Das könnte Ihnen auch gefallen
- Calculus of Variation Assignment-1 (J-2023)Dokument2 SeitenCalculus of Variation Assignment-1 (J-2023)Sameer BhattaNoch keine Bewertungen
- Instant Assessments for Data Tracking, Grade 3: MathVon EverandInstant Assessments for Data Tracking, Grade 3: MathBewertung: 5 von 5 Sternen5/5 (2)
- Quadratic Equation WeeblyDokument3 SeitenQuadratic Equation Weeblyapi-633813701Noch keine Bewertungen
- Aula Funcoes AnaliticasDokument104 SeitenAula Funcoes AnaliticasMatheus de Oliveira dos SantosNoch keine Bewertungen
- Instant Assessments for Data Tracking, Grade K: Language ArtsVon EverandInstant Assessments for Data Tracking, Grade K: Language ArtsNoch keine Bewertungen
- Quadratic Function-1Dokument8 SeitenQuadratic Function-1Nabil MahdarNoch keine Bewertungen
- Instant Assessments for Data Tracking, Grade 5: MathVon EverandInstant Assessments for Data Tracking, Grade 5: MathNoch keine Bewertungen
- MHF4U Unit 1 Polynomial Functions HomeworkDokument31 SeitenMHF4U Unit 1 Polynomial Functions HomeworkTony ParkNoch keine Bewertungen
- Instant Assessments for Data Tracking, Grade 2: Language ArtsVon EverandInstant Assessments for Data Tracking, Grade 2: Language ArtsNoch keine Bewertungen
- Sec V TS Mathematics Term 2 - Unit 2 - Absolute Value FunctionDokument16 SeitenSec V TS Mathematics Term 2 - Unit 2 - Absolute Value FunctionDanyal PuglisiNoch keine Bewertungen
- Sat Math Formula Practice - e Math AcademyDokument6 SeitenSat Math Formula Practice - e Math AcademytinlongNoch keine Bewertungen
- 5 - Solving Quadratic Equations by Completing The SquareDokument3 Seiten5 - Solving Quadratic Equations by Completing The Squareed boNoch keine Bewertungen
- 04 Greedy Algorithms IDokument44 Seiten04 Greedy Algorithms IAlexandar MahoneNoch keine Bewertungen
- Evaluating Definite Integrals PDFDokument3 SeitenEvaluating Definite Integrals PDFJose Barrera GaleraNoch keine Bewertungen
- Mental Math Slide ShowDokument22 SeitenMental Math Slide Showapi-250788050Noch keine Bewertungen
- 3 3 Iterative Methods ME 310 Fall 2020Dokument12 Seiten3 3 Iterative Methods ME 310 Fall 2020Ege UygunturkNoch keine Bewertungen
- New CZ3005 Module 3 - Constraint Satisfaction and Adversarial SearchDokument53 SeitenNew CZ3005 Module 3 - Constraint Satisfaction and Adversarial Searchkellen tseNoch keine Bewertungen
- MATLABAssignmentDokument5 SeitenMATLABAssignmentvenkieeNoch keine Bewertungen
- 3 - Equation of A LineDokument3 Seiten3 - Equation of A Linesmith0% (1)
- Tutorial 8 - System of Equations - InequalitiesDokument29 SeitenTutorial 8 - System of Equations - InequalitiesNguyễn Trọng HiếuNoch keine Bewertungen
- 1.4 Eight Basic Functions - WorksheetDokument3 Seiten1.4 Eight Basic Functions - WorksheetTessa_Gray_Noch keine Bewertungen
- Lec4 GreedyAlgorithmsIDokument76 SeitenLec4 GreedyAlgorithmsIThomasNoch keine Bewertungen
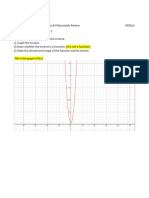
- Lesson 5 - Inverses of Functions & Polynomials ReviewDokument9 SeitenLesson 5 - Inverses of Functions & Polynomials ReviewdudoocandrawNoch keine Bewertungen
- Basic Cartesian GraphsDokument10 SeitenBasic Cartesian GraphsJesus David Sierra TaberaNoch keine Bewertungen
- WB2235 ExerciseSession2 Problems 2023 1Dokument2 SeitenWB2235 ExerciseSession2 Problems 2023 1Max AdelingNoch keine Bewertungen
- Key IdeasDokument2 SeitenKey Ideasapi-259566515Noch keine Bewertungen
- Ee361 Mid1 Sp2021 Q1-2Dokument1 SeiteEe361 Mid1 Sp2021 Q1-2Seb SebNoch keine Bewertungen
- Lesson 8 2Dokument2 SeitenLesson 8 2k8nowakNoch keine Bewertungen
- Exponentials PDFDokument9 SeitenExponentials PDFAhmad ELZohairyNoch keine Bewertungen
- PMU1 Assessment1Dokument1 SeitePMU1 Assessment1Kaye ArcherNoch keine Bewertungen
- Determinant CalculationsDokument32 SeitenDeterminant Calculationsteatrosantagadea1Noch keine Bewertungen
- EECE 5639 Computer Vision I: Coordinate Systems Transformations, ColorDokument50 SeitenEECE 5639 Computer Vision I: Coordinate Systems Transformations, ColorSourabh Sisodia SrßNoch keine Bewertungen
- Pre Cal-Q1 M2 PARABOLA FinDokument17 SeitenPre Cal-Q1 M2 PARABOLA FinDanny Lloyd Asan BuenafeNoch keine Bewertungen
- Transformation 4 HelpDokument3 SeitenTransformation 4 HelpMc LovinNoch keine Bewertungen
- Lecture 2Dokument69 SeitenLecture 2erickNoch keine Bewertungen
- Microsoft Word - 1.1 WorksheetDokument6 SeitenMicrosoft Word - 1.1 WorksheetManya MNoch keine Bewertungen
- 77Dokument60 Seiten77Jana AlqahtaniNoch keine Bewertungen
- Hannah Ness - Graphing+Pracitce+ (STUDENT)Dokument2 SeitenHannah Ness - Graphing+Pracitce+ (STUDENT)Hannah NessNoch keine Bewertungen
- ProportionDokument2 SeitenProportionRiddhi KhandelwalNoch keine Bewertungen
- Chapter 3: Dislocations in Crystals: Young's ModulusDokument67 SeitenChapter 3: Dislocations in Crystals: Young's Modulusjohn parkerNoch keine Bewertungen
- Comprobamos nuestros aprendizajes sobre operaciones con fraccionesDokument3 SeitenComprobamos nuestros aprendizajes sobre operaciones con fraccionesdarlia caveroNoch keine Bewertungen
- Centroid: Centre of GravityDokument32 SeitenCentroid: Centre of Gravitysalman husainNoch keine Bewertungen
- Section 2.3 Polynomial Functions and Their GraphsDokument31 SeitenSection 2.3 Polynomial Functions and Their GraphsAlexandria BakerNoch keine Bewertungen
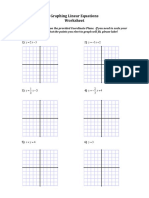
- Graphing Linear Equations Worksheet: 1) y 2x 3 2) y 3x + 2Dokument2 SeitenGraphing Linear Equations Worksheet: 1) y 2x 3 2) y 3x + 2Menilek AlemsegedNoch keine Bewertungen
- Graphing Linear EquationsDokument2 SeitenGraphing Linear EquationsThomas WilsonNoch keine Bewertungen
- Direct VariationDokument4 SeitenDirect VariationDNoch keine Bewertungen
- Math Basic Econ LogDokument1 SeiteMath Basic Econ LogLiv FernandezNoch keine Bewertungen
- Optional Unit 1 AssignmentDokument19 SeitenOptional Unit 1 AssignmentTriet NguyenNoch keine Bewertungen
- Solution of Tutorial 3 of SEEM2440A/B: D C C PD C P C DDokument2 SeitenSolution of Tutorial 3 of SEEM2440A/B: D C C PD C P C DDjy DuhamyNoch keine Bewertungen
- Assignment 1: y y y A A A y yDokument11 SeitenAssignment 1: y y y A A A y yArjun SenguptaNoch keine Bewertungen
- Test-4 Maths SATDokument21 SeitenTest-4 Maths SATLobna El-HosseinyNoch keine Bewertungen
- a2_semester_2_review_answersDokument4 Seitena2_semester_2_review_answersrvmacroNoch keine Bewertungen
- Beam Deflection and Structural Frame AnalysisDokument5 SeitenBeam Deflection and Structural Frame AnalysisMar MartillanoNoch keine Bewertungen
- Daa Lab 2 AKTUDokument7 SeitenDaa Lab 2 AKTUUtpal RaiNoch keine Bewertungen
- Polyint NotesDokument59 SeitenPolyint NotesegemNoch keine Bewertungen
- Ee361 Mid1 Sp2021 Q3-2Dokument1 SeiteEe361 Mid1 Sp2021 Q3-2Seb SebNoch keine Bewertungen
- 03 - Graphing LogarithmsDokument4 Seiten03 - Graphing LogarithmsKirk PolkaNoch keine Bewertungen
- Lecture 5Dokument9 SeitenLecture 5Karen Dayhana Hernadez BustosNoch keine Bewertungen
- 6.453 Quantum Optical Communication Jeffrey H. Shapiro: 6.453 - Lecture 20Dokument6 Seiten6.453 Quantum Optical Communication Jeffrey H. Shapiro: 6.453 - Lecture 20Rahul VasanthNoch keine Bewertungen
- Contact-Ing Schrodinger: B. Quantum TransportDokument6 SeitenContact-Ing Schrodinger: B. Quantum TransportRahul VasanthNoch keine Bewertungen
- Ranjan Bose Information Theory Coding and Cryptography Solution ManualDokument61 SeitenRanjan Bose Information Theory Coding and Cryptography Solution ManualANURAG CHAKRABORTY89% (38)
- QTM2x 2018 28 Circuit QED-slides CompressedDokument12 SeitenQTM2x 2018 28 Circuit QED-slides CompressedRahul VasanthNoch keine Bewertungen
- 6.453 Quantum Optical Communication Jeffrey H. Shapiro: 6.453 - Lecture 22Dokument6 Seiten6.453 Quantum Optical Communication Jeffrey H. Shapiro: 6.453 - Lecture 22Rahul VasanthNoch keine Bewertungen
- QTM2x 2018 27 Majorana Experiments-Slides CompressedDokument8 SeitenQTM2x 2018 27 Majorana Experiments-Slides CompressedRahul VasanthNoch keine Bewertungen
- CBG Cavity v1Dokument10 SeitenCBG Cavity v1Rahul VasanthNoch keine Bewertungen
- Quiz 1 For EE5160: Error Control Coding: Time Limit: 50 Minutes Mar 26, 2021Dokument1 SeiteQuiz 1 For EE5160: Error Control Coding: Time Limit: 50 Minutes Mar 26, 2021Rahul VasanthNoch keine Bewertungen
- Analog Ic Assignment 03Dokument1 SeiteAnalog Ic Assignment 03Rahul VasanthNoch keine Bewertungen
- EE5160 - Error Control Coding Tutorial - Week 02 Code Parameters and ConstructionsDokument3 SeitenEE5160 - Error Control Coding Tutorial - Week 02 Code Parameters and ConstructionsRahul VasanthNoch keine Bewertungen
- Giordano Scappucci: Quantum MaterialsDokument18 SeitenGiordano Scappucci: Quantum MaterialsRahul VasanthNoch keine Bewertungen
- Slot Book - Jul-Nov 2021 - Updated 21.04.2021Dokument8 SeitenSlot Book - Jul-Nov 2021 - Updated 21.04.2021Rahul VasanthNoch keine Bewertungen
- Asset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture11 Compressed PDFDokument27 SeitenAsset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture11 Compressed PDFRahul VasanthNoch keine Bewertungen
- QTM2x 2018 31 Closing Lecture-Slides CompressedDokument10 SeitenQTM2x 2018 31 Closing Lecture-Slides CompressedRahul VasanthNoch keine Bewertungen
- CNNs: Convolutional Neural Networks for Image ClassificationDokument13 SeitenCNNs: Convolutional Neural Networks for Image ClassificationRahul VasanthNoch keine Bewertungen
- Feed-Forward Neural Networks (Part 1)Dokument33 SeitenFeed-Forward Neural Networks (Part 1)Rahul VasanthNoch keine Bewertungen
- Feed-Forward Neural Networks (Part 2: Learning)Dokument17 SeitenFeed-Forward Neural Networks (Part 2: Learning)Rahul VasanthNoch keine Bewertungen
- Modeling Sequences with RNNs (part 1Dokument24 SeitenModeling Sequences with RNNs (part 1Rahul VasanthNoch keine Bewertungen
- Asset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture6 CompressedDokument22 SeitenAsset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture6 CompressedRahul VasanthNoch keine Bewertungen
- ML Lecture 3 Optimization Linear ClassificationDokument15 SeitenML Lecture 3 Optimization Linear ClassificationRahul VasanthNoch keine Bewertungen
- Quantum Notes1 Compressed-13-16Dokument4 SeitenQuantum Notes1 Compressed-13-16Rahul VasanthNoch keine Bewertungen
- ML Lecture 2: Linear Classifiers and the Perceptron AlgorithmDokument21 SeitenML Lecture 2: Linear Classifiers and the Perceptron AlgorithmRahul VasanthNoch keine Bewertungen
- 6th Central Pay Commission Salary CalculatorDokument15 Seiten6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- ML1Dokument27 SeitenML1Rahul VasanthNoch keine Bewertungen
- 6th Central Pay Commission Salary CalculatorDokument15 Seiten6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Introduction To Tools - Python: 1 AssignmentDokument7 SeitenIntroduction To Tools - Python: 1 AssignmentRahul VasanthNoch keine Bewertungen
- Feed-Forward Neural Networks (Part 2: Learning)Dokument17 SeitenFeed-Forward Neural Networks (Part 2: Learning)Rahul VasanthNoch keine Bewertungen
- Quiz I From The Origins of Quantum Theory and Wave Aspects of Matter To The Postulates of Quantum Mechanics and The Schrodinger EquationDokument2 SeitenQuiz I From The Origins of Quantum Theory and Wave Aspects of Matter To The Postulates of Quantum Mechanics and The Schrodinger EquationRahul VasanthNoch keine Bewertungen
- Quiz I From The Origins of Quantum Theory To The Schrodinger Equation in One DimensionDokument2 SeitenQuiz I From The Origins of Quantum Theory To The Schrodinger Equation in One DimensionRahul VasanthNoch keine Bewertungen
- Developing Prototype Rubrics for Assessing Student PerformanceDokument24 SeitenDeveloping Prototype Rubrics for Assessing Student PerformanceNhil Cabillon Quieta0% (1)
- PM620 Unit 4 DBDokument3 SeitenPM620 Unit 4 DBmikeNoch keine Bewertungen
- From - I Like What I Know by Vincent PriceDokument2 SeitenFrom - I Like What I Know by Vincent PricepalpacuixesNoch keine Bewertungen
- Fogg Behavior Grid Guide to 15 TypesDokument2 SeitenFogg Behavior Grid Guide to 15 TypesKarthi RajmohanNoch keine Bewertungen
- Recovered Memories - Repressed Memory AccuracyDokument6 SeitenRecovered Memories - Repressed Memory AccuracysmartnewsNoch keine Bewertungen
- PrefaceDokument3 SeitenPrefaceJagjit SinghNoch keine Bewertungen
- Management Science Group IDokument9 SeitenManagement Science Group Illaneraerika14Noch keine Bewertungen
- Rubrik - OEL ENV ENG LAB - Sem 21920Dokument4 SeitenRubrik - OEL ENV ENG LAB - Sem 21920Susi MulyaniNoch keine Bewertungen
- Reflective JournalDokument2 SeitenReflective Journalaz2500Noch keine Bewertungen
- Innovation at WorkDokument267 SeitenInnovation at WorkAdhiraj A. BhaduriNoch keine Bewertungen
- AIDokument61 SeitenAIमेनसन लाखेमरूNoch keine Bewertungen
- Organization Change and Developement: 'Muddling Through" To Making MillionsDokument8 SeitenOrganization Change and Developement: 'Muddling Through" To Making MillionsNidhi SinghNoch keine Bewertungen
- Literacy Narrative Laisa Mena Rivera 1Dokument4 SeitenLiteracy Narrative Laisa Mena Rivera 1api-644338504Noch keine Bewertungen
- Theories of Risk PerceptionDokument21 SeitenTheories of Risk PerceptionYUKI KONoch keine Bewertungen
- Unit I For Bba CBDokument36 SeitenUnit I For Bba CBPoonam YadavNoch keine Bewertungen
- HM Tourism Planning and DevDokument13 SeitenHM Tourism Planning and DevMemel Falcon GuiralNoch keine Bewertungen
- Ems Guidelines For Thesis ProposalDokument7 SeitenEms Guidelines For Thesis ProposalMeraf EndaleNoch keine Bewertungen
- Colourcon HRMDokument8 SeitenColourcon HRMMohamed SaheelNoch keine Bewertungen
- Translating Cultures - An Introduction For Translators Interpreters and Mediators David KatanDokument141 SeitenTranslating Cultures - An Introduction For Translators Interpreters and Mediators David KatanJeNoc67% (6)
- 900 Items With Answer Key Professional Education NEW CURRICULUMDokument48 Seiten900 Items With Answer Key Professional Education NEW CURRICULUMBM Ayunnie VlogNoch keine Bewertungen
- Ej1060892 PDFDokument12 SeitenEj1060892 PDFfaniNoch keine Bewertungen
- Educational Leadership SkillsDokument4 SeitenEducational Leadership SkillsDesiree Joy Puse Demin-RaitNoch keine Bewertungen
- Organizational Communication Balancing Creativity and Constraint 8th Edition Eisenberg Test BankDokument11 SeitenOrganizational Communication Balancing Creativity and Constraint 8th Edition Eisenberg Test Bankmrericsnowbqygmoctxk93% (14)
- 6 - MODUL Oral Presentation 2014 - MhsDokument24 Seiten6 - MODUL Oral Presentation 2014 - MhsJessille silvNoch keine Bewertungen
- Listening and Vocabulary SkillsDokument6 SeitenListening and Vocabulary SkillsAntonia Bacab CaamalNoch keine Bewertungen
- Mcv4u Course Outline 16Dokument4 SeitenMcv4u Course Outline 16api-323266544Noch keine Bewertungen
- Dissertation Topics Parental InvolvementDokument7 SeitenDissertation Topics Parental InvolvementWriteMyPapersCanada100% (1)
- MAPC MPc007 Ignoupractical DocumentDokument30 SeitenMAPC MPc007 Ignoupractical DocumentPranit Sapkal86% (21)
- Chapter 8 Quality TeamworkDokument2 SeitenChapter 8 Quality TeamworkMarielle Leira C. FernandoNoch keine Bewertungen
- HernándezGarcía Yuridia S4PIDokument3 SeitenHernándezGarcía Yuridia S4PILuis Hernández100% (2)