Das könnte Ihnen auch gefallen
- Tion Sport: A Mobile Application Designed To Improve A School's Sport Event Scheduling SystemDokument10 SeitenTion Sport: A Mobile Application Designed To Improve A School's Sport Event Scheduling SystemijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal On Cryptography and Information Security (IJCIS)Dokument2 SeitenInternational Journal On Cryptography and Information Security (IJCIS)ijcisjournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument1 SeiteInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument1 SeiteInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- Scope & Topics: ISSN: 2319 - 5398 (Online) 2319 - 8990 (Print)Dokument3 SeitenScope & Topics: ISSN: 2319 - 5398 (Online) 2319 - 8990 (Print)ijccmsNoch keine Bewertungen
- International Journal On Soft Computing, Artificial Intelligence and Applications (IJSCAI)Dokument2 SeitenInternational Journal On Soft Computing, Artificial Intelligence and Applications (IJSCAI)ijscaiNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- Call For Paper - International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenCall For Paper - International Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- Call For Paper - International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenCall For Paper - International Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument1 SeiteInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument1 SeiteInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications IJESADokument1 SeiteInternational Journal of Embedded Systems and Applications IJESAijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- International Journal of Embedded Systems and Applications (IJESA)Dokument2 SeitenInternational Journal of Embedded Systems and Applications (IJESA)ijesajournalNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5783)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- SQL Server - GoldenGateDokument52 SeitenSQL Server - GoldenGaterajiv_ndpt8394Noch keine Bewertungen
- DFC Session Management WhitepaperDokument11 SeitenDFC Session Management Whitepaperjazarja100% (1)
- Problems and solutions in software maintenance systemsDokument3 SeitenProblems and solutions in software maintenance systemsJavier MejiaNoch keine Bewertungen
- Kud Venkat SQL Server NotesDokument185 SeitenKud Venkat SQL Server Noteskadiyamramana80% (10)
- NRF51 Series Reference Manual v3.0Dokument174 SeitenNRF51 Series Reference Manual v3.0johan straussNoch keine Bewertungen
- GitHub - Nishad - Udemy-Dl-Windows - A Windows Utility To Download Courses From Udemy For Personal Offline UseDokument3 SeitenGitHub - Nishad - Udemy-Dl-Windows - A Windows Utility To Download Courses From Udemy For Personal Offline UseleekiangyenNoch keine Bewertungen
- W3Schools SQLTutorial PDFDokument35 SeitenW3Schools SQLTutorial PDFMoon18089% (18)
- IP1Dokument21 SeitenIP1api-3822363Noch keine Bewertungen
- Class Design GuidelinesDokument16 SeitenClass Design GuidelinesRenz Casipit100% (1)
- Non-Recursive Inorder Tree Traversal Algorithm ExplainedDokument11 SeitenNon-Recursive Inorder Tree Traversal Algorithm Explaineddevesh2109Noch keine Bewertungen
- IBM BPM Best Practices - Process Modeling 5 Golden Rules - BHDokument31 SeitenIBM BPM Best Practices - Process Modeling 5 Golden Rules - BHGustavo ApodacaNoch keine Bewertungen
- Multivector&SIMD Computers Ch8Dokument12 SeitenMultivector&SIMD Computers Ch8Charu DhingraNoch keine Bewertungen
- Parametros Natural LanguageDokument455 SeitenParametros Natural LanguageHiagoDutra0% (1)
- 12 Priniciples of Agile ManifestoDokument3 Seiten12 Priniciples of Agile ManifestoJane Ruby GonzalesNoch keine Bewertungen
- CRUD Operation On Google Spreadsheet Using NodeJS - Agira Technologies - MediumDokument22 SeitenCRUD Operation On Google Spreadsheet Using NodeJS - Agira Technologies - MediumSingh SudipNoch keine Bewertungen
- AG2425 Spatial DatabasesDokument36 SeitenAG2425 Spatial DatabasessriniNoch keine Bewertungen
- Day - 4 VI - Editor1Dokument1 SeiteDay - 4 VI - Editor1DeepakNoch keine Bewertungen
- Book StoreDokument49 SeitenBook Storesarvesh.bharti67% (6)
- OMNI 3D New FeaturesDokument3 SeitenOMNI 3D New Featureshendri sulistiawanNoch keine Bewertungen
- T Test: Table of Critical T ValuesDokument7 SeitenT Test: Table of Critical T ValuesMursalin Allin'kNoch keine Bewertungen
- Citrix Tips and TricksDokument19 SeitenCitrix Tips and Trickspanneer1981Noch keine Bewertungen
- Technical Architecture System Design TemplateDokument18 SeitenTechnical Architecture System Design TemplateSmitasamrat0% (1)
- Access Windows System Tray and AppsDokument9 SeitenAccess Windows System Tray and AppsHarsh ChaddaNoch keine Bewertungen
- Using DNP3 & IEC 60870-5 Communication Protocols in The Oil & Gas IndustryDokument4 SeitenUsing DNP3 & IEC 60870-5 Communication Protocols in The Oil & Gas IndustryzdnNoch keine Bewertungen
- Scripting SagaDokument19 SeitenScripting SagaGeØrge MihaiNoch keine Bewertungen
- SPSS QC Scripting HelpDokument6 SeitenSPSS QC Scripting HelpMaverick 'Moriarty' JonesNoch keine Bewertungen
- Complete 8086 Instruction SetDokument34 SeitenComplete 8086 Instruction SetjmmondeNoch keine Bewertungen
- Expert Systems Principles and Programming Solution Manual PDFDokument2 SeitenExpert Systems Principles and Programming Solution Manual PDFPatrickNoch keine Bewertungen
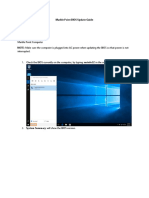
- Marble Point BIOS Update GuideDokument6 SeitenMarble Point BIOS Update Guidecodigorojo2000Noch keine Bewertungen
- Computer Assisted Audit Techniques CAATs PDFDokument2 SeitenComputer Assisted Audit Techniques CAATs PDFandika “RIEZ12” riez0% (1)