Das könnte Ihnen auch gefallen
- CBT 2020 PremDokument33 SeitenCBT 2020 Premபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- General Surgical InstrumentsDokument96 SeitenGeneral Surgical Instrumentsviki28mb90% (29)
- 01-Sdh DH Iphs Guidelines-2022Dokument244 Seiten01-Sdh DH Iphs Guidelines-2022பிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Family Health Optima - Zone - 1Dokument4 SeitenFamily Health Optima - Zone - 1பிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Immunofree 1 PDFDokument40 SeitenImmunofree 1 PDFபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Anatomy and Physiology Nursing Mnemonics & TipsDokument8 SeitenAnatomy and Physiology Nursing Mnemonics & Tipsபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- 160 Nursing Bullets - Medical-Surgical Nursing ReviewerDokument12 Seiten160 Nursing Bullets - Medical-Surgical Nursing Reviewerபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Cohort StudyDokument40 SeitenCohort Studyபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- 225 Nursing Bullets - Psychiatric Nursing ReviewerDokument17 Seiten225 Nursing Bullets - Psychiatric Nursing Reviewerபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
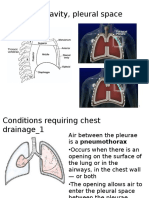
- Thoracic Cavity, Pleural SpaceDokument28 SeitenThoracic Cavity, Pleural Spaceபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- AddendumRecruitment ABC 2015Dokument1 SeiteAddendumRecruitment ABC 2015பிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Assessment Critera Template - Diabetes EducatorDokument4 SeitenAssessment Critera Template - Diabetes Educatorபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- IV Fluids and Solutions Quick Reference Guide Cheat Sheet - NurseslabsDokument7 SeitenIV Fluids and Solutions Quick Reference Guide Cheat Sheet - Nurseslabsபிரேம் குமார் ராஜாமணி100% (1)
- 8-Step Guide To ABG Analysis - Tic-Tac-Toe Method - NurseslabsDokument10 Seiten8-Step Guide To ABG Analysis - Tic-Tac-Toe Method - Nurseslabsபிரேம் குமார் ராஜாமணி100% (2)
- Assessment Frame Work - GDADokument8 SeitenAssessment Frame Work - GDAபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- PrintDokument3 SeitenPrintபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Nurses: A Force For ChangeDokument62 SeitenNurses: A Force For Changeபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- King George's Medical University, Chowk, Lucknow U.PDokument4 SeitenKing George's Medical University, Chowk, Lucknow U.Pபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Oxygenation and Orygen TherapyDokument87 SeitenOxygenation and Orygen Therapyபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Healthy AgingDokument14 SeitenHealthy Agingபிரேம் குமார் ராஜாமணிNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Daily Lesson Plan Form 3 Jun 2017Dokument9 SeitenDaily Lesson Plan Form 3 Jun 2017Hajar Binti Md SaidNoch keine Bewertungen
- 02 Gill & Johnson CH 02Dokument17 Seiten02 Gill & Johnson CH 02DrShabbir KhanNoch keine Bewertungen
- Concept of Information - Rafael CapurroDokument17 SeitenConcept of Information - Rafael CapurroFau NesNoch keine Bewertungen
- STS MRR1Dokument1 SeiteSTS MRR1Shailani HossainNoch keine Bewertungen
- Human Perception: A Comparative Study of How Others Perceive Me and How I Perceive MyselfDokument25 SeitenHuman Perception: A Comparative Study of How Others Perceive Me and How I Perceive MyselfKimber Crizel PinedaNoch keine Bewertungen
- Cambridge English Starters TESTDokument5 SeitenCambridge English Starters TESTmiren48Noch keine Bewertungen
- Key Concepts of Active ListeningDokument6 SeitenKey Concepts of Active ListeningJiří DohnalNoch keine Bewertungen
- Self Efficacy (What It Is and Why It Matters)Dokument3 SeitenSelf Efficacy (What It Is and Why It Matters)ABDUL RAUFNoch keine Bewertungen
- Third Quarter ExamDokument4 SeitenThird Quarter ExamTRISTANE ERIC SUMANDE100% (1)
- Rorty, R. - Recent Metaphilosophy (1961)Dokument21 SeitenRorty, R. - Recent Metaphilosophy (1961)Fer VasNoch keine Bewertungen
- Annotated BibliographyDokument11 SeitenAnnotated Bibliographyapi-450385337Noch keine Bewertungen
- Writing in Math ClassDokument33 SeitenWriting in Math Classapi-135744337Noch keine Bewertungen
- Journal 2 PDFDokument14 SeitenJournal 2 PDFJayNoch keine Bewertungen
- Curriculum DesignDokument32 SeitenCurriculum DesignLorena Cabradilla0% (1)
- Han & Lerner 2009 Decision Making (ENTRY)Dokument12 SeitenHan & Lerner 2009 Decision Making (ENTRY)hoorieNoch keine Bewertungen
- Do Critics Misrepresent My PositionDokument37 SeitenDo Critics Misrepresent My PositionPablo Alberto Herrera SalinasNoch keine Bewertungen
- Spinoza's Joyful Republic. On The Power of Passions, Politics, and Knowledge - H. SharpDokument309 SeitenSpinoza's Joyful Republic. On The Power of Passions, Politics, and Knowledge - H. SharpCamila CabralNoch keine Bewertungen
- NCSSM Diagnostic RubricDokument2 SeitenNCSSM Diagnostic RubricCharles ZhaoNoch keine Bewertungen
- Survey Larong PinoyDokument5 SeitenSurvey Larong PinoyLenny100% (1)
- Intro To Science Notes Including Scientific MethodDokument33 SeitenIntro To Science Notes Including Scientific Methodapi-236331206Noch keine Bewertungen
- Course Syllabus GE Cluster 21A Fall 15Dokument7 SeitenCourse Syllabus GE Cluster 21A Fall 15Crystal EshraghiNoch keine Bewertungen
- Kenn Henri C. Villegas September 9, 2013Dokument4 SeitenKenn Henri C. Villegas September 9, 2013Anonymous tJuT36L7oNoch keine Bewertungen
- Western Concepts of SelfDokument11 SeitenWestern Concepts of SelfReyalyn AntonioNoch keine Bewertungen
- Theory of PerceptionDokument2 SeitenTheory of Perceptioncalypso greyNoch keine Bewertungen
- 1 - Abdallah-Pretceille, M. (2006) Interculturalism As A Paradigm For Thinking About Diversity - Intercultural Education, 17 - 5 P. 475 - 483Dokument10 Seiten1 - Abdallah-Pretceille, M. (2006) Interculturalism As A Paradigm For Thinking About Diversity - Intercultural Education, 17 - 5 P. 475 - 483NNoch keine Bewertungen
- Learning Experiences For Literacy LearnersDokument13 SeitenLearning Experiences For Literacy LearnersKristian Kenneth Angelo ReandinoNoch keine Bewertungen
- What Is Post ModernismDokument3 SeitenWhat Is Post ModernismMichael RaucciNoch keine Bewertungen
- Removing Empathy From SoldiersDokument3 SeitenRemoving Empathy From SoldiersAurel NaomiNoch keine Bewertungen
- Touching Spirit Bear Lesson 2 Week 3Dokument3 SeitenTouching Spirit Bear Lesson 2 Week 3api-288089824Noch keine Bewertungen
- 3 Ways To Stop Overthinking ImmediatelyDokument11 Seiten3 Ways To Stop Overthinking ImmediatelyCarolina Parra0% (1)