Das könnte Ihnen auch gefallen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- AS and A Level Business Studies Student's CD-ROM: Help NotesDokument5 SeitenAS and A Level Business Studies Student's CD-ROM: Help NotesMuhammad Salim Ullah KhanNoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Keystroke Logging KeyloggingDokument14 SeitenKeystroke Logging KeyloggingAnjali100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Shortcut Set IndesignDokument47 SeitenShortcut Set IndesignIonel PopescuNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Unit 11 Assignment Brief 2Dokument6 SeitenUnit 11 Assignment Brief 2HanzNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Learn English in Sinhala - Lesson 05Dokument7 SeitenLearn English in Sinhala - Lesson 05Himali AnupamaNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Configuration Managent Plan AS9100 & AS9006 ChecklistDokument6 SeitenConfiguration Managent Plan AS9100 & AS9006 Checklistahmed AwadNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Alumni Management ToolDokument41 SeitenAlumni Management ToolRaphael Owino0% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Data Statistics Number of Records Passed 961Dokument18 SeitenData Statistics Number of Records Passed 961godiyal4uNoch keine Bewertungen
- Color Detection & Segmentation Based Invisible Cloak PresentationDokument31 SeitenColor Detection & Segmentation Based Invisible Cloak PresentationAviral ChaurasiaNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- DRS 2018 Simeone Et Al. FinalDokument13 SeitenDRS 2018 Simeone Et Al. FinalLuca SimeoneNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- AVEVA ERM-Design Integration User Guide For AVEVA MarineDokument213 SeitenAVEVA ERM-Design Integration User Guide For AVEVA Marinexxx100% (3)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Epicor ERP Currency Management CourseDokument41 SeitenEpicor ERP Currency Management CourseHina Sohail0% (1)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- IT 243 DennisWixom TestBank Chapter07Dokument22 SeitenIT 243 DennisWixom TestBank Chapter07MuslimShahenshah100% (1)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
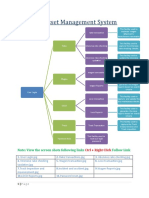
- Rail Asset Management System: Follow LinkDokument4 SeitenRail Asset Management System: Follow LinkAbhiroop AwasthiNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Hysys Installation V 7.3Dokument1 SeiteHysys Installation V 7.3Naik LarkaNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Android Lab 3Dokument11 SeitenAndroid Lab 3Abdullah SalemNoch keine Bewertungen
- Candes, Li, Soltanolkotabi - Phase Retrieval Via WIrtinger FlowDokument23 SeitenCandes, Li, Soltanolkotabi - Phase Retrieval Via WIrtinger Flowaleong1Noch keine Bewertungen
- Karl Dvorak, Geschichte Des K.K. Infanterie-Regiments Nr. 41, Vol. IIIDokument322 SeitenKarl Dvorak, Geschichte Des K.K. Infanterie-Regiments Nr. 41, Vol. IIIGiovanni Cerino-BadoneNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Simatic Iot2040: The Intelligent Gateway For Industrial Iot SolutionsDokument38 SeitenSimatic Iot2040: The Intelligent Gateway For Industrial Iot Solutionsmfonseca31Noch keine Bewertungen
- Interference Prevention Area Function: Output SignalDokument4 SeitenInterference Prevention Area Function: Output SignalNAIT OTMANENoch keine Bewertungen
- TWS Troubleshooting GuideDokument203 SeitenTWS Troubleshooting GuideJosé E. FélixNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Sample FIleDokument20 SeitenSample FIleHARSH PLAYZNoch keine Bewertungen
- (John C Russ) The Image Processing Cookbook (B-Ok - Xyz)Dokument108 Seiten(John C Russ) The Image Processing Cookbook (B-Ok - Xyz)getinetNoch keine Bewertungen
- Forex Spectrum: Hi ThereDokument10 SeitenForex Spectrum: Hi ThereSonu ThakurNoch keine Bewertungen
- 07 MVCDokument15 Seiten07 MVCJoel Sambora MugileNoch keine Bewertungen
- Ademco Lynx - Installation and Setup GuideDokument72 SeitenAdemco Lynx - Installation and Setup Guidedom1nanceNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Practice Worksheet Class4Dokument2 SeitenPractice Worksheet Class4Priyadarshini ShettyNoch keine Bewertungen
- Course Outline CSC 588 Data Warehousing and Data Mining1Dokument5 SeitenCourse Outline CSC 588 Data Warehousing and Data Mining1Madawi AlOtaibiNoch keine Bewertungen
- Stepper Motor Set UpDokument3 SeitenStepper Motor Set UpChockalingam ʀᴏʙᴏᴛɪᴄsNoch keine Bewertungen
- 11 New Tips For Boosting Windows XP PerformanceDokument5 Seiten11 New Tips For Boosting Windows XP PerformanceBill PetrieNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)