Das könnte Ihnen auch gefallen
- Andrew Rosenberg - Lecture 22: EvaluationDokument32 SeitenAndrew Rosenberg - Lecture 22: EvaluationRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 10: Junction Tree Algorithm CSCI 780 - Machine LearningDokument38 SeitenAndrew Rosenberg - Lecture 10: Junction Tree Algorithm CSCI 780 - Machine LearningRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 2.1: Vector Calculus CSC 84020 - Machine LearningDokument46 SeitenAndrew Rosenberg - Lecture 2.1: Vector Calculus CSC 84020 - Machine LearningRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 23: Clustering EvaluationDokument24 SeitenAndrew Rosenberg - Lecture 23: Clustering EvaluationRoots999Noch keine Bewertungen
- Perceptron Learning ProcedureDokument1 SeitePerceptron Learning ProcedureRoots999Noch keine Bewertungen
- Andrew Rosenberg - Support Vector Machines (And Kernel Methods in General)Dokument45 SeitenAndrew Rosenberg - Support Vector Machines (And Kernel Methods in General)Roots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 1.2: Probability and Statistics CSC 84020 - Machine LearningDokument48 SeitenAndrew Rosenberg - Lecture 1.2: Probability and Statistics CSC 84020 - Machine LearningRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 21: Spectral ClusteringDokument43 SeitenAndrew Rosenberg - Lecture 21: Spectral ClusteringRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 20: Model AdaptationDokument35 SeitenAndrew Rosenberg - Lecture 20: Model AdaptationRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 14: Neural NetworksDokument50 SeitenAndrew Rosenberg - Lecture 14: Neural NetworksRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 18: Gaussian Mixture Models and Expectation MaximizationDokument34 SeitenAndrew Rosenberg - Lecture 18: Gaussian Mixture Models and Expectation MaximizationRoots999Noch keine Bewertungen
- Adaline (Adaptive Linear Neural) Learning ProcedureDokument3 SeitenAdaline (Adaptive Linear Neural) Learning ProcedureRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 19: More EMDokument34 SeitenAndrew Rosenberg - Lecture 19: More EMRoots999Noch keine Bewertungen
- Andrew Rosenberg - Support Vector Machines and Kernel MethodsDokument39 SeitenAndrew Rosenberg - Support Vector Machines and Kernel MethodsRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 12: Hidden Markov Models Machine LearningDokument34 SeitenAndrew Rosenberg - Lecture 12: Hidden Markov Models Machine LearningRoots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 11: Clustering Introduction and Projects Machine LearningDokument65 SeitenAndrew Rosenberg - Lecture 11: Clustering Introduction and Projects Machine LearningRoots999Noch keine Bewertungen
- Liang Tian - Learning From Data Through Support Vector MachinesDokument50 SeitenLiang Tian - Learning From Data Through Support Vector MachinesRoots999Noch keine Bewertungen
- Unsupervised Learning: Part III Counter Propagation NetworkDokument17 SeitenUnsupervised Learning: Part III Counter Propagation NetworkRoots999100% (1)
- Unsupervised Learning 1Dokument31 SeitenUnsupervised Learning 1Roots999Noch keine Bewertungen
- Pattern Association 1Dokument35 SeitenPattern Association 1Roots999Noch keine Bewertungen
- Andrew Rosenberg - Lecture 1.1: Introduction CSC 84020 - Machine LearningDokument33 SeitenAndrew Rosenberg - Lecture 1.1: Introduction CSC 84020 - Machine LearningRoots999Noch keine Bewertungen
- Unsupervised Learning: Part II Self-Organizing MapsDokument36 SeitenUnsupervised Learning: Part II Self-Organizing MapsRoots999Noch keine Bewertungen
- Hopfield: An ExampleDokument27 SeitenHopfield: An ExampleRoots999Noch keine Bewertungen
- Pattern AssociationDokument36 SeitenPattern AssociationRoots999Noch keine Bewertungen
- Artificial Neural NetworkDokument31 SeitenArtificial Neural NetworkRoots999Noch keine Bewertungen
- Extended Back PropagationDokument11 SeitenExtended Back PropagationRoots999Noch keine Bewertungen
- Biological Neural SystemsDokument20 SeitenBiological Neural SystemsRoots999Noch keine Bewertungen
- Back Propagation: VariationsDokument21 SeitenBack Propagation: VariationsRoots999Noch keine Bewertungen
- Back-Propagation Learning ProcedureDokument2 SeitenBack-Propagation Learning ProcedureRoots999Noch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Digital Signature ProjectDokument87 SeitenDigital Signature ProjectSuresh Neharkar100% (1)
- Branchcache Distributed Cache Mode Step by Step GuideDokument27 SeitenBranchcache Distributed Cache Mode Step by Step GuideDrazenMarjanovicNoch keine Bewertungen
- Model CTS congestion during placement with early clock flow or quick CTSDokument2 SeitenModel CTS congestion during placement with early clock flow or quick CTSShantiSwaroopNoch keine Bewertungen
- TCP Sockets LectureDokument23 SeitenTCP Sockets LectureShafaq KhanNoch keine Bewertungen
- Variation in Terminology: Rosen BryanDokument55 SeitenVariation in Terminology: Rosen BryanSameOldHatNoch keine Bewertungen
- Maximum Mark: 75: Cambridge International Examinations Cambridge International General Certificate of Secondary EducationDokument8 SeitenMaximum Mark: 75: Cambridge International Examinations Cambridge International General Certificate of Secondary EducationShenal PereraNoch keine Bewertungen
- WebDokument187 SeitenWebAkarsh LNoch keine Bewertungen
- Main Board EEPROM - RoboSapien V2 - RoboGuideDokument4 SeitenMain Board EEPROM - RoboSapien V2 - RoboGuideRICHARDNoch keine Bewertungen
- Basic FPGA Tutorial Vivado VerilogDokument183 SeitenBasic FPGA Tutorial Vivado VerilogfauzanismailNoch keine Bewertungen
- World Skills Collection MyRIO Interfacing PDFDokument87 SeitenWorld Skills Collection MyRIO Interfacing PDFchuyen truong100% (1)
- SQL - Join and BasicsDokument8 SeitenSQL - Join and BasicsfemiNoch keine Bewertungen
- Simatic Net: Step by Step: Ethernet Communication Between OPC Server and S7-200 Incl. CP243-1Dokument45 SeitenSimatic Net: Step by Step: Ethernet Communication Between OPC Server and S7-200 Incl. CP243-1Franco SotoNoch keine Bewertungen
- Creating Forms With COBOLDokument22 SeitenCreating Forms With COBOLmarmetusNoch keine Bewertungen
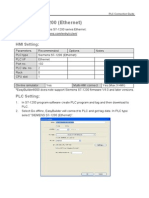
- Siemens S7 1200 Ethernet PDFDokument13 SeitenSiemens S7 1200 Ethernet PDFStephen BlanchardNoch keine Bewertungen
- Security Enhancement and Time Delay Consumption For Cloud Computing Using AES and RC6 AlgorithmDokument6 SeitenSecurity Enhancement and Time Delay Consumption For Cloud Computing Using AES and RC6 AlgorithmBONFRINGNoch keine Bewertungen
- MKS Implementer User Guide v.5.3 PDFDokument456 SeitenMKS Implementer User Guide v.5.3 PDFGermánNoch keine Bewertungen
- 2003 Vs 2008Dokument336 Seiten2003 Vs 2008suneel4tuNoch keine Bewertungen
- Jeffrey A. Hoffer, Mary B. Prescott, Fred R. Mcfadden: Modern Database Management 8 EditionDokument37 SeitenJeffrey A. Hoffer, Mary B. Prescott, Fred R. Mcfadden: Modern Database Management 8 EditionFarooq ShadNoch keine Bewertungen
- IEC 61850 standards for substation communicationDokument1 SeiteIEC 61850 standards for substation communicationfen01Noch keine Bewertungen
- Mail Merge in ExcelDokument2 SeitenMail Merge in ExcelFitriadi AriganiNoch keine Bewertungen
- Adafruit Ultimate Gps On The Raspberry PiDokument11 SeitenAdafruit Ultimate Gps On The Raspberry PiPaolo Castillo100% (1)
- Market Survey of Quick Heal in NepalDokument5 SeitenMarket Survey of Quick Heal in Nepalakusmarty2014Noch keine Bewertungen
- Topic: Syntax Directed Translations: Unit IvDokument52 SeitenTopic: Syntax Directed Translations: Unit Ivmaurya_rajesh804026Noch keine Bewertungen
- Microprocessors & Interfacing - CS 402Dokument9 SeitenMicroprocessors & Interfacing - CS 402Subhodh PapannaNoch keine Bewertungen
- LogDokument167 SeitenLogSyaiton ANoch keine Bewertungen
- Chicago Crime (2013) Analysis Using Pig and Visualization Using RDokument61 SeitenChicago Crime (2013) Analysis Using Pig and Visualization Using RSaurabh SharmaNoch keine Bewertungen
- (Google Interview Prep Guide) Site Reliability Manager (SRM)Dokument6 Seiten(Google Interview Prep Guide) Site Reliability Manager (SRM)PéterFarkasNoch keine Bewertungen
- 16-18 SRAM Data BackupDokument6 Seiten16-18 SRAM Data BackupNguyễn Khắc LợiNoch keine Bewertungen
- Database Design Phases and E-R Diagram ConstructionDokument44 SeitenDatabase Design Phases and E-R Diagram ConstructionZarin ArniNoch keine Bewertungen
- Chapter 01Dokument32 SeitenChapter 01Charlie420Noch keine Bewertungen