Das könnte Ihnen auch gefallen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Iot Based Garbage and Street Light Monitoring SystemDokument3 SeitenIot Based Garbage and Street Light Monitoring SystemHarini VenkatNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
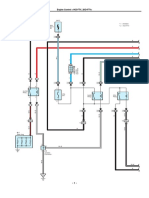
- Diagrama Hilux 1KD-2KD PDFDokument11 SeitenDiagrama Hilux 1KD-2KD PDFJeni100% (1)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Michael Ungar - Working With Children and Youth With Complex Needs - 20 Skills To Build Resilience-Routledge (2014)Dokument222 SeitenMichael Ungar - Working With Children and Youth With Complex Needs - 20 Skills To Build Resilience-Routledge (2014)Sølve StoknesNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Gol GumbazDokument6 SeitenGol Gumbazmnv_iitbNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- New Cisco Certification Path (From Feb2020) PDFDokument1 SeiteNew Cisco Certification Path (From Feb2020) PDFkingNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Nielsen Report - The New Trend Among Indonesia's NetizensDokument20 SeitenNielsen Report - The New Trend Among Indonesia's NetizensMarsha ImaniaraNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Synthesis Essay Final DraftDokument5 SeitenSynthesis Essay Final Draftapi-283802944Noch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Age and Gender Detection Using Deep Learning: HYDERABAD - 501 510Dokument11 SeitenAge and Gender Detection Using Deep Learning: HYDERABAD - 501 510ShyamkumarBannuNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Historical Roots of The "Whitening" of BrazilDokument23 SeitenHistorical Roots of The "Whitening" of BrazilFernandoMascarenhasNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Leadership Nursing and Patient SafetyDokument172 SeitenLeadership Nursing and Patient SafetyRolena Johnette B. PiñeroNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Highway Journal Feb 2023Dokument52 SeitenHighway Journal Feb 2023ShaileshRastogiNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- " Suratgarh Super Thermal Power Station": Submitted ToDokument58 Seiten" Suratgarh Super Thermal Power Station": Submitted ToSahuManishNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- (Database Management Systems) : Biag, Marvin, B. BSIT - 202 September 6 2019Dokument7 Seiten(Database Management Systems) : Biag, Marvin, B. BSIT - 202 September 6 2019Marcos JeremyNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Read The Dialogue Below and Answer The Following QuestionDokument5 SeitenRead The Dialogue Below and Answer The Following QuestionDavid GainesNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Citing Correctly and Avoiding Plagiarism: MLA Format, 7th EditionDokument4 SeitenCiting Correctly and Avoiding Plagiarism: MLA Format, 7th EditionDanish muinNoch keine Bewertungen
- 10 - SHM, Springs, DampingDokument4 Seiten10 - SHM, Springs, DampingBradley NartowtNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Technical Textile and SustainabilityDokument5 SeitenTechnical Textile and SustainabilityNaimul HasanNoch keine Bewertungen
- Day 2 - Evident's Official ComplaintDokument18 SeitenDay 2 - Evident's Official ComplaintChronicle Herald100% (1)
- Assignment 1 - Vertical Alignment - SolutionsDokument6 SeitenAssignment 1 - Vertical Alignment - SolutionsArmando Ramirez100% (1)
- CV TitchievDokument3 SeitenCV TitchievIna FarcosNoch keine Bewertungen
- WT&D (Optimization of WDS) PDFDokument89 SeitenWT&D (Optimization of WDS) PDFAbirham TilahunNoch keine Bewertungen
- Datasheet 6A8 FusívelDokument3 SeitenDatasheet 6A8 FusívelMluz LuzNoch keine Bewertungen
- Ce Project 1Dokument7 SeitenCe Project 1emmaNoch keine Bewertungen
- Directorate of Technical Education, Maharashtra State, MumbaiDokument57 SeitenDirectorate of Technical Education, Maharashtra State, MumbaiShubham DahatondeNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- ESA Mars Research Abstracts Part 2Dokument85 SeitenESA Mars Research Abstracts Part 2daver2tarletonNoch keine Bewertungen
- Feb-May SBI StatementDokument2 SeitenFeb-May SBI StatementAshutosh PandeyNoch keine Bewertungen
- Nptel Online-Iit KanpurDokument1 SeiteNptel Online-Iit KanpurRihlesh ParlNoch keine Bewertungen
- Topfast BRAND Catalogue Ingco 2021 MayDokument116 SeitenTopfast BRAND Catalogue Ingco 2021 MayMoh AwadNoch keine Bewertungen
- SUNGLAO - TM PortfolioDokument60 SeitenSUNGLAO - TM PortfolioGIZELLE SUNGLAONoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Parts List 38 254 13 95: Helical-Bevel Gear Unit KA47, KH47, KV47, KT47, KA47B, KH47B, KV47BDokument4 SeitenParts List 38 254 13 95: Helical-Bevel Gear Unit KA47, KH47, KV47, KT47, KA47B, KH47B, KV47BEdmundo JavierNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)