Das könnte Ihnen auch gefallen
- Assignment Week4Dokument3 SeitenAssignment Week4saigdv1978100% (2)
- VHDL Lab ManualDokument51 SeitenVHDL Lab Manualsaigdv1978Noch keine Bewertungen
- Memory Structures DRAM CellsDokument14 SeitenMemory Structures DRAM Cellssaigdv1978Noch keine Bewertungen
- Week 2 Course MaterialDokument60 SeitenWeek 2 Course Materialsaigdv1978Noch keine Bewertungen
- (Ercegovac Milos D., Lang Tomas) Digital Arithmeti (B-Ok - Xyz)Dokument731 Seiten(Ercegovac Milos D., Lang Tomas) Digital Arithmeti (B-Ok - Xyz)saigdv1978Noch keine Bewertungen
- Either Source or Destination Is One Of: CPU RegisterDokument81 SeitenEither Source or Destination Is One Of: CPU Registersaigdv1978Noch keine Bewertungen
- Week 1 Lecture MaterialDokument96 SeitenWeek 1 Lecture Materialsaigdv1978Noch keine Bewertungen
- Embedded Software in C For ARM Cortex MDokument114 SeitenEmbedded Software in C For ARM Cortex MMohamedHassanNoch keine Bewertungen
- Arduino Based Home Automation System Using Bluetooth Through An Android Mobile PDFDokument72 SeitenArduino Based Home Automation System Using Bluetooth Through An Android Mobile PDFsaigdv197859% (17)
- 6th Central Pay Commission Salary CalculatorDokument15 Seiten6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Wireless Sensor Networks SyllabusDokument3 SeitenWireless Sensor Networks Syllabussaigdv19780% (1)
- Digital System Design & Digital Ic ApplicationsDokument4 SeitenDigital System Design & Digital Ic Applicationssaigdv1978Noch keine Bewertungen
- Microprosser 8085Dokument15 SeitenMicroprosser 8085saigdv1978Noch keine Bewertungen
- Switching Theory and Logic DesignDokument2 SeitenSwitching Theory and Logic Designsaigdv1978Noch keine Bewertungen
- Ramachandra College of EngineeringDokument1 SeiteRamachandra College of Engineeringsaigdv1978Noch keine Bewertungen
- Ramachandra College of EngineeringDokument1 SeiteRamachandra College of Engineeringsaigdv1978Noch keine Bewertungen
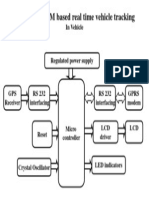
- GPRS and GPS Based Vehicle TrackingDokument1 SeiteGPRS and GPS Based Vehicle Trackingsaigdv1978Noch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Architectural Overview (Productname) Page 8 of 9Dokument8 SeitenArchitectural Overview (Productname) Page 8 of 9VIbhishanNoch keine Bewertungen
- Dot Net Application Development - KANINIDokument1 SeiteDot Net Application Development - KANINIVirender SehwagNoch keine Bewertungen
- Combine Worksheets From Multiple Workbooks Into OneDokument3 SeitenCombine Worksheets From Multiple Workbooks Into OneiksyotNoch keine Bewertungen
- Inteliscada Global Guide 1 4Dokument118 SeitenInteliscada Global Guide 1 4Aung MhNoch keine Bewertungen
- Chapter 5 - Cookies and SessionsDokument12 SeitenChapter 5 - Cookies and Sessionsወንድወሰን እርገጤNoch keine Bewertungen
- PF Assignment #01 - Amaan Ahmad - Sp22-Bct-004Dokument7 SeitenPF Assignment #01 - Amaan Ahmad - Sp22-Bct-004tota10694Noch keine Bewertungen
- Act10 InstrumentationDokument4 SeitenAct10 InstrumentationErvin MedranoNoch keine Bewertungen
- Coen445 Lab4 Socket ProgrammingDokument10 SeitenCoen445 Lab4 Socket ProgrammingBansIa ShobhitNoch keine Bewertungen
- EPI Info 7 PresentationDokument25 SeitenEPI Info 7 PresentationQONITAHQONITAHNoch keine Bewertungen
- SAP Business Technology Platform Training For Professional (CAPM and BAS Included)Dokument15 SeitenSAP Business Technology Platform Training For Professional (CAPM and BAS Included)rudra GuptaNoch keine Bewertungen
- Plugin LoadingDokument5 SeitenPlugin LoadinggdfdNoch keine Bewertungen
- Buy Quest Products Buy Guy'S Book Buy Quest Products: Top Tips For Oracle SQL TuningDokument41 SeitenBuy Quest Products Buy Guy'S Book Buy Quest Products: Top Tips For Oracle SQL TuningLuis A. Alvarez AngelesNoch keine Bewertungen
- Linear Search and Binary SearchDokument24 SeitenLinear Search and Binary SearchADityaNoch keine Bewertungen
- AWN Lecture-2Dokument33 SeitenAWN Lecture-2Ahmad AwaisNoch keine Bewertungen
- Unit Iv Advanced Microprocessor Notes PDFDokument73 SeitenUnit Iv Advanced Microprocessor Notes PDFPadmanaban MNoch keine Bewertungen
- Contiki SlidesDokument90 SeitenContiki SlidesledoantuanNoch keine Bewertungen
- Application Note Slave Controller PHY Selection GuideDokument10 SeitenApplication Note Slave Controller PHY Selection GuidemikeNoch keine Bewertungen
- Julia DocumentationDokument974 SeitenJulia DocumentationrotmausNoch keine Bewertungen
- AbhilashGopalakrishna-CV PDFDokument3 SeitenAbhilashGopalakrishna-CV PDFZamirtalent TrNoch keine Bewertungen
- Uniopc Opclink IntouchDokument8 SeitenUniopc Opclink IntouchvacsaaNoch keine Bewertungen
- Unit 1: Software Engineering FundamentalsDokument20 SeitenUnit 1: Software Engineering FundamentalsNâ MííNoch keine Bewertungen
- Python ProgrammingDokument142 SeitenPython Programmingshahrukhkr.gptNoch keine Bewertungen
- Free Wifi On 2023 Without Paying BillsDokument1 SeiteFree Wifi On 2023 Without Paying BillsAleph TavNoch keine Bewertungen
- 6.4.1.3 Packet Tracer - Configure Initial Router SettingsDokument4 Seiten6.4.1.3 Packet Tracer - Configure Initial Router SettingsMichelle Ancajas100% (9)
- Microprocessor Programming and System Design-1Dokument34 SeitenMicroprocessor Programming and System Design-1Yaar RaiderNoch keine Bewertungen
- Sage X3 Web ServicesDokument114 SeitenSage X3 Web ServicesIván100% (1)
- TLE CHS q3 Mod5 Safety Precautions (Occupational Health and Safety)Dokument15 SeitenTLE CHS q3 Mod5 Safety Precautions (Occupational Health and Safety)Alona AcotNoch keine Bewertungen
- LIT US 173152 1280 Enterprise LRDokument4 SeitenLIT US 173152 1280 Enterprise LRCesar YañezNoch keine Bewertungen
- Defining Networks With The OSI ModelDokument28 SeitenDefining Networks With The OSI ModelEdin VucinicNoch keine Bewertungen
- Developing Applications On STM32CubeF4 With RTOSDokument26 SeitenDeveloping Applications On STM32CubeF4 With RTOSNguyen Tuan DanhNoch keine Bewertungen