Das könnte Ihnen auch gefallen
- DB2 9 for z/OS Database Administration: Certification Study GuideVon EverandDB2 9 for z/OS Database Administration: Certification Study GuideNoch keine Bewertungen
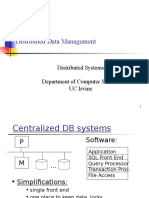
- Distributed DBDokument146 SeitenDistributed DBAnonymous jLw94L1SNoch keine Bewertungen
- Enterprise Systems: Distributed Databases and Systems - DT211 4Dokument25 SeitenEnterprise Systems: Distributed Databases and Systems - DT211 4Stef ShiNoch keine Bewertungen
- DDB SlidesDokument67 SeitenDDB SlidesyNoch keine Bewertungen
- Distributed Database ConceptsDokument52 SeitenDistributed Database ConceptsJoel wakhunguNoch keine Bewertungen
- FinalDokument46 SeitenFinalVinod KumarNoch keine Bewertungen
- Basis For Distributed Database TechnologyDokument35 SeitenBasis For Distributed Database Technologyashraf8Noch keine Bewertungen
- ch6 Distributed DatabaseDokument35 Seitench6 Distributed DatabaseDawit AbNoch keine Bewertungen
- Lecture1a DistSystDokument19 SeitenLecture1a DistSystDeepesh MeenaNoch keine Bewertungen
- Advanced Database Techniques-FDokument114 SeitenAdvanced Database Techniques-Fsneha555Noch keine Bewertungen
- Basis For Distributed Database TechnologyDokument35 SeitenBasis For Distributed Database TechnologyRavali SrirangamNoch keine Bewertungen
- Distributed DatabasesDokument20 SeitenDistributed DatabasesMarefia BirhanuNoch keine Bewertungen
- Introduction To DBMSDokument37 SeitenIntroduction To DBMSKIRUTHIKA KNoch keine Bewertungen
- Chapter 7 - Distributed Database SystemDokument27 SeitenChapter 7 - Distributed Database Systemajmelcosc0340Noch keine Bewertungen
- New Microsoft Word DocumentDokument14 SeitenNew Microsoft Word Documentanji_ieteNoch keine Bewertungen
- Chapter - 7 Distributed Database SystemDokument58 SeitenChapter - 7 Distributed Database SystemdawodNoch keine Bewertungen
- Introduction of DSDokument41 SeitenIntroduction of DSHarsh NebhwaniNoch keine Bewertungen
- ADBMS Parallel and Distributed DatabasesDokument98 SeitenADBMS Parallel and Distributed DatabasesTulipNoch keine Bewertungen
- Distributed Database ConceptDokument18 SeitenDistributed Database ConceptFouziya AnsariNoch keine Bewertungen
- 26 Distributed Dbms NosqlDokument45 Seiten26 Distributed Dbms NosqlJam MuslimNoch keine Bewertungen
- Data Communication Basics CH 7Dokument27 SeitenData Communication Basics CH 7Ukasha MohammednurNoch keine Bewertungen
- Week 02Dokument115 SeitenWeek 02muhammad shoaibNoch keine Bewertungen
- Database MC ADokument16 SeitenDatabase MC AMaheswari MNoch keine Bewertungen
- Parallel Database: Architecture For Parallel Databases. Parallel Query Evaluation Parallelizing Individual OperationsDokument27 SeitenParallel Database: Architecture For Parallel Databases. Parallel Query Evaluation Parallelizing Individual OperationsCarNoch keine Bewertungen
- Chapter 6Dokument45 SeitenChapter 6ramuarulmuruganNoch keine Bewertungen
- 1 Distributed DBDokument67 Seiten1 Distributed DBShreeharsha SNoch keine Bewertungen
- Introduction To Big DataDokument30 SeitenIntroduction To Big DatasameerwadkarNoch keine Bewertungen
- Chapter - 7 Distributed Database SystemDokument54 SeitenChapter - 7 Distributed Database SystemdawodyimerNoch keine Bewertungen
- Lecture 1 Parallel DatabasesDokument30 SeitenLecture 1 Parallel DatabasesKumkumo Kussia KossaNoch keine Bewertungen
- Database System ArchitectureDokument21 SeitenDatabase System ArchitectureDev BabbarNoch keine Bewertungen
- Lecture 1 Introduction To Distributed Systems - 034922Dokument6 SeitenLecture 1 Introduction To Distributed Systems - 034922leonardkigen100Noch keine Bewertungen
- Distributed DBMS ArchitectureDokument49 SeitenDistributed DBMS ArchitectureMahboobNoch keine Bewertungen
- Lecture 2 DbmsDokument26 SeitenLecture 2 DbmsMohd AhadNoch keine Bewertungen
- Mapping The Data Warehouse Architecture To Multiprocessor ArchitectureDokument15 SeitenMapping The Data Warehouse Architecture To Multiprocessor ArchitectureS.Srinidhi sandoshkumarNoch keine Bewertungen
- Lecture 2 Distributed and Parallel Computing CSE423Dokument23 SeitenLecture 2 Distributed and Parallel Computing CSE423ZeyRoX GamingNoch keine Bewertungen
- Chapter 3Dokument40 SeitenChapter 3Kj BanalNoch keine Bewertungen
- IEC 312 - Distributed System SecurityDokument22 SeitenIEC 312 - Distributed System SecurityBhanu NaikNoch keine Bewertungen
- Distributed Database: SourceDokument19 SeitenDistributed Database: SourcePro rushoNoch keine Bewertungen
- Chap-02v2 Modified by PratitDokument61 SeitenChap-02v2 Modified by PratitHung VoNoch keine Bewertungen
- Chapter 1 - Definition of DSDokument50 SeitenChapter 1 - Definition of DSMohamedsultan AwolNoch keine Bewertungen
- 2 Dist Arch (Week 2) Week 3 6Dokument65 Seiten2 Dist Arch (Week 2) Week 3 6Muhammad Awais ShahNoch keine Bewertungen
- Lecture 1 DDS Continue. (Downloaded With 1stbrowser)Dokument32 SeitenLecture 1 DDS Continue. (Downloaded With 1stbrowser)mohsinNoch keine Bewertungen
- Big Data Storage ConceptsDokument31 SeitenBig Data Storage ConceptsraghdoooshNoch keine Bewertungen
- Lecture#02 FileSystemAndDBDokument39 SeitenLecture#02 FileSystemAndDBfarhan121921Noch keine Bewertungen
- AdbmsDokument70 SeitenAdbmsvarunendraNoch keine Bewertungen
- Microsoft Load Balancing and ClusteringDokument23 SeitenMicrosoft Load Balancing and ClusteringRamana KadiyalaNoch keine Bewertungen
- A Distributed Database Management System ('DDBMS') Is A Software SystemDokument5 SeitenA Distributed Database Management System ('DDBMS') Is A Software Systempisces145Noch keine Bewertungen
- Tybca Recent Trends in It Chpter 1Dokument16 SeitenTybca Recent Trends in It Chpter 1aishwarya sajiNoch keine Bewertungen
- Three-Tier Architecture: Manuel Corona David NevarezDokument59 SeitenThree-Tier Architecture: Manuel Corona David Nevarezrakesh_cs_jsrNoch keine Bewertungen
- Distributed Database: Database Storage Devices CPU Database Management System Computers NetworkDokument9 SeitenDistributed Database: Database Storage Devices CPU Database Management System Computers NetworkSankari SoniNoch keine Bewertungen
- BDL8 PDFDokument41 SeitenBDL8 PDFMrs. Usha Naidu SNoch keine Bewertungen
- DS Syllabus Introduction (Reference)Dokument44 SeitenDS Syllabus Introduction (Reference)Joel ShibbiNoch keine Bewertungen
- IDDBMSDokument6 SeitenIDDBMSVictor SarmacharjeeNoch keine Bewertungen
- Unit - I Distributed Data ProcessingDokument27 SeitenUnit - I Distributed Data ProcessingHarsha VardhanNoch keine Bewertungen
- Introduction To Distributed Systems: Brian Nielsen Bnielsen@cs - Aau.dk Bnielsen@cs - Aau.dkDokument54 SeitenIntroduction To Distributed Systems: Brian Nielsen Bnielsen@cs - Aau.dk Bnielsen@cs - Aau.dkIhab AmerNoch keine Bewertungen
- Parallel DatabaseDokument22 SeitenParallel DatabaseSameer MemonNoch keine Bewertungen
- Distributed Systems: Tanenbaum Chapter 1Dokument70 SeitenDistributed Systems: Tanenbaum Chapter 1Kassawmar AyalewNoch keine Bewertungen
- Overview of Data WarehousingDokument62 SeitenOverview of Data WarehousingSushil KulkarniNoch keine Bewertungen
- Cluster Analysis in Data MininingDokument56 SeitenCluster Analysis in Data MininingSushil Kulkarni100% (6)
- Classification Algorithms Used in Data Mining. This Is A Lecture Given To MSC Students.Dokument63 SeitenClassification Algorithms Used in Data Mining. This Is A Lecture Given To MSC Students.Sushil Kulkarni100% (5)
- Social Networks and Data MiningDokument81 SeitenSocial Networks and Data MiningSushil Kulkarni100% (21)
- Object Database SystemDokument78 SeitenObject Database SystemSushil Kulkarni100% (5)
- JDSU Setup For CSV ExportDokument19 SeitenJDSU Setup For CSV ExportSri NivasNoch keine Bewertungen
- SQL Interview Questions (2021) - JavatpointDokument34 SeitenSQL Interview Questions (2021) - JavatpointChandan GowdaNoch keine Bewertungen
- Syllabus RGPVDokument5 SeitenSyllabus RGPVकिशोरी जूNoch keine Bewertungen
- Blueprism QuestionsDokument24 SeitenBlueprism Questionsdhivya2451989Noch keine Bewertungen
- Tesseract Training - For Khmer Language - For PostingDokument8 SeitenTesseract Training - For Khmer Language - For PostingKruy Vanna100% (3)
- msp430F1611 PDFDokument67 Seitenmsp430F1611 PDFTrần Mạnh HùngNoch keine Bewertungen
- FPREADMEDokument3 SeitenFPREADMEkemetvictNoch keine Bewertungen
- 7.3.2.10 Lab - Research Laptop DrivesDokument2 Seiten7.3.2.10 Lab - Research Laptop Drivesyoudy012Noch keine Bewertungen
- 2017-18 A CC4002NA A3 CW Coursework NP01CP4A170082 Dibya ShresthaDokument47 Seiten2017-18 A CC4002NA A3 CW Coursework NP01CP4A170082 Dibya ShresthahazelNoch keine Bewertungen
- Modscan32 ManualDokument93 SeitenModscan32 ManualAlberto Marsico100% (2)
- LogDokument41 SeitenLogYunita Yulia PutriNoch keine Bewertungen
- Mongodb TutorialDokument106 SeitenMongodb TutorialRahul VashishthaNoch keine Bewertungen
- Practice Problems For Chapter 5-SolDokument5 SeitenPractice Problems For Chapter 5-SolAckeema JohnsonNoch keine Bewertungen
- 2.3 Pulse Code ModulationDokument40 Seiten2.3 Pulse Code ModulationfurqanNoch keine Bewertungen
- Oracle Tips and Techniques 132894Dokument48 SeitenOracle Tips and Techniques 132894Tarun KumarNoch keine Bewertungen
- Computer Book MaterialDokument69 SeitenComputer Book MaterialAqib Asad100% (1)
- UNIT-II IIoTDokument35 SeitenUNIT-II IIoTRama Rao MannamNoch keine Bewertungen
- MP3 - WikipediaDokument18 SeitenMP3 - WikipediaBelhamidi Mohammed HoussameNoch keine Bewertungen
- Database ReportDokument20 SeitenDatabase ReportdeepakNoch keine Bewertungen
- FacHouse Error LogDokument532 SeitenFacHouse Error Logarchangel571Noch keine Bewertungen
- How To Launch and Connect To An Amazon RDS DB Instance: Follow These Steps To Learn by Building Helpful Cloud ResourcesDokument25 SeitenHow To Launch and Connect To An Amazon RDS DB Instance: Follow These Steps To Learn by Building Helpful Cloud ResourcesAndres BustosNoch keine Bewertungen
- Zyxel Cli Reference Guide Nwa1123 Acv2 5Dokument167 SeitenZyxel Cli Reference Guide Nwa1123 Acv2 5kim phuNoch keine Bewertungen
- Interview Questions With Answers SQL - V1.0Dokument5 SeitenInterview Questions With Answers SQL - V1.0Parampreet KaurNoch keine Bewertungen
- SAP HANA Interview QuestionsDokument17 SeitenSAP HANA Interview QuestionsShivani DeshmukhNoch keine Bewertungen
- CICS Transaction Server 4v2Dokument838 SeitenCICS Transaction Server 4v2usersupreethNoch keine Bewertungen
- Encoding Techniques and CodecDokument7 SeitenEncoding Techniques and CodecPeter ChimanziNoch keine Bewertungen
- AWS Data LakeDokument104 SeitenAWS Data Lakechatgpt100% (1)
- 01 - SAP Data Transfer Made EasyDokument13 Seiten01 - SAP Data Transfer Made Easylluizfellipe0% (1)
- Master of Science-Computer Science-SyllabusDokument22 SeitenMaster of Science-Computer Science-SyllabusManish MittalNoch keine Bewertungen
- Ingersoll Rand System Automation X8I Modbus Rtu User's ManualDokument138 SeitenIngersoll Rand System Automation X8I Modbus Rtu User's ManualDavid HernándezNoch keine Bewertungen