Das könnte Ihnen auch gefallen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Week 3 HWDokument3 SeitenWeek 3 HWMoazh TawabNoch keine Bewertungen
- Lect 4 Pspice Tutorial - 2Dokument52 SeitenLect 4 Pspice Tutorial - 2Moazh TawabNoch keine Bewertungen
- 1.1 Background: Sparse Signal Processing For Undersea Acoustic LinksDokument20 Seiten1.1 Background: Sparse Signal Processing For Undersea Acoustic LinksMoazh TawabNoch keine Bewertungen
- Emulation Fundamentals For TI's DSP SolutionsDokument28 SeitenEmulation Fundamentals For TI's DSP SolutionsMoazh TawabNoch keine Bewertungen
- 0 2 Contiki TutorialDokument33 Seiten0 2 Contiki TutorialMoazh TawabNoch keine Bewertungen
- DatasheetDokument62 SeitenDatasheetMoazh TawabNoch keine Bewertungen
- ELK 1206 108 Manuscript 2Dokument18 SeitenELK 1206 108 Manuscript 2Moazh TawabNoch keine Bewertungen
- Elhabyan Riham 2015 ThesisDokument169 SeitenElhabyan Riham 2015 ThesisMoazh TawabNoch keine Bewertungen
- Data SheetDokument7 SeitenData SheetMoazh TawabNoch keine Bewertungen
- Capacity of Wireless ChannelsDokument30 SeitenCapacity of Wireless ChannelsMoazh TawabNoch keine Bewertungen
- A Novel MAI Reduction Method Using Longer M Sequences For Multiuser Detection in DS/CDMA Communication SystemsDokument9 SeitenA Novel MAI Reduction Method Using Longer M Sequences For Multiuser Detection in DS/CDMA Communication SystemsMoazh TawabNoch keine Bewertungen
- VHDL Test Bench For Digital Image Processing SystemsDokument10 SeitenVHDL Test Bench For Digital Image Processing SystemsMoazh TawabNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Forced Convection Lab Report PDFDokument6 SeitenForced Convection Lab Report PDFAshtiGosineNoch keine Bewertungen
- Stochastic Hydrology PDFDokument187 SeitenStochastic Hydrology PDFsatyam mehtaNoch keine Bewertungen
- Understanding Fixed Limit GagesDokument17 SeitenUnderstanding Fixed Limit Gagesİlhan Burak ÖzhanNoch keine Bewertungen
- Assignment 1Dokument1 SeiteAssignment 1Shubham VermaNoch keine Bewertungen
- Calibration: Constructing A Calibration CurveDokument10 SeitenCalibration: Constructing A Calibration Curvedéborah_rosalesNoch keine Bewertungen
- Combining Error Ellipses: John E. DavisDokument17 SeitenCombining Error Ellipses: John E. DavisAzem GanuNoch keine Bewertungen
- Gumble Distribution TheoryDokument3 SeitenGumble Distribution TheorySalman ShujaNoch keine Bewertungen
- Handlg Data Ch3Dokument0 SeitenHandlg Data Ch3Singh SudipNoch keine Bewertungen
- Chem 107 Test 1 ReviewDokument4 SeitenChem 107 Test 1 ReviewSteven WalkerNoch keine Bewertungen
- Machine Learning Methods To Weather Forecasting To Predict Apparent Temperature A ReviewDokument6 SeitenMachine Learning Methods To Weather Forecasting To Predict Apparent Temperature A ReviewIJRASETPublications100% (1)
- 05 - Demand Estimation and ForecastingDokument52 Seiten05 - Demand Estimation and ForecastingRistianiAniNoch keine Bewertungen
- Problem Set Heat Transfer 2Dokument2 SeitenProblem Set Heat Transfer 2John Raymart RaferNoch keine Bewertungen
- Humidity Control in The Laboratory Using Salt Solutions-A ReviewDokument5 SeitenHumidity Control in The Laboratory Using Salt Solutions-A ReviewLê Ngọc-Hà100% (1)
- Modelling and Stressing The Interest Rates Swap Curve: September 2013Dokument19 SeitenModelling and Stressing The Interest Rates Swap Curve: September 2013Krishnan ChariNoch keine Bewertungen
- MarkovDokument34 SeitenMarkovAswathy CjNoch keine Bewertungen
- Kimpton Hotels Case: Sumit Kunnumkal Indian School of BusinessDokument12 SeitenKimpton Hotels Case: Sumit Kunnumkal Indian School of BusinesshiteshsachaniNoch keine Bewertungen
- Project - Exp Growth and DecayDokument5 SeitenProject - Exp Growth and Decayapi-261139685Noch keine Bewertungen
- Astm D-4052Dokument8 SeitenAstm D-4052Nacho Ambrosis100% (2)
- (Ferraz Et Al 2020) EquacoesinglsDokument12 Seiten(Ferraz Et Al 2020) EquacoesinglsLorena SouzaNoch keine Bewertungen
- Pre AssessmentDokument16 SeitenPre Assessmentaboulazhar50% (2)
- Chatterjee & HadiDokument30 SeitenChatterjee & HadiGaurav AtreyaNoch keine Bewertungen
- 2) Performance Analysis IMPORTANTDokument4 Seiten2) Performance Analysis IMPORTANTDogNoch keine Bewertungen
- Fx-3650P User ManualDokument61 SeitenFx-3650P User ManualWho Am INoch keine Bewertungen
- Miller - Haden - 2013 - GLM Statistical Analysis PDFDokument274 SeitenMiller - Haden - 2013 - GLM Statistical Analysis PDFRodrigo AlvesNoch keine Bewertungen
- Demand Estimation and ForecastingDokument56 SeitenDemand Estimation and ForecastingAsnake GeremewNoch keine Bewertungen
- Seasons of Change Activity WorksheetDokument2 SeitenSeasons of Change Activity WorksheetJNitti Vlogs20% (30)
- Assignment 4 (2) - Engineering Statistics PDFDokument4 SeitenAssignment 4 (2) - Engineering Statistics PDFNamra FatimaNoch keine Bewertungen
- A Cointegation Demo Fetrics Chp4Dokument58 SeitenA Cointegation Demo Fetrics Chp4aptenodyteNoch keine Bewertungen
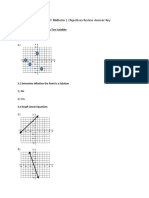
- Math 0980 Midterm 2 Objectives Review Answer Key-6Dokument6 SeitenMath 0980 Midterm 2 Objectives Review Answer Key-6LarryhNoch keine Bewertungen
- Keywords:-CHIRPS Dataset Rainfall Analysis SeasonalDokument13 SeitenKeywords:-CHIRPS Dataset Rainfall Analysis SeasonalInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen