Das könnte Ihnen auch gefallen
- Internet Technologies Handbook: Optimizing the IP NetworkVon EverandInternet Technologies Handbook: Optimizing the IP NetworkNoch keine Bewertungen
- Confident Programmer Debugging Guide: Confident ProgrammerVon EverandConfident Programmer Debugging Guide: Confident ProgrammerNoch keine Bewertungen
- SC WD19 Eom3-1 Nbmnisi 2Dokument3 SeitenSC WD19 Eom3-1 Nbmnisi 2Njabulo MnisiNoch keine Bewertungen
- Are Convenience and Rewards Leading To A Digital Flashpoint?Dokument8 SeitenAre Convenience and Rewards Leading To A Digital Flashpoint?Nigin G KariattNoch keine Bewertungen
- Creating Virtual MachineDokument40 SeitenCreating Virtual MachineMangesh AbnaveNoch keine Bewertungen
- Ethereum Classic ROADMAPDokument25 SeitenEthereum Classic ROADMAPIgor ArtamonovNoch keine Bewertungen
- FemmeHacks Infopack - Print 100Dokument14 SeitenFemmeHacks Infopack - Print 100StephanieNoch keine Bewertungen
- Mobile App TestingDokument26 SeitenMobile App Testingwajid syed100% (1)
- The Worst Mobile Apps: Def Con 28Dokument69 SeitenThe Worst Mobile Apps: Def Con 28Hira AftabNoch keine Bewertungen
- HTML Website ProjectDokument30 SeitenHTML Website ProjectSiddesh Dhauskar100% (1)
- Start: About AnfeidrolDokument4 SeitenStart: About AnfeidrolHarshNoch keine Bewertungen
- Linux Fundamentals: Chapter 1: Introduction To LinuxDokument27 SeitenLinux Fundamentals: Chapter 1: Introduction To Linuxdyake04Noch keine Bewertungen
- Classified The Contents: Deep Web Dark WebDokument5 SeitenClassified The Contents: Deep Web Dark WebCorina A.Noch keine Bewertungen
- GoogleSecrets TipsTricks PDFDokument75 SeitenGoogleSecrets TipsTricks PDFELHYMER YOUSSEFNoch keine Bewertungen
- Formal Verification of SmartcontractsDokument6 SeitenFormal Verification of SmartcontractsSlashdev SlashnullNoch keine Bewertungen
- GitHub - Dhanukarajat - Car-Rental - Online Car Rental System Using MySQL and PHPDokument2 SeitenGitHub - Dhanukarajat - Car-Rental - Online Car Rental System Using MySQL and PHPdesta tekluNoch keine Bewertungen
- Web Crawler A SurveyDokument3 SeitenWeb Crawler A SurveyInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Path - Web Developers - OpenClassroomsDokument15 SeitenPath - Web Developers - OpenClassroomsJahangir Alom Minto0% (1)
- PM Interview Prep Guide 2019 PDFDokument8 SeitenPM Interview Prep Guide 2019 PDFyang2qwe1601Noch keine Bewertungen
- Web Browser SecurityDokument16 SeitenWeb Browser Securityعبدالرحيم اودين0% (1)
- Top 18 Database Projects Ideas For Students Lovelycoding - OrgDokument11 SeitenTop 18 Database Projects Ideas For Students Lovelycoding - OrgalbaniaNoch keine Bewertungen
- Day06 FootprintingDokument34 SeitenDay06 FootprintingRafael ThemístoclesNoch keine Bewertungen
- Club Hack Magazine 35 PDFDokument31 SeitenClub Hack Magazine 35 PDFLeonardo Herrera RomeroNoch keine Bewertungen
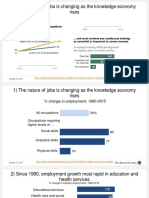
- 1) The Nature of Jobs Is Changing As The Knowledge Economy RisesDokument16 Seiten1) The Nature of Jobs Is Changing As The Knowledge Economy Risesmeh3reNoch keine Bewertungen
- The Oracle Problem - Victor Hogrefe - MediumDokument15 SeitenThe Oracle Problem - Victor Hogrefe - MediumVikrant ManseraNoch keine Bewertungen
- The Nation.: Why Wikileaks MattersDokument4 SeitenThe Nation.: Why Wikileaks MattersMaría José CalderónNoch keine Bewertungen
- Sqlmap - Security Development in PythonDokument53 SeitenSqlmap - Security Development in Pythonmiroslav_stamparNoch keine Bewertungen
- A Blog Network Is A Group of Blogs That Are Connected To Each Other in A NetworkDokument332 SeitenA Blog Network Is A Group of Blogs That Are Connected To Each Other in A NetworkMkgt HemaautomationNoch keine Bewertungen
- Dropbox CIMDokument28 SeitenDropbox CIMHiral SavlaNoch keine Bewertungen
- DoorDash Merchant Portal Step-By-Step GuideDokument86 SeitenDoorDash Merchant Portal Step-By-Step GuideTruc LeNoch keine Bewertungen
- Reporte VerizonDokument105 SeitenReporte VerizonTrabajo HondurasNoch keine Bewertungen
- What Is Open Banking and What Does It EntailDokument3 SeitenWhat Is Open Banking and What Does It EntailSuntec SNoch keine Bewertungen
- Web OrgnizationDokument19 SeitenWeb Orgnizationم. سهير عبد داؤد عسىNoch keine Bewertungen
- 4.1 Understanding SudoDokument14 Seiten4.1 Understanding Sudogidum2007Noch keine Bewertungen
- APPLEDokument8 SeitenAPPLEIsrael Sodium JobNoch keine Bewertungen
- Location SIG 10.5.12 Nicolas Graube CSRDokument12 SeitenLocation SIG 10.5.12 Nicolas Graube CSRRiddhi SharmaNoch keine Bewertungen
- Malware Injection FAQ GSDokument34 SeitenMalware Injection FAQ GSTheGuroidNoch keine Bewertungen
- Free and Open Source SoftwareDokument31 SeitenFree and Open Source Softwaremoin321Noch keine Bewertungen
- Digital Capability Framework Overview 3Dokument9 SeitenDigital Capability Framework Overview 3Kieran O'HeaNoch keine Bewertungen
- For Feedback or Requests DM Me On Twitter @litteeenDokument43 SeitenFor Feedback or Requests DM Me On Twitter @litteeenChristianChávezRodríguezNoch keine Bewertungen
- Virtual Machine Setup GuideDokument7 SeitenVirtual Machine Setup Guidesrituraj17Noch keine Bewertungen
- Ecommerce NotesDokument53 SeitenEcommerce NotesfarisktsNoch keine Bewertungen
- Using OSINT To Investigate School ShootersDokument33 SeitenUsing OSINT To Investigate School ShootersojanathottoNoch keine Bewertungen
- Lilee PTC GuideDokument19 SeitenLilee PTC GuideklodenceNoch keine Bewertungen
- How The Internet WorksDokument23 SeitenHow The Internet WorksAristotle Manicane GabonNoch keine Bewertungen
- Social Networking ServiceDokument59 SeitenSocial Networking ServiceEdmond Dantès100% (1)
- Flipboard App Case StudyDokument16 SeitenFlipboard App Case StudyDan Camargo100% (1)
- Enterprise Mobility Management With Android For WorkDokument126 SeitenEnterprise Mobility Management With Android For WorkRym HAJINNoch keine Bewertungen
- How To Create A Wordpress ThemeDokument13 SeitenHow To Create A Wordpress ThemesameerroushanNoch keine Bewertungen
- Android O.S. IndexDokument19 SeitenAndroid O.S. IndexrahulNoch keine Bewertungen
- Dark Abyssal Side of Web: Mentor:-Rohit Kumar SinghDokument4 SeitenDark Abyssal Side of Web: Mentor:-Rohit Kumar SinghRohan VishwakarmaNoch keine Bewertungen
- Smart Homes-Based On Mobile IPDokument4 SeitenSmart Homes-Based On Mobile IPEditor IJRITCC100% (1)
- Usability Considerations in Website DesignDokument27 SeitenUsability Considerations in Website DesignJeffrey GoldNoch keine Bewertungen
- Best of Mobile Pos 2014 PDFDokument127 SeitenBest of Mobile Pos 2014 PDFAndalynaNoch keine Bewertungen
- Google Apps Stirs Governm: Hews AnDokument2 SeitenGoogle Apps Stirs Governm: Hews AnajaxorNoch keine Bewertungen
- Digital Identity Role in Optimizing Customer Experience and Competitive AdvantageDokument12 SeitenDigital Identity Role in Optimizing Customer Experience and Competitive AdvantagenghiadtNoch keine Bewertungen
- The Top 100 Sites For Job Hunting On The WebDokument5 SeitenThe Top 100 Sites For Job Hunting On The WebKent WhiteNoch keine Bewertungen
- Physical and Logical TopologiesDokument10 SeitenPhysical and Logical TopologiesBibinMathew100% (1)
- Operating System Security - Paul Hopkins, CGIDokument8 SeitenOperating System Security - Paul Hopkins, CGISidharth MalhotraNoch keine Bewertungen
- Upravni postupakScreen-reader users, click here to turn off Google Instant. WebImagesNewsVideosMoreSearch tools About 21,500 results (0.51 seconds) Including results for komentar zakona o upravnom postupku bih Search only for komentar zakona o upravnom postupku fbih Search Results [PDF] Kompletna elektronska verzija - Sveučilište / Univerzitet VITEZ unvi.edu.ba/Files/zbornici/4zbornik_radova_fpn.pdf Zakon o upravnom postupku Bosne i Hercegovine (Službeni glasnik BiH, br. ... 12 Dr. Pero Krijan, Komentar Zakona o upravnom postupku Federacije BiH, ... Knjiga Final - Scribd sr.scribd.com/doc/93508671/Knjiga-Final KOMENTAR ZAKONA O UPRAVNOM POSTUPKU FEDERACIJE BOSNE I ... Nikoli}, diplomirani pravnik, pomo}nik ombudsmena Federacije BiH Suada Nini}, ... Da li neko od kolega ima komentar zakona o upravnom ... www.pravobih.com › Indeks › PravoBiH Forum › Ispiti Translate this page May 24, 2010 - P.S. Ukoliko nekome treba komentar zakona o izvrsnom postupku (takodjer u ... Postovanje kolega,Dokument3 SeitenUpravni postupakScreen-reader users, click here to turn off Google Instant. WebImagesNewsVideosMoreSearch tools About 21,500 results (0.51 seconds) Including results for komentar zakona o upravnom postupku bih Search only for komentar zakona o upravnom postupku fbih Search Results [PDF] Kompletna elektronska verzija - Sveučilište / Univerzitet VITEZ unvi.edu.ba/Files/zbornici/4zbornik_radova_fpn.pdf Zakon o upravnom postupku Bosne i Hercegovine (Službeni glasnik BiH, br. ... 12 Dr. Pero Krijan, Komentar Zakona o upravnom postupku Federacije BiH, ... Knjiga Final - Scribd sr.scribd.com/doc/93508671/Knjiga-Final KOMENTAR ZAKONA O UPRAVNOM POSTUPKU FEDERACIJE BOSNE I ... Nikoli}, diplomirani pravnik, pomo}nik ombudsmena Federacije BiH Suada Nini}, ... Da li neko od kolega ima komentar zakona o upravnom ... www.pravobih.com › Indeks › PravoBiH Forum › Ispiti Translate this page May 24, 2010 - P.S. Ukoliko nekome treba komentar zakona o izvrsnom postupku (takodjer u ... Postovanje kolega,Goran VukadinovicNoch keine Bewertungen
- SEMrush-Full Site Audit Report1Dokument17 SeitenSEMrush-Full Site Audit Report1Tarteil TradingNoch keine Bewertungen
- Terminal TackleDokument160 SeitenTerminal TackleStart AmazonNoch keine Bewertungen
- Seo ToolsDokument7 SeitenSeo ToolsHasnain RajaNoch keine Bewertungen
- Q2-W2 QuizDokument3 SeitenQ2-W2 QuizcelinaNoch keine Bewertungen
- Basic & Advanced SEO Course SyllabusDokument8 SeitenBasic & Advanced SEO Course SyllabusdmtrainingNoch keine Bewertungen
- Amplificador Akai A1125Dokument51 SeitenAmplificador Akai A1125Josue Hernandez GutierrezNoch keine Bewertungen
- SEO-Proposal SampleDokument2 SeitenSEO-Proposal Samplekishan patel33% (3)
- Ecommerce SEO GuideDokument153 SeitenEcommerce SEO GuideAnonymous F5vEVhu1ZNoch keine Bewertungen
- Vn800 Service ManualDokument405 SeitenVn800 Service ManualDiego MachadoNoch keine Bewertungen
- Moiz Sharif: About MeDokument2 SeitenMoiz Sharif: About MevServices Video AnimationNoch keine Bewertungen
- Keyword Research Cheat SheetDokument2 SeitenKeyword Research Cheat SheetDovlaNoch keine Bewertungen
- Deutz Manual bf4m1012Dokument490 SeitenDeutz Manual bf4m1012Elvis Astorayme GalvezNoch keine Bewertungen
- Profile Links: WebsitesDokument8 SeitenProfile Links: WebsitesJibran AyubNoch keine Bewertungen
- An Internship Presentation On Search Engine Optimization at Saayami TechnologyDokument28 SeitenAn Internship Presentation On Search Engine Optimization at Saayami TechnologyDipesh TripathiNoch keine Bewertungen
- SEO Report TemplateDokument6 SeitenSEO Report TemplateAllan Charles BradburyNoch keine Bewertungen
- Singer 518 StylistDokument76 SeitenSinger 518 StylisttanjamicroNoch keine Bewertungen
- SEO Cheat SheetDokument5 SeitenSEO Cheat SheetAdidasNoch keine Bewertungen
- All in One Designer SEO HandbookDokument18 SeitenAll in One Designer SEO HandbookJawanNoch keine Bewertungen
- Mario Brown Seo TakeoverDokument17 SeitenMario Brown Seo TakeoverMagenta HagemiNoch keine Bewertungen
- SEO Skill Assessment Fiverr Test 1Dokument11 SeitenSEO Skill Assessment Fiverr Test 1M A Masud RanaNoch keine Bewertungen
- Curso de Yoga Online: Pripriedade Keyword URLDokument1 SeiteCurso de Yoga Online: Pripriedade Keyword URLAlberto FonsecaNoch keine Bewertungen
- Downloaded From Manuals Search EngineDokument58 SeitenDownloaded From Manuals Search EngineLuis OlivaNoch keine Bewertungen
- Top 15 Most Popular News WebsitesDokument2 SeitenTop 15 Most Popular News WebsitesjavedNoch keine Bewertungen
- SEMrush-Domain Overview (Desktop) - Aighospitals Com-1st Sep 2022Dokument8 SeitenSEMrush-Domain Overview (Desktop) - Aighospitals Com-1st Sep 2022Huzurabad With KCRNoch keine Bewertungen
- SEO WorkbookDokument155 SeitenSEO Workbookchukwunonsodavid248Noch keine Bewertungen
- What's The Difference Between Google and Yahoo?Dokument26 SeitenWhat's The Difference Between Google and Yahoo?TomNoch keine Bewertungen
- Introduction To Search Engine OptimizationDokument31 SeitenIntroduction To Search Engine OptimizationPratik PatilNoch keine Bewertungen
- The Definitive Guide To Google My Business SEO by Mark AttwoodDokument43 SeitenThe Definitive Guide To Google My Business SEO by Mark Attwood2010odontologia7949100% (2)
- Top 10 PDF Submission Sites 2020 PDFDokument7 SeitenTop 10 PDF Submission Sites 2020 PDFWaheed GullNoch keine Bewertungen



























































![Upravni postupakScreen-reader users, click here to turn off Google Instant. WebImagesNewsVideosMoreSearch tools About 21,500 results (0.51 seconds) Including results for komentar zakona o upravnom postupku bih Search only for komentar zakona o upravnom postupku fbih Search Results [PDF] Kompletna elektronska verzija - Sveučilište / Univerzitet VITEZ unvi.edu.ba/Files/zbornici/4zbornik_radova_fpn.pdf Zakon o upravnom postupku Bosne i Hercegovine (Službeni glasnik BiH, br. ... 12 Dr. Pero Krijan, Komentar Zakona o upravnom postupku Federacije BiH, ... Knjiga Final - Scribd sr.scribd.com/doc/93508671/Knjiga-Final KOMENTAR ZAKONA O UPRAVNOM POSTUPKU FEDERACIJE BOSNE I ... Nikoli}, diplomirani pravnik, pomo}nik ombudsmena Federacije BiH Suada Nini}, ... Da li neko od kolega ima komentar zakona o upravnom ... www.pravobih.com › Indeks › PravoBiH Forum › Ispiti Translate this page May 24, 2010 - P.S. Ukoliko nekome treba komentar zakona o izvrsnom postupku (takodjer u ... Postovanje kolega,](https://imgv2-1-f.scribdassets.com/img/document/233079085/149x198/7c754c9457/1545296929?v=1)