 12 - Second MessagersDokument151 Seiten12 - Second MessagersAmal DghoughiNoch keine Bewertungen
- Fiche de Projet 207 BELDokument3 SeitenFiche de Projet 207 BELMo100% (1)
- Rapport D'articleDokument4 SeitenRapport D'articleSaby Med100% (1)
- BIO 1700 Cours 2 2022Dokument127 SeitenBIO 1700 Cours 2 2022BalkisBenHassineNoch keine Bewertungen
- Module de Statistique Licence ProtectionDokument39 SeitenModule de Statistique Licence ProtectionBlast MindNoch keine Bewertungen
- Cours de Biométrie Facgro UCBDokument88 SeitenCours de Biométrie Facgro UCBGloireNoch keine Bewertungen
- Presentation Maths13Dokument16 SeitenPresentation Maths13Said MahmoudiNoch keine Bewertungen
- Examen GénéralDokument43 SeitenExamen GénéralBadre OuzougarNoch keine Bewertungen
- Choix Des Tests Et Analyses Statistiques V2Dokument88 SeitenChoix Des Tests Et Analyses Statistiques V2carmen84100% (1)
- 14 GlossaireDokument10 Seiten14 GlossairedorisseNoch keine Bewertungen
- 10 AS 1249 - OkDokument13 Seiten10 AS 1249 - OkFousseyni TRAORENoch keine Bewertungen
- Cours BV - S2 - Biologie Des Champignons SVT S2 PDFDokument33 SeitenCours BV - S2 - Biologie Des Champignons SVT S2 PDFNabil holmesNoch keine Bewertungen
- TD #1 BMGG 2020-2021Dokument2 SeitenTD #1 BMGG 2020-2021serinebousehababenkNoch keine Bewertungen
- 01 Ecologie Fondamentale 1 FinalDokument33 Seiten01 Ecologie Fondamentale 1 FinalBilal AliouneNoch keine Bewertungen
- These 636930124588635155 PDFDokument220 SeitenThese 636930124588635155 PDFGueye KéassaNoch keine Bewertungen
- Guide Entreprise Agroforesterie CacaoDokument80 SeitenGuide Entreprise Agroforesterie CacaoTougma JulinoNoch keine Bewertungen
- Rapport Les Hormone Vegetaux AuxineDokument14 SeitenRapport Les Hormone Vegetaux AuxineAhmedIslmiounNoch keine Bewertungen
- Suivi Des Paramètre Physico Chimique de L'huile de SojaDokument7 SeitenSuivi Des Paramètre Physico Chimique de L'huile de SojaBabbel TyzanNoch keine Bewertungen
- Conditions D'Uti1, Isation de La Methode - de L'Amidon Des Tubercules Tropicaux Cultlves Cameroun" Polarimetrique Pour Le DosageDokument11 SeitenConditions D'Uti1, Isation de La Methode - de L'Amidon Des Tubercules Tropicaux Cultlves Cameroun" Polarimetrique Pour Le DosageAmirou Baby MixicoNoch keine Bewertungen
- Dynamiques de PopulationDokument17 SeitenDynamiques de PopulationEaNoch keine Bewertungen
- Support de Cours AgroDokument25 SeitenSupport de Cours AgroyssoufNoch keine Bewertungen
- Chapitre 1Dokument25 SeitenChapitre 1MOHAMED HAITAM ZOUBIRNoch keine Bewertungen
- Article 022Dokument12 SeitenArticle 022Marie DucellNoch keine Bewertungen
- Puce À ADNDokument16 SeitenPuce À ADNElkhatibi Fatima-EzzahraNoch keine Bewertungen
- TMP - 32685 Memoire Licence Pro TOUKAM Ulrich Arsene1626048646Dokument69 SeitenTMP - 32685 Memoire Licence Pro TOUKAM Ulrich Arsene1626048646Onguene Syntia100% (1)
- 4°gestion Des Resssources Phytogénétiques (RPG)Dokument33 Seiten4°gestion Des Resssources Phytogénétiques (RPG)Faiza HaminiNoch keine Bewertungen
- Reussir Ses VeauxDokument68 SeitenReussir Ses VeauxPERRINNoch keine Bewertungen
- 17-Techniques de Biologie MoléculaireDokument76 Seiten17-Techniques de Biologie MoléculaireInsafNoch keine Bewertungen
- PROTÉOMIQUEDokument9 SeitenPROTÉOMIQUECours facNoch keine Bewertungen
- Chapitre III - Physiologie de La DigestionDokument9 SeitenChapitre III - Physiologie de La Digestionchaima TEMMAMNoch keine Bewertungen
- TP Initiation À La Recherche Scientifique PPDokument17 SeitenTP Initiation À La Recherche Scientifique PPChawki MokademNoch keine Bewertungen
- Ex2012 ExperimentationDokument414 SeitenEx2012 ExperimentationWafia Nihad LAROUINoch keine Bewertungen
- Exercices Corrigés SMDokument31 SeitenExercices Corrigés SMVICO YTNoch keine Bewertungen
- La Filiere Œuf, Pole DuDokument75 SeitenLa Filiere Œuf, Pole DuNianjara RazafindrainibeNoch keine Bewertungen
- Cours Biodiversité Et Changements Globaux L3 Ecologie Et Environnement Mm. Senouci F.Dokument30 SeitenCours Biodiversité Et Changements Globaux L3 Ecologie Et Environnement Mm. Senouci F.Roumaissa BouhadjabNoch keine Bewertungen
- Protection Des Cultures (Ravageurs)Dokument123 SeitenProtection Des Cultures (Ravageurs)Abdelghani Makkaoui100% (1)
- Présentation - Biosécurité en Aquaculture - YF-20230821Dokument65 SeitenPrésentation - Biosécurité en Aquaculture - YF-20230821BoyeNoch keine Bewertungen
- La situation mondiale des pêches et de l’aquaculture 2020: La durabilité an actionVon EverandLa situation mondiale des pêches et de l’aquaculture 2020: La durabilité an actionNoch keine Bewertungen
- L’État de la sécurité alimentaire et de la nutrition dans le monde 2019: Se prémunir contre les ralentissements et les fléchissements économiquesVon EverandL’État de la sécurité alimentaire et de la nutrition dans le monde 2019: Se prémunir contre les ralentissements et les fléchissements économiquesNoch keine Bewertungen
- L’État de la sécurité alimentaire et de la nutrition dans le monde 2022: Réorienter les politiques alimentaires et agricoles pour rendre l’alimentation saine plus abordableVon EverandL’État de la sécurité alimentaire et de la nutrition dans le monde 2022: Réorienter les politiques alimentaires et agricoles pour rendre l’alimentation saine plus abordableNoch keine Bewertungen
- Présentation des programmes de protection sociale sensibles au genre visant à lutter contre la pauvreté rurale: pourquoi sont-ils importants et en quoi consistent-ils? – Guide technique 1 de la FAOVon EverandPrésentation des programmes de protection sociale sensibles au genre visant à lutter contre la pauvreté rurale: pourquoi sont-ils importants et en quoi consistent-ils? – Guide technique 1 de la FAONoch keine Bewertungen
- Chapitre 1: Les Sciences SocialesDokument3 SeitenChapitre 1: Les Sciences SocialesSimone EngouangNoch keine Bewertungen
- Préparer Un Projet de Thèse SolideDokument10 SeitenPréparer Un Projet de Thèse SolideAzziz HaydarNoch keine Bewertungen
- Interprétation SPSSDokument2 SeitenInterprétation SPSSnouhaila safineNoch keine Bewertungen
- Cours 2 - EDMDokument5 SeitenCours 2 - EDMNądjęt ÝhNoch keine Bewertungen
- Réponse Haemonetics - Août 2019Dokument2 SeitenRéponse Haemonetics - Août 2019Cellule investigation de Radio France0% (1)
- Points Clefs QCMDokument2 SeitenPoints Clefs QCMarmandNoch keine Bewertungen
- Projet Plan MaintenanceDokument19 SeitenProjet Plan MaintenanceHaytem ChhimiNoch keine Bewertungen
- ANOVAFR171206Dokument50 SeitenANOVAFR171206Rida OumoussaNoch keine Bewertungen
- Plan D'échantillonnageDokument26 SeitenPlan D'échantillonnageHamza ElmouhtadiNoch keine Bewertungen
- EmiDokument21 SeitenEmihamza chadliNoch keine Bewertungen
- Le Marketing D'influence Au MarocDokument21 SeitenLe Marketing D'influence Au Marocsasou SIwar0% (1)
- 04 Fortis Grinevald Kopecka VittrantDokument10 Seiten04 Fortis Grinevald Kopecka VittrantPaco Melero RomeroNoch keine Bewertungen
- COURS DE PROBABILITESetSTATISTIQUES - LPSICS-1Dokument34 SeitenCOURS DE PROBABILITESetSTATISTIQUES - LPSICS-1ugwaystemaNoch keine Bewertungen
- Benguigui Geitzholz Karene 2019Dokument346 SeitenBenguigui Geitzholz Karene 2019Roldy OtesNoch keine Bewertungen
- Examen TE 2020-5 PagesDokument5 SeitenExamen TE 2020-5 PagesZarrouk MohamedNoch keine Bewertungen
- Wcms - 114164 GUIDE Ilo CradatDokument202 SeitenWcms - 114164 GUIDE Ilo CradatmfaglaNoch keine Bewertungen
- TD 06 07Dokument11 SeitenTD 06 07zenonibrahimNoch keine Bewertungen
- Les Erreurs de Prononciation Les Plus Communes Des Étudiants de FrançaisDokument89 SeitenLes Erreurs de Prononciation Les Plus Communes Des Étudiants de FrançaisRayan DNoch keine Bewertungen