Education and debate
Evidence base of clinical diagnosis Designing studies to ensure that estimates of test accuracy are transferable
Les Irwig, Patrick Bossuyt, Paul Glasziou, Constantine Gatsonis, Jeroen Lijmer
Measures of test accuracy are often thought of as fixed characteristics determinable by research and then applicable in practice. Yet even when tests are evaluated in a study of adequate qualityone including such features as consecutive patients, a good reference standard, and independent, blinded assessments of tests and the reference standard1performance of a diagnostic test in one setting may vary significantly from the results reported elsewhere.28 In this paper, we explore the reasons for this variability and its implications for the design of studies of diagnostic tests. This is the third in a series of five articles
Screening and Test Evaluation Program, Department of Public Health and Community Medicine, University of Sydney, NSW 2006, Australia Les Irwig professor Department of Clinical Epidemiology and Biostatistics, Academic Medical Centre, PO Box 22700, 1100 DE Amsterdam, Netherlands Patrick Bossuyt professor of clinical epidemiology Jeroen Lijmer clinical researcher School of Population Health, University of Queensland Medical School, Herston, QLD 4006, Australia Paul Glasziou professor of evidence based practice Center for Statistical Sciences, Brown University, Providence, RI 02192, USA Constantine Gatsonis professor Correspondence to: L Irwig lesi@health.usyd. edu.au Series editor: J A Knottnerus
BMJ 2002;324:66971
Summary points
Test accuracy may vary considerably from one setting to another This may be due to the target condition, the clinical problem, what other tests have been done, or how the test is carried out Larger studies than those usually done for diagnostic tests will be needed to assess transferability of results These studies should explore the extent to which variation in test accuracy between populations can be explained by patient and test features
True variability in test accuracy
To interpret a tests results in different setting requires an understanding of whether and why the tests accuracy varies. Broadly speaking, measures of accuracy fall into two broad categories: measures of discrimination between people who are and who are not diseased, and measures of prediction used to estimate post-test probability of disease. Measures of discrimination Global measures of test accuracy assess only the ability of the test to discriminate between people with and without a disease. Common examples are the area under the receiver operating characteristic curve (ROC), and the odds ratio (OR), sometimes also referred to as the diagnostic odds ratio. Such results may suffice for some broad health policy decisionsfor example, to decide whether a new test is in general better than an existing test for the target condition. Measures for prediction The measures used to estimate the probabilities of the target condition in people who have a particular test result require both discrimination and calibration. The predictive valuethe proportion of people with a particular test result who have the disease of interestis an example. It is clumsy and difficult to estimate disease rates for categories of patients who may have different pretest probabilities of having the disease. Therefore, the estimation is often done indirectly using Bayess theorem, based on the pretest probability and measures of test characteristics such as sensitivity and specificity or likelihood ratios in specific patients. These measures of test performance require more than discrimination. They require tests to be calibrated. Transferability of test results The transferability of measures of test performance from one setting to another depends on which indicator of test performance is used. The figure shows the assumptions involved in transferability. The table indicates the relation between these assumptions and the transferability of the different measures of test performance. The main assumptions in transferring tests across settings fall into six categories.
BMJ VOLUME 324 16 MARCH 2002 bmj.com
The definition of disease is constantMany diseases have ambiguous definitions. For example, there are no single reference standards for heart failure, Alzheimers disease, or diabetes. Reference standards may differ because individual investigators conceptual frameworks differ, or because it is difficult to apply the same framework in a standardised way. The same test is usedAlthough based on the same principle, tests may differfor example, over time or if made by different manufacturers. The thresholds between categories of test result (for example, positive and negative) are constantThis is possible with a well standardised test that can be calibrated for different settings. However, there may be no accepted means of calibrationfor example, different observers of imaging tests may have different thresholds for calling an image positive. The effect of different cut-off points is classically studied by use of a receiver operating characteristic curve. In some cases calibration may be improved by using category specific likelihood ratios rather than a single cut-off point.
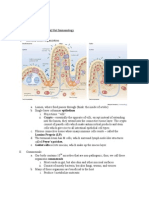
% of group
(5) Non-D distribution
(3) Threshold
(6) Relative frequency
(4) D distribution Non-diseased
Diseased Degree of positivity Negative Positive
Distribution of test results in patients with and without the target disease. The numbers refer to assumptions for the transferability of test results (see text and table)
669
Education and debate
Assumptions for transferring different test performance characteristics (X=important; x=less important)
Assumption* 3 Measures of tests discriminatory power Odds ratio Area under ROC Measures of discriminatory power and calibration Predictive value Sensitivity Specificity Likelihood ratios for multicategory test X X X X X X X X X X X x x Can be used to estimate probability of disease in individuals, using Bayess theorem Directly estimates probability of disease in individuals X X X X X Used for global assessment of discriminatory power and are transferable if assumptions are met. Neither is concerned with calibration and therefore they cannot be used for assessing probability of disease in individuals 4 5 6 Comment
ROC=receiver operating characteristic curve. *Numbered as described in text.
The distribution of test results in the disease group is constant in average (location) and spread (shape)This assumption is not fulfilled if the spectrum of disease changesif, for example, a screening setting is likely to include earlier disease, for which test results will be closer to those for a group without the disease (hence reducing sensitivity). The distribution of test results in the group without disease is constant in average (location) and spread (shape)This assumption is not fulfilled if the spectrum of non-disease changesif, for example, the secondary care setting involves additional causes of false positives due to comorbidity not seen in primary care. The ratio of disease to non-disease (pretest probability) is constantIf this were the case, we could use the post-test probability (predictive values) directly. However, this assumption is often not fulfilledfor example, the pretest probability is likely to be lowest with screening tests and greatest with tests in referred patients. This likely inconstancy is the reason for using Bayess theorem to adjust the post-test probability for the pretest probability of each different setting. All measures of test performance need the first two assumptions to be fulfilled. The importance of the last four assumptions is shown in the table, although they may not be necessary in every instance; occasionally the assumptions may not be fulfilled but, because of compensating differences, transferability is still reasonable.
Target condition and reference standard The target condition and reference standard need to be carefully chosen. For example, in a study of clinically relevant tests to assess stenosis of the carotid artery, it would be sensible to dichotomise angiographic stenosis at the level of angiographic abnormality above which, on currently available evidence, the benefits of treatment outweigh harm, and to use this as the reference standard. Error in the reference standard should be minimisedfor example, by better methods or multiple assessments. Any information about the accuracy of the reference standard will help interpretation. Discriminative or predictive measures? Assessment of the discrimination of a test requires measures such as the area under the receiver operating characteristic curve or diagnostic odds ratio. However, for estimating the probability of disease in individuals, likelihood ratios (or sensitivity and specificity) are needed, with additional information on how the tests were calibrated. Studies should include information about calibration; inclusion of selected example material, such as x rays of lesions, will help to clarify what thresholds have been used. Clinical problem and population This question defines how the initial cohort should be selected for studyfor example, a new test for carotid stenosis could be considered for all patients referred to a surgical unit. However, ultrasound quantifies the extent of a stenosis reasonably accurately, so investigators may choose to restrict the study of a more expensive or invasive test to patients in whom the ultrasound result is near the decision threshold for surgery. A useful planning tool is to draw a flow diagram of how patients are selected to make up the population with the clinical problem of interest. This flow diagram shows what clinical information has been gathered, what tests have been done, and how the results of those tests determine entry into the population in which the clinical problem of interest is being studied. A good example is given in a recent paper on the assessment of imaging tests in the diagnosis of appendicitis in children.12 Replacement or incremental value of the test? A key question is whether a test is being assessed as a replacement (substitution) for an existing test (because it is better or just as good and cheaper) or whether the test adds value when used in addition to specified existing tests. This decision will also be a major determinant of how the data should be analysed.1315
BMJ VOLUME 324 16 MARCH 2002 bmj.com
Assessing transferability of discrimination and prediction
How should a study be designed to ensure that its transferability can be determined? We need first to distinguish artefactual variation from real variation in diagnostic performance. Artefactual variation arises when studies vary in the extent to which they share design features, such as whether consecutive patients were included or the reference standard and index test were read blind to each other. Once such sources of variation have been ruled out, we may explore the potential sources of true variation.9 The issues to consider are similar to those for assessing interventions. For interventions, we consider patient, intervention, comparator, and outcome (PICO).10 11 To ensure that readers have the necessary information to decide on the transferability of a diagnostic study to their own setting, five components need to be taken into account in design and presentation of a study.
670
Education and debate
Reasons for variability Between test types or readersData should be presented on the variability between different readers or types of test and on tools to help calibration, such as standard radiographs16 17 or laboratory quality control measures. The extent to which other factors, such as experience or training, affect reading adequacy is also helpful. Between subgroups of the study populationData on individuals should be available for determining the influence on test performance of the following variables: the spectrum of disease and non-disease (for example by estimating specificity within each category of non-disease); the effect of other test results, taking account of logical sequencing of tests (simplest, least invasive, cheapest are generally first); any other characteristics (for example, age and sex) that could influence test performance. Between settingsTest performance needs to be compared in several populations or centres, as has been done for the general health questionnaire18 and predictors of coma.19 Variability between settings can also be explored across different studies by using metaanalytic techniques.20 21 Studies should also explore the following sources of variability between settings that are not accounted for by the within-setting characteristics outlined in the previous section. These sources may be primary, secondary, or tertiary care; prevalence of the target condition; country or time period. Residual differences between settings should be explored to judge the extent to which there is inexplicable variability that may limit test applicability.
Competing interests: None declared.
1 2 Begg C. Biases in the assessment of diagnostic tests. Stat Med 1987;6: 411-23. Moons K, van Es GA, Deckers JW, Habbema JD, Grobbee DE. Limitations of sensitivity, specificity, likelihood ratio, and Bayes theorem in assessing diagnostic probabilities: a clinical example. Epidemiology 1997;8:12-7 Detrano R, Janosi A, Lyons KP, Marcondes G, Abbassi N, Froehlicher VF. Factors affecting sensitivity and specificity of a diagnostic test: the exercise thallium scintigram. Am J Med 1988;84:699-710. Hlatky M, Pryor DB, Harrrell FE, Califf RM, Mark DB, Rosati RA, et al. Factors affecting sensitivity and specificity of exercise electrocardiography. Am J Med 1984;77:64-71. Rozanski ADG, Berman D, Forrester JS, Morris D, Swan HJC. The declining specificity of exercise radionuclide ventriculography. N Engl J Med 1983;309:518-22. Lachs MS, Nachamkin I, Edelstein PH, Goldman J, Feinstein AR, Schwartz JS. Spectrum bias in the evaluation of diagnostic tests: lessons from the rapid dipstick test for urinary tract infection. Ann Intern Med 1992;17:135-40. Molarius ASJ, Sans S, Tuomilehto J, Kuulasmaa K. Varying sensitivity of waist action levels to identify subjects with overweight or obesity in 19 populations of the WHO MONICA Project. J Clin Epidemiol 1999;52:1213-24. Starmans R, Muris JWM, Fijten JH, Schouten HJ, Pop P, Knotterus JA. The diagnostic value of scoring models for organic and non-organic gastrointestinal disease, including the irritable-bowel syndrome. Med Decis Making 1994;14:208-16. Gatsonis C, McNeil BJ. Collaborative evaluations of diagnostic tests: experience of the Radiology Diagnostic Oncology Group. Radiology 1990;175:571-5. Sackett D, Straus S, Richardson WS, Rosenberg W, Haynes RB. Evidencebased medicine: how to practise and teach EBM. Edinburgh: Churchill Livingstone, 2000. Richardson W, Wilson MC, Nishikawa J, Hayward RS. The well-built clinical question: a key to evidence-based decisions. ACP J Club 1995; 123:A12-3. Garcia Pena BM, Mandl KD, Kraus SJ, Fischer AC, Fleisher GR, Lund DP, et al. Ultrasonography and limited computed tomography in the diagnosis and management of appendicitis in children. JAMA 1999;282:1041-6. Marshall R. The predictive value of simple rules for combining two diagnostic tests. Biometrics 1989;45:1213-22. Biggerstaff, B. Comparing diagnostic tests: a simple graphic using likelihood ratios. Stat Med 2000;19:649-63. Chock C, Irwig L, Berry G, Glasziou P. Comparing dichotomous screening tests when individuals negative on both tests are not verified. J Clin Epidemiol 1997;50:1211-7. Beam C, Layde PM, Sullivan DC. Variability in the interpretation of screening mammograms by US radiologists. Findings from a national sample. Arch Intern Med 1997;156:209-13. DOrsi C, Swets J. Variability in the interpretation of mammograms. N Engl J Med 1995;332:1172. Furukawa TGD. Cultural invariance of likelihood ratios for the general health questionnaire. Lancet 1999;353:10. Zandbergen EGJ, de Haan RJ, Stouenbeek CP, Koelman CP, Hijdra A. Systematic review of early predictors of poor outcome in anoxicischaemic coma. Lancet 1998;352:1808-12 Irwig L, Tosteson AN, Gatsonis C, Lau J, Colditz G, Chalmers TC, Mosteller F. Guidelines for meta-analyses evaluating diagnostic tests. Ann Intern Med 1994;120:667-76. Rutter C, Gatsonis C. Regression methods for meta-analysis of diagnostic test data. Acad Radiol 1995;2(suppl 1):S48-56.
10
11
12
13 14 15
Summary
There is merit in studies with heterogeneous study populations. They allow exploration of the extent to which the performance of a diagnostic test depends on prespecified predictors, and how much residual variation exists. The more variation there is in study populations, the greater the potential to know how the test will perform in various settings.
We thank Petra Macaskill, Clement Loy, Andre Knottnerus, Margaret Pepe, Jonathan Craig, and Anthony Grabs for comments on the book chapter on which this paper is based.
16
17 18 19
20
21
The Evidence Base of Clinical Diagnosis, edited by J A Knottnerus, can be purchased through the BMJ Bookshop (www. bmjbookshop.com)
A tale of two blisters
In 1924, when I was 4 years old, there was an outbreak of smallpox in Sunderland, my home town. Everyone was getting vaccinated with three inoculations of cowpox vaccine scratched into the skin over the deltoid area on the left arm. After a few days three blisters would appear, while the surrounding area became red and inflamed. To avoid pain, those who had been vaccinated wore red ribbons on their arms to prevent other people from bumping into them. As I had been vaccinated in infancy, I did not require revaccination, but my mother knew that I needed a red ribbon like everyone else so, as a wise parent, she put one on my arm. In September 1945 I was a surgeon lieutenant in the Royal Navy in Ceylon when I was sent to Sumatra with a naval landing party to Belawan Deli, the port for Medan, the principal city in the northern part of the island. We were supposed to be getting the Japanese out, but in fact we were getting the Dutch back in, being protected from the Indonesians by armed Japanese sentries. One day when I was walking down the village street I saw a woman coming towards me wearing a red sarong and a red turban. Her face and arms were covered with blisters. I immediately decided that it must be smallpox, but then I quickly thought it over and decided that if that was the diagnosis then she should be much too ill to be walking around. I was so struck by her appearance that I ran around the block, so that I could walk past her again and get another look. I still could not see whether there was umbilication of the blisters, which I had been taught was a key diagnostic distinction between chickenpox and smallpox, and I could not make a diagnosis. When I got back to naval headquarters I asked a Dutch medical officer, and he told me that it was yawsa tropical spirochaetal disease that is a probable variant of syphilis. Blisters are seldom what they seem. Skimmed milk masquerades as cream. M G Jacoby Patchogue, New York, USA
BMJ VOLUME 324
16 MARCH 2002
bmj.com
671
Das könnte Ihnen auch gefallen
- Clinical Prediction Models: A Practical Approach to Development, Validation, and UpdatingVon EverandClinical Prediction Models: A Practical Approach to Development, Validation, and UpdatingNoch keine Bewertungen
- Usmle 2ck Practice Questions All 2015Dokument6 SeitenUsmle 2ck Practice Questions All 2015Sharmela BrijmohanNoch keine Bewertungen
- Abg CasesDokument22 SeitenAbg CasesNehal ElsaidNoch keine Bewertungen
- A Clinician's Approach To Peripheral NeuropathyDokument12 SeitenA Clinician's Approach To Peripheral Neuropathytsyrahmani100% (1)
- Cerebral Vascular Diseases ExplainedDokument115 SeitenCerebral Vascular Diseases ExplainedUbaidillah Romadlon AlfairuziNoch keine Bewertungen
- MOG Antibody-Associated DiseasesDokument3 SeitenMOG Antibody-Associated DiseasesYassmin ElNazerNoch keine Bewertungen
- Antithrombotic Therapy For VTE Disease CHEST Guideline and Expert Panel ReportDokument38 SeitenAntithrombotic Therapy For VTE Disease CHEST Guideline and Expert Panel ReportAdriana VasilicaNoch keine Bewertungen
- cEEG Monitoring in The ICU: Treating Subclinical Seizures Is Cost EffectiveDokument26 SeitencEEG Monitoring in The ICU: Treating Subclinical Seizures Is Cost EffectiveVijay GadagiNoch keine Bewertungen
- ILAE Classification of Seizures and EpilepsyDokument19 SeitenILAE Classification of Seizures and EpilepsyIRENA GENI100% (1)
- Diagnostic Systematic Reviews Road Map V3Dokument2 SeitenDiagnostic Systematic Reviews Road Map V3fiseradaNoch keine Bewertungen
- Postreading Self Assessment and CME Test.25Dokument20 SeitenPostreading Self Assessment and CME Test.25مجاهد إسماعيل حسن حسينNoch keine Bewertungen
- PSQIDokument2 SeitenPSQIAdrian HartantoNoch keine Bewertungen
- Case Study For Multiple SclerosisDokument4 SeitenCase Study For Multiple SclerosisGabbii CincoNoch keine Bewertungen
- Neurology Board Review MsDokument17 SeitenNeurology Board Review MsMazin Al-TahirNoch keine Bewertungen
- Durham Maths Mysteries ( (PDF)Dokument16 SeitenDurham Maths Mysteries ( (PDF)Stephanie HillNoch keine Bewertungen
- ACNS Critical Care EEG Terminology GuideDokument50 SeitenACNS Critical Care EEG Terminology GuideNEUROMED NEURONoch keine Bewertungen
- Childhood Epilepsy Etiology, Epidemiology & ManagementDokument6 SeitenChildhood Epilepsy Etiology, Epidemiology & ManagementJosh RoshalNoch keine Bewertungen
- Anatomy Atlas Neuroanatomy Fawzy GaballahDokument228 SeitenAnatomy Atlas Neuroanatomy Fawzy GaballahNicolas OctavioNoch keine Bewertungen
- David Gozal's CVDokument87 SeitenDavid Gozal's CVMSKCNoch keine Bewertungen
- Plasma Exchange Vs IVIGDokument2 SeitenPlasma Exchange Vs IVIGclaudiaNoch keine Bewertungen
- Neurology Update 2014Dokument56 SeitenNeurology Update 2014lakshminivas PingaliNoch keine Bewertungen
- Neurology Assessment BlueprintDokument7 SeitenNeurology Assessment Blueprintidno1008Noch keine Bewertungen
- Frontal Lobe Syndromes: BackgroundDokument2 SeitenFrontal Lobe Syndromes: BackgroundFausiah Ulva MNoch keine Bewertungen
- 1536106348Dokument144 Seiten1536106348Saman SarKoNoch keine Bewertungen
- Sedatives in Neurocritical Care 2019 Curr Opin Crit CareDokument8 SeitenSedatives in Neurocritical Care 2019 Curr Opin Crit CareCAMILO ERNESTO DAZA PERDOMONoch keine Bewertungen
- B5W1L9.Peripheral Neuropathy - Lecture Notes 12Dokument4 SeitenB5W1L9.Peripheral Neuropathy - Lecture Notes 12mihalcea alinNoch keine Bewertungen
- M A N A G E M E NT OF H E A D I NJ UR Y & I NT R A CR A N I A L P RE SS UR EDokument19 SeitenM A N A G E M E NT OF H E A D I NJ UR Y & I NT R A CR A N I A L P RE SS UR EmugihartadiNoch keine Bewertungen
- Parkinson's & Movement Disorders-Harrison's NeurologyDokument23 SeitenParkinson's & Movement Disorders-Harrison's Neurologyindia2puppyNoch keine Bewertungen
- Neely2010-A Practical Guide To Understanding SystematicDokument9 SeitenNeely2010-A Practical Guide To Understanding SystematicMas NuriNoch keine Bewertungen
- 1 Stroke NeuroanatomyDokument47 Seiten1 Stroke NeuroanatomySherief MansourNoch keine Bewertungen
- SCE GeriatricsDokument434 SeitenSCE GeriatricsFaris FirasNoch keine Bewertungen
- Antithrombotic Treatment of Acute Ischemic Stroke and Transient Ischemic Attack - UpToDateDokument24 SeitenAntithrombotic Treatment of Acute Ischemic Stroke and Transient Ischemic Attack - UpToDateFerasNoch keine Bewertungen
- CVS II Tutorials Apr 12-17Dokument7 SeitenCVS II Tutorials Apr 12-17rishitNoch keine Bewertungen
- Mapping Progressive Brain Structural Changes in Early Alzheimer's DiseaseDokument27 SeitenMapping Progressive Brain Structural Changes in Early Alzheimer's Diseasetonylee24Noch keine Bewertungen
- Interpreting arterial blood gas resultsDokument38 SeitenInterpreting arterial blood gas resultsroopaNoch keine Bewertungen
- Postreading Self Assessment and CME Test Preferred.28Dokument22 SeitenPostreading Self Assessment and CME Test Preferred.28مجاهد إسماعيل حسن حسينNoch keine Bewertungen
- TestsDokument30 SeitenTestsGeletaNoch keine Bewertungen
- A Serum Autoantibody Marker of Neuromyelitis Optica: Distinction From Multiple SclerosisDokument7 SeitenA Serum Autoantibody Marker of Neuromyelitis Optica: Distinction From Multiple SclerosistiaraleshaNoch keine Bewertungen
- The New Clasification ILAE 2017Dokument6 SeitenThe New Clasification ILAE 2017Ami D ALNoch keine Bewertungen
- Lecture 19 Notes - Mucosal ImmunityDokument5 SeitenLecture 19 Notes - Mucosal ImmunityAlbert Mao LiNoch keine Bewertungen
- CH 6-2 Comparing Diagnostic TestsDokument8 SeitenCH 6-2 Comparing Diagnostic TestsJimmyNoch keine Bewertungen
- It sJustAQuizDokument24 SeitenIt sJustAQuizPrerna SehgalNoch keine Bewertungen
- Fourier Transform and Its Medical ApplicationDokument55 SeitenFourier Transform and Its Medical Applicationadriveros100% (1)
- Electrocardiographic Exercise Stress Testing PDFDokument15 SeitenElectrocardiographic Exercise Stress Testing PDFRafaelDavidVillalbaRodriguezNoch keine Bewertungen
- Neurology Lectures 1 4 DR - RosalesDokument20 SeitenNeurology Lectures 1 4 DR - RosalesMiguel Cuevas DolotNoch keine Bewertungen
- Guidelines For Sedation and Anesthesia in GI Endos PDFDokument11 SeitenGuidelines For Sedation and Anesthesia in GI Endos PDFHernan RuedaNoch keine Bewertungen
- 2002, Vol.86, Issues 3, DementiaDokument219 Seiten2002, Vol.86, Issues 3, DementiaCesar GentilleNoch keine Bewertungen
- Parkinson Disease Pharmacotherapy GuideDokument91 SeitenParkinson Disease Pharmacotherapy GuideHsn Tuyết HàNoch keine Bewertungen
- 13-Methods of RandomisationDokument4 Seiten13-Methods of Randomisationhalagur75Noch keine Bewertungen
- DR Saleh Course fainalSEPT 20Dokument103 SeitenDR Saleh Course fainalSEPT 20JehanzebNoch keine Bewertungen
- Managing Leptomeningeal MetastasesDokument5 SeitenManaging Leptomeningeal Metastasessugoiman100% (1)
- AR 2009-2010 WebDokument36 SeitenAR 2009-2010 WebOsu OphthalmologyNoch keine Bewertungen
- DD Nyeri Kepala Skenario 1Dokument8 SeitenDD Nyeri Kepala Skenario 1Ika Putri YulianiNoch keine Bewertungen
- Wacp Primary Curriculum For Psychiatry PDFDokument5 SeitenWacp Primary Curriculum For Psychiatry PDFowusuesselNoch keine Bewertungen
- 2014 RUHS Pre D.M.neurologyDokument18 Seiten2014 RUHS Pre D.M.neurologyAshok JainNoch keine Bewertungen
- A Novel Therapeutic Option for Anxiety: TofisopamDokument97 SeitenA Novel Therapeutic Option for Anxiety: TofisopamdrashishnairNoch keine Bewertungen
- DM and NeurologyDokument43 SeitenDM and NeurologySurat TanprawateNoch keine Bewertungen
- Subject:: D.M.Neurology: Ruhs Pre DM / MCH Examination 2016 Question PaperDokument17 SeitenSubject:: D.M.Neurology: Ruhs Pre DM / MCH Examination 2016 Question Paperlakshminivas PingaliNoch keine Bewertungen
- Main Stroke Protocol - Use For All Suspected Stroke-TIA PatientsDokument2 SeitenMain Stroke Protocol - Use For All Suspected Stroke-TIA PatientsRivulet1Noch keine Bewertungen
- Ultrasound Diagnosis of Fetal Macrosomia: A Comparison of Weight Prediction Models Using Computer SimulationDokument4 SeitenUltrasound Diagnosis of Fetal Macrosomia: A Comparison of Weight Prediction Models Using Computer SimulationDr_SoranusNoch keine Bewertungen
- Reducing The Risk of Pre-EclampsiaDokument14 SeitenReducing The Risk of Pre-EclampsiaDr_SoranusNoch keine Bewertungen
- Birth Weight From Pregnancies Dated by Ultrasonography in A Multicultural British PopulationDokument4 SeitenBirth Weight From Pregnancies Dated by Ultrasonography in A Multicultural British PopulationDr_SoranusNoch keine Bewertungen
- Viral Infections in PregnancyDokument38 SeitenViral Infections in PregnancyDr_Soranus100% (1)
- Post Term PregnancyDokument13 SeitenPost Term PregnancyDr_SoranusNoch keine Bewertungen
- Fundal Height ScreeningDokument10 SeitenFundal Height ScreeningDr_Soranus100% (1)
- Cord Blood Lactate and PH Values at Term and Perinatal Outcome: A Retrospective Cohort StudyDokument13 SeitenCord Blood Lactate and PH Values at Term and Perinatal Outcome: A Retrospective Cohort StudyDr_SoranusNoch keine Bewertungen
- Postpartum HemorrhageDokument53 SeitenPostpartum HemorrhageDr_Soranus100% (2)
- Diabetes in PregnancyDokument122 SeitenDiabetes in PregnancyDr_Soranus100% (1)
- Audit of Fundal Height MeasurementDokument5 SeitenAudit of Fundal Height MeasurementDr_SoranusNoch keine Bewertungen
- Max Mongelli: "Preterm Labor"Dokument62 SeitenMax Mongelli: "Preterm Labor"Dr_Soranus100% (1)
- Autoimmune Diseases in PregnancyDokument42 SeitenAutoimmune Diseases in PregnancyDr_Soranus100% (1)
- Assessment of Fetal Growth With Customised Growth ChartsDokument35 SeitenAssessment of Fetal Growth With Customised Growth ChartsDr_SoranusNoch keine Bewertungen
- The ABC of Evidence-Based MedicineDokument42 SeitenThe ABC of Evidence-Based MedicineDr_SoranusNoch keine Bewertungen
- Update On Customised Fetal Growth ChartsDokument11 SeitenUpdate On Customised Fetal Growth ChartsDr_SoranusNoch keine Bewertungen
- Max Mongelli. "Drugs in Pregnancy"Dokument47 SeitenMax Mongelli. "Drugs in Pregnancy"Dr_SoranusNoch keine Bewertungen
- An Investigation of Fetal Growth in Relation To Pregnancy CharacteristicsDokument175 SeitenAn Investigation of Fetal Growth in Relation To Pregnancy CharacteristicsDr_SoranusNoch keine Bewertungen
- BDS Exam Questions on General MedicineDokument2 SeitenBDS Exam Questions on General MedicinesoundharyaNoch keine Bewertungen
- Gestational DiabetesDokument37 SeitenGestational DiabetesSathish Kumar ANoch keine Bewertungen
- CMMNJ Report On NJ Medical Marijuana Doctor RegistryDokument5 SeitenCMMNJ Report On NJ Medical Marijuana Doctor RegistryNew Jersey marijuana documentsNoch keine Bewertungen
- Recommended Texts / Useful Resources For Psychiatry TraineesDokument5 SeitenRecommended Texts / Useful Resources For Psychiatry TraineesTemesgen EndalewNoch keine Bewertungen
- Dermatology Questions and Clinchers PDFDokument10 SeitenDermatology Questions and Clinchers PDFSahar nazNoch keine Bewertungen
- Educ1300 Career EssayDokument7 SeitenEduc1300 Career Essayapi-277390087Noch keine Bewertungen
- Hospital SafetyDokument120 SeitenHospital SafetyAndresScribd01Noch keine Bewertungen
- Mental Health and Psychosocial Problems of Medical Health Workers During The COVID-19 Epidemic in ChinaDokument9 SeitenMental Health and Psychosocial Problems of Medical Health Workers During The COVID-19 Epidemic in ChinaSubhan AnsariNoch keine Bewertungen
- The Developing Occlusion ofDokument6 SeitenThe Developing Occlusion ofAlistair KohNoch keine Bewertungen
- Cavite State University College of Nursing Drug StudyDokument2 SeitenCavite State University College of Nursing Drug StudyAfia TawiahNoch keine Bewertungen
- Cuñas MetalicasDokument8 SeitenCuñas MetalicasOciel AcostaNoch keine Bewertungen
- DS PM BBL-CHROMagar-Family-of-Products BR TRDokument12 SeitenDS PM BBL-CHROMagar-Family-of-Products BR TRlauraNoch keine Bewertungen
- Acute lung injury and ARDS in malariaDokument15 SeitenAcute lung injury and ARDS in malariaMayuresh ChaudhariNoch keine Bewertungen
- Henry C. Allen's Keynotes Rearranged and Classified Reading ExcerptDokument6 SeitenHenry C. Allen's Keynotes Rearranged and Classified Reading ExcerptChaitnya SharmaNoch keine Bewertungen
- Perkembangan Epidemiologi2Dokument64 SeitenPerkembangan Epidemiologi2Mangun AngkatNoch keine Bewertungen
- YDokument17 SeitenYaarthyNoch keine Bewertungen
- Acupressure Points For ToothacheDokument12 SeitenAcupressure Points For ToothacheshaukijameelNoch keine Bewertungen
- Drug Development EssayDokument5 SeitenDrug Development EssayDoyin AwodeleNoch keine Bewertungen
- Type 2 Diabetes Mellitus Diagnosis AdultDokument3 SeitenType 2 Diabetes Mellitus Diagnosis AdultSiti Kurniah 'nsm'Noch keine Bewertungen
- What Is Stomatitis DiseaseDokument4 SeitenWhat Is Stomatitis DiseaseRoyster CabralNoch keine Bewertungen
- Monthlyshot December 1Dokument10 SeitenMonthlyshot December 1api-308247685Noch keine Bewertungen
- Goals & Objectives for Clinical RotationDokument4 SeitenGoals & Objectives for Clinical RotationBhawna PandhuNoch keine Bewertungen
- 12th Grade Veisalgia Text - QuestionsDokument3 Seiten12th Grade Veisalgia Text - QuestionsNUJMATUL HUDA AHARUL HADAFINoch keine Bewertungen
- What Is A LobectomyDokument6 SeitenWhat Is A LobectomyMaria Carmela TormesNoch keine Bewertungen
- Vaccine Adverse Reaction Reporting System by Vaccine and MaufacturerDokument1.191 SeitenVaccine Adverse Reaction Reporting System by Vaccine and MaufacturerGuy RazerNoch keine Bewertungen
- Companion Animal Parasitology: A Clinical Perspective: Peter J. IrwinDokument13 SeitenCompanion Animal Parasitology: A Clinical Perspective: Peter J. IrwinAngela SanchezNoch keine Bewertungen
- Mandatory OvertimeDokument6 SeitenMandatory Overtimeapi-402775925Noch keine Bewertungen
- 2022 Springer Nature Fully Open Access JournalsDokument36 Seiten2022 Springer Nature Fully Open Access JournalsEntertainment HubNoch keine Bewertungen
- Nys Updated Isolation Quarantine Guidance 01042022Dokument2 SeitenNys Updated Isolation Quarantine Guidance 01042022News10NBCNoch keine Bewertungen
- Atrial Septal Defect (ASD)Dokument12 SeitenAtrial Septal Defect (ASD)anggiehardiyantiNoch keine Bewertungen