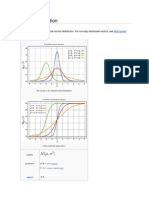
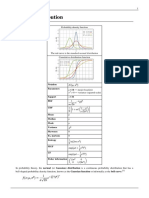
Das könnte Ihnen auch gefallen
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Von EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Noch keine Bewertungen
- Handout For Chapters 1-3 of Bouchaud: 1 DenitionsDokument10 SeitenHandout For Chapters 1-3 of Bouchaud: 1 DenitionsStefano DucaNoch keine Bewertungen
- New Microsoft Office Word DocumentDokument941 SeitenNew Microsoft Office Word DocumentPriya VenugopalNoch keine Bewertungen
- A Note On Particle Kinematics in Ho Rava-Lifshitz ScenariosDokument8 SeitenA Note On Particle Kinematics in Ho Rava-Lifshitz ScenariosAlexandros KouretsisNoch keine Bewertungen
- Linear System and BackgroundDokument24 SeitenLinear System and BackgroundEdmilson_Q_FilhoNoch keine Bewertungen
- Gamma DistributionDokument30 SeitenGamma DistributionshardultagalpallewarNoch keine Bewertungen
- On Convergence Rates in The Central Limit Theorems For Combinatorial StructuresDokument18 SeitenOn Convergence Rates in The Central Limit Theorems For Combinatorial StructuresValerio CambareriNoch keine Bewertungen
- Stable Probability Distributions and Their Domains of Attraction: ApproachDokument20 SeitenStable Probability Distributions and Their Domains of Attraction: ApproachDibbendu RoyNoch keine Bewertungen
- Peter L. BartlettDokument11 SeitenPeter L. BartlettRaiden Berte HasegawaNoch keine Bewertungen
- Computation of Determinants Using Contour IntegralsDokument12 SeitenComputation of Determinants Using Contour Integrals123chessNoch keine Bewertungen
- Handout 1Dokument16 SeitenHandout 1Chadwick BarclayNoch keine Bewertungen
- Normal DistributionDokument30 SeitenNormal Distributionbraulio.dantas-1Noch keine Bewertungen
- Generalized Logistic Distributions: Rameshwar D. Gupta Debasis KunduDokument23 SeitenGeneralized Logistic Distributions: Rameshwar D. Gupta Debasis KunduOte OteNoch keine Bewertungen
- Conditional Expectations And Renormalization: d dt φ (t) = R (φ (t) ) , φ (0) = x,, R, x, i = 1, - . -, n, and t isDokument14 SeitenConditional Expectations And Renormalization: d dt φ (t) = R (φ (t) ) , φ (0) = x,, R, x, i = 1, - . -, n, and t isLouis LingNoch keine Bewertungen
- Andersson Djehiche - AMO 2011Dokument16 SeitenAndersson Djehiche - AMO 2011artemischen0606Noch keine Bewertungen
- Normal Distribution - Wikipedia, The Free EncyclopediaDokument22 SeitenNormal Distribution - Wikipedia, The Free EncyclopediaLieu Dinh PhungNoch keine Bewertungen
- A Convenient Way of Generating Normal Random Variables Using Generalized Exponential DistributionDokument11 SeitenA Convenient Way of Generating Normal Random Variables Using Generalized Exponential DistributionvsalaiselvamNoch keine Bewertungen
- Risk Analysis For Information and Systems Engineering: INSE 6320 - Week 3Dokument9 SeitenRisk Analysis For Information and Systems Engineering: INSE 6320 - Week 3ALIKNFNoch keine Bewertungen
- Exponential DistributionDokument15 SeitenExponential DistributionThejaswiniNoch keine Bewertungen
- The Power Normal DistributionDokument7 SeitenThe Power Normal DistributionMuhammad SatriyoNoch keine Bewertungen
- Random Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilityDokument14 SeitenRandom Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilitySeham RaheelNoch keine Bewertungen
- Advanced StatisticsDokument131 SeitenAdvanced Statisticsmurlder100% (1)
- Noether's Theorem: Proof + Where It Fails (Diffeomorphisms)Dokument9 SeitenNoether's Theorem: Proof + Where It Fails (Diffeomorphisms)RockBrentwoodNoch keine Bewertungen
- Discrete Time Fourier Series Properties: Magnitude Spectrum of X (N), and A Plot ofDokument11 SeitenDiscrete Time Fourier Series Properties: Magnitude Spectrum of X (N), and A Plot ofSk Umesh UmeshNoch keine Bewertungen
- Group 6Dokument39 SeitenGroup 61DT20CS148 Sudarshan SinghNoch keine Bewertungen
- Random Cool Stuff: AlculusDokument5 SeitenRandom Cool Stuff: AlculusBoyang QinNoch keine Bewertungen
- Wavelets 99Dokument12 SeitenWavelets 99Mary Arguijo JonesNoch keine Bewertungen
- 2006 Jessen - Mikosch Regularly Varying FunctionsDokument22 Seiten2006 Jessen - Mikosch Regularly Varying FunctionsJonas SprindysNoch keine Bewertungen
- TMRCA EstimatesDokument9 SeitenTMRCA Estimatesdavejphys100% (1)
- RF Design Lecture NotesDokument79 SeitenRF Design Lecture NotesrachnaNoch keine Bewertungen
- ARCH Models DefinitionDokument2 SeitenARCH Models DefinitionHuy Hai VuNoch keine Bewertungen
- Pareto Analysis TechniqueDokument15 SeitenPareto Analysis TechniqueAlberipaNoch keine Bewertungen
- M3L08Dokument9 SeitenM3L08abimanaNoch keine Bewertungen
- Generalised Coupled Tensor Factorisation: Taylan - Cemgil, Umut - Simsekli @boun - Edu.trDokument9 SeitenGeneralised Coupled Tensor Factorisation: Taylan - Cemgil, Umut - Simsekli @boun - Edu.trxmercanNoch keine Bewertungen
- Application of Differential Equation in Computer ScienceDokument6 SeitenApplication of Differential Equation in Computer ScienceUzair Razzaq100% (1)
- Tensor PDFDokument25 SeitenTensor PDFPero PericNoch keine Bewertungen
- Leibniz Integral RuleDokument14 SeitenLeibniz Integral RuleDaniel GregorioNoch keine Bewertungen
- Assignment of Signal and System: Submitted byDokument12 SeitenAssignment of Signal and System: Submitted bynaeem444454Noch keine Bewertungen
- The Annals of Applied Probability 10.1214/10-AAP698 Institute of Mathematical StatisticsDokument20 SeitenThe Annals of Applied Probability 10.1214/10-AAP698 Institute of Mathematical StatisticsThu NguyenNoch keine Bewertungen
- Fundamental Lemmas of The Calculus of Variations: Appendix ADokument19 SeitenFundamental Lemmas of The Calculus of Variations: Appendix AEugenio CapielloNoch keine Bewertungen
- Ito's LemmaDokument7 SeitenIto's Lemmasambhu_nNoch keine Bewertungen
- Multivariate Normal DistributionDokument9 SeitenMultivariate Normal DistributionccffffNoch keine Bewertungen
- Lecture 9. Failure Probabilities and Safety Indexes: Jesper Ryd enDokument24 SeitenLecture 9. Failure Probabilities and Safety Indexes: Jesper Ryd enAmar AlicheNoch keine Bewertungen
- Monte Carlo TechniquesDokument9 SeitenMonte Carlo TechniquesCecovam Mamut MateNoch keine Bewertungen
- Paulo Gonc Alves Patrice Abry, Gabriel Rilling, Patrick FlandrinDokument4 SeitenPaulo Gonc Alves Patrice Abry, Gabriel Rilling, Patrick FlandrinS Santha KumarNoch keine Bewertungen
- Moments and Moment Generating FunctionsDokument17 SeitenMoments and Moment Generating FunctionsDharamNoch keine Bewertungen
- J. Differential Geometry 95 (2013) 71-119: Received 5/25/2012Dokument49 SeitenJ. Differential Geometry 95 (2013) 71-119: Received 5/25/2012Leghrieb RaidNoch keine Bewertungen
- ANG2ed 3 RDokument135 SeitenANG2ed 3 Rbenieo96Noch keine Bewertungen
- The Uniform DistributnDokument7 SeitenThe Uniform DistributnsajeerNoch keine Bewertungen
- Central Limit TheoremDokument16 SeitenCentral Limit TheoremkernelexploitNoch keine Bewertungen
- Some Continuous and Discrete Distributions: X y B ADokument8 SeitenSome Continuous and Discrete Distributions: X y B ASandipa MalakarNoch keine Bewertungen
- HMWK 4Dokument5 SeitenHMWK 4Jasmine NguyenNoch keine Bewertungen
- Spectral Analysis of Stochastic ProcessesDokument76 SeitenSpectral Analysis of Stochastic ProcessesanuragnarraNoch keine Bewertungen
- A Two Parameter Distribution Obtained byDokument15 SeitenA Two Parameter Distribution Obtained byc122003Noch keine Bewertungen
- Unit-I: Differential Equations ofDokument9 SeitenUnit-I: Differential Equations ofSai PrajitNoch keine Bewertungen
- ExamDokument3 SeitenExamMohan BistaNoch keine Bewertungen
- CS 717: EndsemDokument5 SeitenCS 717: EndsemGanesh RamakrishnanNoch keine Bewertungen
- Difference Equations in Normed Spaces: Stability and OscillationsVon EverandDifference Equations in Normed Spaces: Stability and OscillationsNoch keine Bewertungen
- Curtis Mathes CM25020S by Samsung - Owner's ManualDokument49 SeitenCurtis Mathes CM25020S by Samsung - Owner's ManualpadawerNoch keine Bewertungen
- State Magazine, May 2001Dokument38 SeitenState Magazine, May 2001State MagazineNoch keine Bewertungen
- Zencrack Installation and ExecutionDokument48 SeitenZencrack Installation and ExecutionJu waNoch keine Bewertungen
- Modeling and Simulation of The Temperature Profile Along Offshore Pipeline of An Oil and Gas Flow: Effect of Insulation MaterialsDokument8 SeitenModeling and Simulation of The Temperature Profile Along Offshore Pipeline of An Oil and Gas Flow: Effect of Insulation MaterialsInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Ottawa County May ElectionDokument7 SeitenOttawa County May ElectionWXMINoch keine Bewertungen
- Problem Sheet 3 - External Forced Convection - WatermarkDokument2 SeitenProblem Sheet 3 - External Forced Convection - WatermarkUzair KhanNoch keine Bewertungen
- Appendix h6 Diffuser Design InvestigationDokument51 SeitenAppendix h6 Diffuser Design InvestigationVeena NageshNoch keine Bewertungen
- Oil RussiaDokument8 SeitenOil RussiaAyush AhujaNoch keine Bewertungen
- The Sphere Circumscribing A TetrahedronDokument4 SeitenThe Sphere Circumscribing A TetrahedronRaghuveer ChandraNoch keine Bewertungen
- Introduction To Plant Physiology!!!!Dokument112 SeitenIntroduction To Plant Physiology!!!!Bio SciencesNoch keine Bewertungen
- LAB - Testing Acids & BasesDokument3 SeitenLAB - Testing Acids & BasesRita AnyanwuNoch keine Bewertungen
- Micron Serial NOR Flash Memory: 3V, Multiple I/O, 4KB Sector Erase N25Q256A FeaturesDokument92 SeitenMicron Serial NOR Flash Memory: 3V, Multiple I/O, 4KB Sector Erase N25Q256A FeaturesAENoch keine Bewertungen
- Report On Sonepur MelaDokument4 SeitenReport On Sonepur Melakashtum23Noch keine Bewertungen
- O RTIZDokument2 SeitenO RTIZKhimberly Xylem OrtizNoch keine Bewertungen
- Eimco Elecon Initiating Coverage 04072016Dokument19 SeitenEimco Elecon Initiating Coverage 04072016greyistariNoch keine Bewertungen
- Safety Data Sheet: Section 1. IdentificationDokument10 SeitenSafety Data Sheet: Section 1. IdentificationAnonymous Wj1DqbENoch keine Bewertungen
- Unit 6 - ListeningDokument11 SeitenUnit 6 - Listeningtoannv8187Noch keine Bewertungen
- A Cultura-Mundo - Resposta A Uma SociedDokument7 SeitenA Cultura-Mundo - Resposta A Uma SociedSevero UlissesNoch keine Bewertungen
- Clostridium BotulinumDokument37 SeitenClostridium Botulinummaria dulceNoch keine Bewertungen
- FeCl3 Msds - VISCOSITYDokument9 SeitenFeCl3 Msds - VISCOSITYramkesh rathaurNoch keine Bewertungen
- Hamilton-Resume 4Dokument1 SeiteHamilton-Resume 4api-654686470Noch keine Bewertungen
- DLL English 7-10, Week 1 Q1Dokument8 SeitenDLL English 7-10, Week 1 Q1Nemfa TumacderNoch keine Bewertungen
- Opening StrategyDokument6 SeitenOpening StrategyashrafsekalyNoch keine Bewertungen
- Pre-Colonial Philippine ArtDokument5 SeitenPre-Colonial Philippine Artpaulinavera100% (5)
- Ecological Pyramids WorksheetDokument3 SeitenEcological Pyramids Worksheetapi-26236818833% (3)
- Public Economics - All Lecture Note PDFDokument884 SeitenPublic Economics - All Lecture Note PDFAllister HodgeNoch keine Bewertungen
- Lagundi/Dangla (Vitex Negundo)Dokument2 SeitenLagundi/Dangla (Vitex Negundo)Derrick Yson (Mangga Han)Noch keine Bewertungen
- Review Women With Moustaches and Men Without Beards - Gender and Sexual Anxieties of Iranian Modernity PDFDokument3 SeitenReview Women With Moustaches and Men Without Beards - Gender and Sexual Anxieties of Iranian Modernity PDFBilal SalaamNoch keine Bewertungen
- Student EssaysDokument41 SeitenStudent EssaysAsif RahmanNoch keine Bewertungen
- Radiant Protection Force Pvt. LTD.,: Col David DevasahayamDokument13 SeitenRadiant Protection Force Pvt. LTD.,: Col David Devasahayamabhilash0029Noch keine Bewertungen