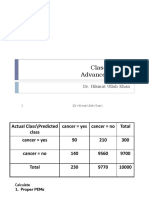
Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (894)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Packt - Hands On - Ensemble.learning - With.python.2019Dokument424 SeitenPackt - Hands On - Ensemble.learning - With.python.2019yohoyonNoch keine Bewertungen
- Detection of Defects in Rolled Stainless Steel Plates by Machine LearningDokument7 SeitenDetection of Defects in Rolled Stainless Steel Plates by Machine Learningalbert20081994Noch keine Bewertungen
- MODULE 4-Dr - GMDokument23 SeitenMODULE 4-Dr - GMgeetha megharajNoch keine Bewertungen
- Ensemble Learning: HARIS JAMIL (FA18-RCS-003) HOOIRA ANAM (FA18-RCS-004)Dokument14 SeitenEnsemble Learning: HARIS JAMIL (FA18-RCS-003) HOOIRA ANAM (FA18-RCS-004)suppiNoch keine Bewertungen
- Class BasicDokument75 SeitenClass BasicBasant YadavNoch keine Bewertungen
- Detection of Online Employment Scam Through Fake Jobs Using Random Forest ClassifierDokument8 SeitenDetection of Online Employment Scam Through Fake Jobs Using Random Forest ClassifierIJRASETPublicationsNoch keine Bewertungen
- Comparison Among Methods of Ensemble Learning: July 2013Dokument6 SeitenComparison Among Methods of Ensemble Learning: July 2013Vladislav NovikovNoch keine Bewertungen
- 07 ML Classificaion Advanced KappaDokument18 Seiten07 ML Classificaion Advanced KappaIn TechNoch keine Bewertungen
- Data Science Interview QuestionsDokument300 SeitenData Science Interview QuestionsMaheshBirajdar100% (1)
- Machine Learning Algorithms - A Review: January 2019Dokument7 SeitenMachine Learning Algorithms - A Review: January 2019Nitin PrasadNoch keine Bewertungen
- DS Cheat SheetsDokument18 SeitenDS Cheat SheetspunmapiNoch keine Bewertungen
- Identifying The Gender of A Voice Using Acoustic PropertiesDokument8 SeitenIdentifying The Gender of A Voice Using Acoustic PropertiesKumara SNoch keine Bewertungen
- Concepts and Techniques: - Chapter 8Dokument81 SeitenConcepts and Techniques: - Chapter 8TotuNoch keine Bewertungen
- SQL Injection Detection Using Machine LearningDokument51 SeitenSQL Injection Detection Using Machine LearningPramono PramonoNoch keine Bewertungen
- Multi-Dimensional Feature Fusion and Stacking Ensemble MechanismDokument14 SeitenMulti-Dimensional Feature Fusion and Stacking Ensemble MechanismyousufNoch keine Bewertungen
- Artificial Intelligence and Machine LearningDokument11 SeitenArtificial Intelligence and Machine LearningPa Krishna Sankar100% (1)
- Ensemble LearningDokument7 SeitenEnsemble LearningJavier Garcia RajoyNoch keine Bewertungen
- Thesis Sales ForcastingDokument43 SeitenThesis Sales ForcastingHainsley EdwardsNoch keine Bewertungen
- 2021 IC FICTA Boosting accuracyDokument13 Seiten2021 IC FICTA Boosting accuracyR.V.S.LALITHANoch keine Bewertungen
- Concepts and Techniques: - Chapter 8Dokument42 SeitenConcepts and Techniques: - Chapter 8Kevin FebriansyahNoch keine Bewertungen
- Chapter 2Dokument47 SeitenChapter 2david AbotsitseNoch keine Bewertungen
- E4fbc2f-C755-Ed1a-C18-F18ec25eb0d Ensemble Learning Bagging Boosting and StackingDokument6 SeitenE4fbc2f-C755-Ed1a-C18-F18ec25eb0d Ensemble Learning Bagging Boosting and StackingluiszertucheNoch keine Bewertungen
- Artificial Intelligence by Luis Rabelo PDFDokument364 SeitenArtificial Intelligence by Luis Rabelo PDFArooge FKNoch keine Bewertungen
- Detecting Phishing Websites Using Machine LearningDokument6 SeitenDetecting Phishing Websites Using Machine LearningRohan KashyapNoch keine Bewertungen
- Information Sciences: Decui Liang, Bochun YiDokument18 SeitenInformation Sciences: Decui Liang, Bochun YiRico Bayu WiranataNoch keine Bewertungen
- Concepts and Techniques: Data MiningDokument81 SeitenConcepts and Techniques: Data Miningnayanisateesh2805100% (1)
- Chapter4 Classification PredictionDokument173 SeitenChapter4 Classification PredictionJimsy JohnsonNoch keine Bewertungen
- ISYE 7406 Fall 2023 SyllabusDokument10 SeitenISYE 7406 Fall 2023 Syllabuslauren.barthenheierNoch keine Bewertungen
- Kurt Varmuza-Chemometrics in Practical Applications-Intech (2012)Dokument338 SeitenKurt Varmuza-Chemometrics in Practical Applications-Intech (2012)David SantiagoNoch keine Bewertungen
- Data Science Related Interview QuestionDokument77 SeitenData Science Related Interview QuestionTanvir Rashid100% (1)