Das könnte Ihnen auch gefallen
- Alimentación óptima en las diferentes etapas de la vidaDokument52 SeitenAlimentación óptima en las diferentes etapas de la vidaErika DíazNoch keine Bewertungen
- LípidosDokument44 SeitenLípidosErika DíazNoch keine Bewertungen
- Grupos Lactancia MaternaDokument50 SeitenGrupos Lactancia MaternaErika DíazNoch keine Bewertungen
- LípidosDokument44 SeitenLípidosErika DíazNoch keine Bewertungen
- Alimentación en Diferentes Grupos Etarios.Dokument58 SeitenAlimentación en Diferentes Grupos Etarios.Erika DíazNoch keine Bewertungen
- Fenómeno Primer PasoDokument3 SeitenFenómeno Primer PasoSory Buele73% (11)
- Súper Familia Citocromo P450Dokument2 SeitenSúper Familia Citocromo P450Erika DíazNoch keine Bewertungen
- AGUADokument29 SeitenAGUAErika DíazNoch keine Bewertungen
- Hne - EdaDokument13 SeitenHne - EdaErika DíazNoch keine Bewertungen
- Aporte EnergéticoDokument28 SeitenAporte EnergéticoErika DíazNoch keine Bewertungen
- La Casa Ecológicamente AutosuficienteDokument389 SeitenLa Casa Ecológicamente AutosuficienteTenocelome Hombre Jaguar100% (12)
- Sesion 6 Primer Paso HepáticoDokument22 SeitenSesion 6 Primer Paso HepáticosayraNoch keine Bewertungen
- Infografía Receptores FarmacológicosDokument6 SeitenInfografía Receptores FarmacológicosErika DíazNoch keine Bewertungen
- Pelicula El MédicoDokument4 SeitenPelicula El MédicoErika Díaz100% (1)
- El Citocromo P450Dokument1 SeiteEl Citocromo P450Erika DíazNoch keine Bewertungen
- Parámetros farmacocinéticos de la absorciónDokument1 SeiteParámetros farmacocinéticos de la absorciónErika DíazNoch keine Bewertungen
- Obstrucción UreteralDokument41 SeitenObstrucción UreteralErika DíazNoch keine Bewertungen
- Fichas Tecnicas de FarmacosDokument9 SeitenFichas Tecnicas de FarmacosErika DíazNoch keine Bewertungen
- Cirrosis HepaticaDokument26 SeitenCirrosis HepaticaErika DíazNoch keine Bewertungen
- Prevención gastroenteritis caracteresDokument2 SeitenPrevención gastroenteritis caracteresErika DíazNoch keine Bewertungen
- Esquema de Vacunación Neumonía - InfluenzaDokument3 SeitenEsquema de Vacunación Neumonía - InfluenzaErika DíazNoch keine Bewertungen
- Enfermedad de Addison: caso clínicoDokument20 SeitenEnfermedad de Addison: caso clínicoErika DíazNoch keine Bewertungen
- Obstrucción Uretral Anatomía Causas Síntomas TratamientoDokument4 SeitenObstrucción Uretral Anatomía Causas Síntomas TratamientoErika DíazNoch keine Bewertungen
- Relajacion Del Piso PelvicoDokument15 SeitenRelajacion Del Piso PelvicoErika DíazNoch keine Bewertungen
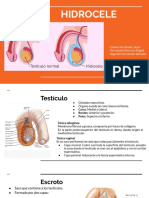
- Hidrocele: causas, síntomas y tratamientoDokument30 SeitenHidrocele: causas, síntomas y tratamientoErika Díaz100% (2)
- Rinon en HerraduraDokument23 SeitenRinon en HerraduraErika DíazNoch keine Bewertungen
- PancreatitisDokument21 SeitenPancreatitisErika DíazNoch keine Bewertungen
- Reporte Caso Clinico NeumotoraxDokument8 SeitenReporte Caso Clinico NeumotoraxErika DíazNoch keine Bewertungen
- DIVERTICULOSISDokument69 SeitenDIVERTICULOSISErika DíazNoch keine Bewertungen
- Reporte Caso Clinico DiverticulosisDokument21 SeitenReporte Caso Clinico DiverticulosisErika DíazNoch keine Bewertungen
- Diseño Curricular DIPL Base de DatosDokument9 SeitenDiseño Curricular DIPL Base de DatosJulio ArgaezNoch keine Bewertungen
- UnivSevilla 4. Dinámica Del Modelo Relacional - Álgebra Relacional (2020) - PPTDokument37 SeitenUnivSevilla 4. Dinámica Del Modelo Relacional - Álgebra Relacional (2020) - PPTJaime BarraganNoch keine Bewertungen
- Consulta OracleDokument3 SeitenConsulta Oraclef1310522Noch keine Bewertungen
- Resumen en Español de DAMADokument99 SeitenResumen en Español de DAMAJosé Antonio AlonsoNoch keine Bewertungen
- Trabajo DBMSDokument27 SeitenTrabajo DBMSyrinamedinaNoch keine Bewertungen
- Tema 4Dokument52 SeitenTema 4Patricia CamposNoch keine Bewertungen
- Que Es OlapDokument32 SeitenQue Es OlapademianNoch keine Bewertungen
- A7 - Fasv - Proyecto Integrador2 - BDRDokument6 SeitenA7 - Fasv - Proyecto Integrador2 - BDRFre SerrNoch keine Bewertungen
- Examen Final - Semana 8 - INV - SEGUNDO BLOQUE-BASES DE DATOS - (GRUPO1)Dokument11 SeitenExamen Final - Semana 8 - INV - SEGUNDO BLOQUE-BASES DE DATOS - (GRUPO1)Bryan TinocoNoch keine Bewertungen
- Introduccion A Las Bases de DatosDokument34 SeitenIntroduccion A Las Bases de DatosEdgar RestrepoNoch keine Bewertungen
- Modelo - RelacionalDokument42 SeitenModelo - RelacionalJorge RamosNoch keine Bewertungen
- Plan de Aula HTML CSS AlgoritmiaDokument16 SeitenPlan de Aula HTML CSS AlgoritmiaSebastián Afanador FontalNoch keine Bewertungen
- Proyecto de Programación DigitalDokument3 SeitenProyecto de Programación DigitalJesus RojasNoch keine Bewertungen
- Tema 2 BBDD Apuntes para Examen Recu-1Dokument9 SeitenTema 2 BBDD Apuntes para Examen Recu-1Lorena OlayNoch keine Bewertungen
- Cuál Afirmación Es Correspondiente A Un Modelo RelacionalDokument5 SeitenCuál Afirmación Es Correspondiente A Un Modelo RelacionalDAVID MUSICNoch keine Bewertungen
- Ventajas y Desventajas de La Selección de Datos (Di Mar)Dokument7 SeitenVentajas y Desventajas de La Selección de Datos (Di Mar)Yisus99 Gameplay stickNoch keine Bewertungen
- Ejercicios de Álgebra RelacionalDokument0 SeitenEjercicios de Álgebra RelacionalLuis Amaro Villanueva TapiaNoch keine Bewertungen
- Tema19.modelos de Datos RelacionalDokument5 SeitenTema19.modelos de Datos Relacionalvickyalzate11Noch keine Bewertungen
- Manual Practicas C#Dokument86 SeitenManual Practicas C#Sheda17100% (9)
- Solucion Guía Base de DatosDokument11 SeitenSolucion Guía Base de DatosBrayan Camilo MillanNoch keine Bewertungen
- Introduccion BDDokument24 SeitenIntroduccion BDAnthonyMurilloRiveraNoch keine Bewertungen
- Acceso a Microsoft Access XPDokument37 SeitenAcceso a Microsoft Access XPKimberly HoustonNoch keine Bewertungen
- Guia Aprendizaje 3Dokument17 SeitenGuia Aprendizaje 3TrevorSoft0% (2)
- Taller de Base de Datos PDFDokument10 SeitenTaller de Base de Datos PDFLupita AmézquitaNoch keine Bewertungen
- Lab 2 Algebra Relacional Northwind - V4Dokument10 SeitenLab 2 Algebra Relacional Northwind - V4Alonso Javier LizaolaNoch keine Bewertungen
- Clase 02 - Bases de DatosDokument52 SeitenClase 02 - Bases de DatosSilvia RodriguezNoch keine Bewertungen
- Cómo Instalar Oracle Database 10g Release 2Dokument25 SeitenCómo Instalar Oracle Database 10g Release 2Luis SerranoNoch keine Bewertungen
- Lectura Fundamental 2Dokument11 SeitenLectura Fundamental 2Sergio MendozaNoch keine Bewertungen
- Tarea Sistema de Gestión de Base de DatosDokument7 SeitenTarea Sistema de Gestión de Base de DatosIsrael Canale TapiaNoch keine Bewertungen
- Experiencia Aprendizaje 2Dokument64 SeitenExperiencia Aprendizaje 2FERNANDA ANTONIA PÉREZNoch keine Bewertungen