Das könnte Ihnen auch gefallen
- CK 12 Physical Science For Middle School Workbook With AnswersDokument436 SeitenCK 12 Physical Science For Middle School Workbook With Answerszendaya alisiaNoch keine Bewertungen
- 11-Successful Innovation Begins With The Business StrategyDokument17 Seiten11-Successful Innovation Begins With The Business StrategyKlly CadavidNoch keine Bewertungen
- Working ScientificallyDokument48 SeitenWorking ScientificallyMuhammad SyazwanNoch keine Bewertungen
- Difference Between Federal and Unitary Form of GovernmentDokument2 SeitenDifference Between Federal and Unitary Form of GovernmentInnocent Harry84% (31)
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsVon EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsBewertung: 5 von 5 Sternen5/5 (1)
- 8 Impact of Training and Development On Organizational PerformanceDokument7 Seiten8 Impact of Training and Development On Organizational PerformanceHelen GabrielNoch keine Bewertungen
- Socpsych Reviewer!!!!!Dokument23 SeitenSocpsych Reviewer!!!!!Megan BiagNoch keine Bewertungen
- (Riccardo Viale, Fondazione Rosselli) The Capitali (B-Ok - CC) PDFDokument364 Seiten(Riccardo Viale, Fondazione Rosselli) The Capitali (B-Ok - CC) PDFmarceloamaralNoch keine Bewertungen
- Analysis of VarianceDokument51 SeitenAnalysis of Varianceapi-19916399Noch keine Bewertungen
- Small Sample TestsDokument10 SeitenSmall Sample TestsJohn CarterNoch keine Bewertungen
- 5.2. Hypothesis Tests and Confidence Intervals One Sample Z-Test and Confidence IntervalDokument6 Seiten5.2. Hypothesis Tests and Confidence Intervals One Sample Z-Test and Confidence IntervalrpinheirNoch keine Bewertungen
- HW 03 SolDokument9 SeitenHW 03 SolfdfNoch keine Bewertungen
- Unit Ii (Formula Sheet) 10.1 Difference Between Two Population Means: σ and σ Known Interval Estimation of µ and µDokument10 SeitenUnit Ii (Formula Sheet) 10.1 Difference Between Two Population Means: σ and σ Known Interval Estimation of µ and µChris Nwoke Jr.Noch keine Bewertungen
- Numerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveDokument44 SeitenNumerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel Raveanirbanpwd76Noch keine Bewertungen
- Comparing Two GroupsDokument25 SeitenComparing Two GroupsJosh PotashNoch keine Bewertungen
- EstimationDokument12 SeitenEstimationwe_spidus_2006Noch keine Bewertungen
- Numerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveDokument44 SeitenNumerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveSanjeev DwivediNoch keine Bewertungen
- Stat171 NotesDokument82 SeitenStat171 NotesnigerianhacksNoch keine Bewertungen
- Mathematical Foundations of Computer ScienceDokument24 SeitenMathematical Foundations of Computer Sciencemurugesh72Noch keine Bewertungen
- Notes On Anova: Dr. Mcintyre Mcdaniel College Revised: August 2005Dokument10 SeitenNotes On Anova: Dr. Mcintyre Mcdaniel College Revised: August 2005Usha Janardan MishraNoch keine Bewertungen
- Chapter 9Dokument8 SeitenChapter 9sezarozoldekNoch keine Bewertungen
- Basic Statistical ConceptsDokument14 SeitenBasic Statistical ConceptsVedha ThangavelNoch keine Bewertungen
- Hogg McKean Craig 4 2Dokument9 SeitenHogg McKean Craig 4 2Parth JoshiNoch keine Bewertungen
- 5 BMDokument20 Seiten5 BMNaailah نائلة MaudarunNoch keine Bewertungen
- KWT 5.ukuran Keragaman DataDokument27 SeitenKWT 5.ukuran Keragaman DataagroekotekNoch keine Bewertungen
- Chapter10 StatsDokument7 SeitenChapter10 StatsPoonam NaiduNoch keine Bewertungen
- Statistics ReviewDokument16 SeitenStatistics ReviewAlan BatschauerNoch keine Bewertungen
- Confidence Intervals with σ unknownDokument9 SeitenConfidence Intervals with σ unknownMara DepaurNoch keine Bewertungen
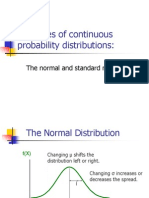
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDokument57 SeitenExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalNoch keine Bewertungen
- A (Very) Brief Review of Statistical Inference: 1 Some PreliminariesDokument9 SeitenA (Very) Brief Review of Statistical Inference: 1 Some PreliminarieswhatisnameNoch keine Bewertungen
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDokument57 SeitenExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNoch keine Bewertungen
- Introduction To One-Way Analysis of Variance: Review of The T-Test For Independent GroupsDokument6 SeitenIntroduction To One-Way Analysis of Variance: Review of The T-Test For Independent GroupsPhong Nguyễn ChâuNoch keine Bewertungen
- 5 DispersionDokument33 Seiten5 DispersionZunaeid Mahmud LamNoch keine Bewertungen
- Handout: Two Sample Hypothesis Testing and Inference ForDokument5 SeitenHandout: Two Sample Hypothesis Testing and Inference Forsumanta1234Noch keine Bewertungen
- Measures of Dispersion - 1Dokument44 SeitenMeasures of Dispersion - 1muhardi jayaNoch keine Bewertungen
- Eigenvectors and Eigenvalues of Stationary Processes: N N JK J KDokument8 SeitenEigenvectors and Eigenvalues of Stationary Processes: N N JK J KRomualdo Begale PrudêncioNoch keine Bewertungen
- Two Populations PDFDokument16 SeitenTwo Populations PDFdarwin_huaNoch keine Bewertungen
- Probability and StatisticsDokument14 SeitenProbability and StatisticsAshok ThiruvengadamNoch keine Bewertungen
- Lecture No.10Dokument8 SeitenLecture No.10Awais RaoNoch keine Bewertungen
- Statistics Study Guide: Matthew Chesnes The London School of Economics September 22, 2001Dokument22 SeitenStatistics Study Guide: Matthew Chesnes The London School of Economics September 22, 2001kjneroNoch keine Bewertungen
- STAT2602B Topic 4 With Exercise Suggested SolutionDokument12 SeitenSTAT2602B Topic 4 With Exercise Suggested SolutiongiaoxukunNoch keine Bewertungen
- I. Test of a Mean: σ unknown: X Z n Z N X t s n ttnDokument12 SeitenI. Test of a Mean: σ unknown: X Z n Z N X t s n ttnAli Arsalan SyedNoch keine Bewertungen
- Tutorial 7 So LNDokument10 SeitenTutorial 7 So LNBobNoch keine Bewertungen
- Student's T Distribution - Supplement To Chap-Ter 3Dokument3 SeitenStudent's T Distribution - Supplement To Chap-Ter 3AYU JANNATULNoch keine Bewertungen
- Pro Band StatDokument27 SeitenPro Band StatSunu PradanaNoch keine Bewertungen
- Tutorial 6 So LNDokument12 SeitenTutorial 6 So LNBobNoch keine Bewertungen
- Confidence Intervals: Guy Lebanon February 23, 2006Dokument3 SeitenConfidence Intervals: Guy Lebanon February 23, 2006william waltersNoch keine Bewertungen
- Contol of QuairyststaeDokument2 SeitenContol of Quairyststaeaskazy007Noch keine Bewertungen
- Sample Size and Power Calculations Using The Noncentral T-DistributionDokument12 SeitenSample Size and Power Calculations Using The Noncentral T-Distributionwulandari_rNoch keine Bewertungen
- Lectuer 21-ConfidenceIntervalDokument41 SeitenLectuer 21-ConfidenceIntervalArslan ArshadNoch keine Bewertungen
- Solutions To Quiz 5: Single Variable Calculus, Jan - Apr 2013Dokument6 SeitenSolutions To Quiz 5: Single Variable Calculus, Jan - Apr 2013Sefa Anıl SezerNoch keine Bewertungen
- AnovaDokument105 SeitenAnovaasdasdas asdasdasdsadsasddssaNoch keine Bewertungen
- Chapter 8Dokument7 SeitenChapter 8sezarozoldekNoch keine Bewertungen
- ST102 NotesDokument21 SeitenST102 NotesBenjamin Ng0% (1)
- Statistic and ProbabilityDokument15 SeitenStatistic and ProbabilityFerly TaburadaNoch keine Bewertungen
- Lecture 9.0 - StatisticsDokument39 SeitenLecture 9.0 - StatisticsMohanad SulimanNoch keine Bewertungen
- Durbin LevinsonDokument7 SeitenDurbin LevinsonNguyễn Thành AnNoch keine Bewertungen
- Confidence Interval For The Difference of MeansDokument9 SeitenConfidence Interval For The Difference of MeansAmarnathMaitiNoch keine Bewertungen
- Osobine VarDokument19 SeitenOsobine Varenes_osmić_1Noch keine Bewertungen
- Hypothesis TestDokument19 SeitenHypothesis TestmalindaNoch keine Bewertungen
- Central Limit TheoremDokument3 SeitenCentral Limit TheoremMicky MickckyNoch keine Bewertungen
- Chapter 4Dokument46 SeitenChapter 4Javeria NaseemNoch keine Bewertungen
- Haan C T Statistical Methods in Hydrology SolutionDokument17 SeitenHaan C T Statistical Methods in Hydrology Solutiongizem duralNoch keine Bewertungen
- LR 1 Error AnalysisDokument17 SeitenLR 1 Error AnalysisMuhammad MursaleenNoch keine Bewertungen
- Full Name of submitter: Cao Thị Minh Anh Student ID: IELSIU18002Dokument7 SeitenFull Name of submitter: Cao Thị Minh Anh Student ID: IELSIU18002ManhNoch keine Bewertungen
- Lecture 11Dokument4 SeitenLecture 11armailgmNoch keine Bewertungen
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Von EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Noch keine Bewertungen
- Mobilink, Pakistan - FullDokument23 SeitenMobilink, Pakistan - FullInnocent HarryNoch keine Bewertungen
- Barriers To CommunicationDokument4 SeitenBarriers To CommunicationInnocent Harry100% (1)
- Breaking The Glass CeilingDokument8 SeitenBreaking The Glass CeilingInnocent HarryNoch keine Bewertungen
- KFC ReporrtDokument6 SeitenKFC ReporrtInnocent HarryNoch keine Bewertungen
- Fiscal PolicyDokument4 SeitenFiscal PolicyInnocent HarryNoch keine Bewertungen
- PR2 Q2 Week 34 Learning MaterialsDokument10 SeitenPR2 Q2 Week 34 Learning MaterialsHallares, Maxine Kate F.Noch keine Bewertungen
- Worksheet N0. 5.1 B Test On One Sample MeanDokument14 SeitenWorksheet N0. 5.1 B Test On One Sample MeanMarleen Aguinaldo BalimbinNoch keine Bewertungen
- WLP StatDokument2 SeitenWLP StatCHARLENE SAGUINHONNoch keine Bewertungen
- Syllabus - VTU - MBA - Research Methodology and Strategic Management PDFDokument2 SeitenSyllabus - VTU - MBA - Research Methodology and Strategic Management PDFPreethi Gopalan100% (1)
- Assignment 1 - PM299 - 1 2nd Sem SY 2022-2023 - Sabidra - de GuzmanDokument13 SeitenAssignment 1 - PM299 - 1 2nd Sem SY 2022-2023 - Sabidra - de GuzmanRachel SabidraNoch keine Bewertungen
- IA-2A-Scientific Method (DONE)Dokument3 SeitenIA-2A-Scientific Method (DONE)Pearl AgcopraNoch keine Bewertungen
- Methods of Teaching MathematicsDokument13 SeitenMethods of Teaching MathematicsSadiq Merchant94% (53)
- Experimental Psychology Flexys Syllabus 2021Dokument8 SeitenExperimental Psychology Flexys Syllabus 2021Lovely MelgarNoch keine Bewertungen
- Adigrat University College of Engineering and Technology Department of Electrical and Computer EngineeringDokument32 SeitenAdigrat University College of Engineering and Technology Department of Electrical and Computer EngineeringBelayneh TadesseNoch keine Bewertungen
- First WeekDokument80 SeitenFirst WeekZian Lantiz SorianoNoch keine Bewertungen
- Advance Business Research MethodsDokument22 SeitenAdvance Business Research MethodsMichael Tesfaye100% (1)
- Section 1.3 HW KeyDokument4 SeitenSection 1.3 HW KeyCatie Wooten100% (1)
- Saebi, T., Lien, L., - Foss, N. J. (2017) - What Drives Business Model AdaptationDokument33 SeitenSaebi, T., Lien, L., - Foss, N. J. (2017) - What Drives Business Model AdaptationDaan SpijkerNoch keine Bewertungen
- August 29-30Dokument4 SeitenAugust 29-30Lorie Ann RatunilNoch keine Bewertungen
- ESST3103 Lab3Dokument7 SeitenESST3103 Lab3Manda BaboolalNoch keine Bewertungen
- Statistical Analysis of Cross-Tabs: Descriptive Statistics Includes Collecting, Organizing, Summarizing and PresentingDokument38 SeitenStatistical Analysis of Cross-Tabs: Descriptive Statistics Includes Collecting, Organizing, Summarizing and PresentingPrabeesh P PrasanthiNoch keine Bewertungen
- Criminalistics, Eteeap BeneficiaryDokument10 SeitenCriminalistics, Eteeap BeneficiaryJonas Valerio100% (1)
- Thesis 2Dokument37 SeitenThesis 2Eljaay QuintansNoch keine Bewertungen
- William Labov and The Social Stratification of RDokument3 SeitenWilliam Labov and The Social Stratification of RSamaraNoch keine Bewertungen
- Research Group 5Dokument27 SeitenResearch Group 5edessaNoch keine Bewertungen
- Summative-7th Grade Science 2013 1Dokument3 SeitenSummative-7th Grade Science 2013 1api-208328357100% (1)
- Research Aptitude by Talvir PDFDokument27 SeitenResearch Aptitude by Talvir PDFPranit Satyavan Naik50% (2)
- 07 - Chapter 1 PDFDokument52 Seiten07 - Chapter 1 PDFmarta soaneNoch keine Bewertungen
- FullDokument395 SeitenFullIkee NgNoch keine Bewertungen