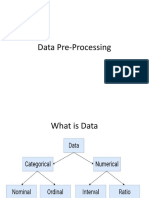
Das könnte Ihnen auch gefallen
- Sop DBA AjayDokument76 SeitenSop DBA Ajayganesh100% (1)
- Data Strategy TemplateDokument18 SeitenData Strategy TemplateGuillermo Solis50% (2)
- Chapter 3 - Data Pre-Processing NotesDokument8 SeitenChapter 3 - Data Pre-Processing Notestowsif.imran.dhkNoch keine Bewertungen
- Data Pre-Processing: Submitted By, R.Archana, 10ucs05 D.Gayathri, 10ucs11Dokument18 SeitenData Pre-Processing: Submitted By, R.Archana, 10ucs05 D.Gayathri, 10ucs11subithaperiyasamyNoch keine Bewertungen
- CIS664-Knowledge Discovery and Data MiningDokument52 SeitenCIS664-Knowledge Discovery and Data MiningAkbar KushanoorNoch keine Bewertungen
- DM 2Dokument41 SeitenDM 2Aditya SrivastavaNoch keine Bewertungen
- PreprocessingDokument62 SeitenPreprocessingpoi.tamrakarNoch keine Bewertungen
- PreprocessingDokument13 SeitenPreprocessingmba20238Noch keine Bewertungen
- 03-Data Preprocessing 2021Dokument33 Seiten03-Data Preprocessing 2021Lakshmi Priya BNoch keine Bewertungen
- 20210913115526D3708 - Session 02-04 Getting To Know Your Data Data Pre-ProcessingDokument64 Seiten20210913115526D3708 - Session 02-04 Getting To Know Your Data Data Pre-ProcessingAnthony HarjantoNoch keine Bewertungen
- Spatial and Temporal Data MiningDokument52 SeitenSpatial and Temporal Data Miningamanpcte07Noch keine Bewertungen
- Romi DM 03 Persiapan Mar2016Dokument82 SeitenRomi DM 03 Persiapan Mar2016Tri Indah SariNoch keine Bewertungen
- 3 Data PreprocessingDokument33 Seiten3 Data PreprocessingMarcoNoch keine Bewertungen
- Dwina DM 03 Persiapan 2018Dokument82 SeitenDwina DM 03 Persiapan 2018Hanny Febrii ElizabethNoch keine Bewertungen
- 3 Persiapan Data MiningDokument83 Seiten3 Persiapan Data Miningicobes urNoch keine Bewertungen
- Data Pre-Processing: - Data Cleaning - Data Integration - Data Transformation - Data Reduction - Data DiscretizationDokument55 SeitenData Pre-Processing: - Data Cleaning - Data Integration - Data Transformation - Data Reduction - Data DiscretizationChanda TestNoch keine Bewertungen
- Week 4 - 5 - Data PreprocessingDokument67 SeitenWeek 4 - 5 - Data PreprocessingHussain ASLNoch keine Bewertungen
- Pre ProcessingDokument60 SeitenPre Processingvani_V_prakashNoch keine Bewertungen
- 3 RaviDokument82 Seiten3 RaviKrishna ChauhanNoch keine Bewertungen
- 03 PreprocessingDokument42 Seiten03 Preprocessinghawariya abelNoch keine Bewertungen
- Agenda: - Why Data Preprocessing?Dokument51 SeitenAgenda: - Why Data Preprocessing?Lakshmi PrashanthNoch keine Bewertungen
- Data Preprocessing Part 1Dokument14 SeitenData Preprocessing Part 1new acc jeetNoch keine Bewertungen
- DATA MINING Chapter 1 and 2 Lect SlideDokument47 SeitenDATA MINING Chapter 1 and 2 Lect SlideSanjeev ThakurNoch keine Bewertungen
- Knowledge Discovery and Data MiningDokument55 SeitenKnowledge Discovery and Data MiningRupesh VNoch keine Bewertungen
- Data Preprocessing: Lecturer: Dr. Nguyen Thi Ngoc AnhDokument39 SeitenData Preprocessing: Lecturer: Dr. Nguyen Thi Ngoc AnhTam KiếmNoch keine Bewertungen
- Introduction Unit - Summary: Data MiningDokument62 SeitenIntroduction Unit - Summary: Data MiningMeetNoch keine Bewertungen
- Data IntegrationDokument31 SeitenData IntegrationTanish SaajanNoch keine Bewertungen
- Data and DW Lab Manual UpdatedDokument44 SeitenData and DW Lab Manual UpdatedVineet AggarwalNoch keine Bewertungen
- Dat Collection FoundationDokument24 SeitenDat Collection FoundationLOICE HAZVINEI KUMIRENoch keine Bewertungen
- Session2 ShortDokument196 SeitenSession2 ShortChristina FingtonNoch keine Bewertungen
- Data PreprocessingDokument77 SeitenData Preprocessing20bme094Noch keine Bewertungen
- Unit 2Dokument30 SeitenUnit 2Dakshkohli31 KohliNoch keine Bewertungen
- Syllabus: Data Warehousing and Data MiningDokument18 SeitenSyllabus: Data Warehousing and Data MiningIt's MeNoch keine Bewertungen
- Bab 3 Data Preprocessing: Arif DjunaidyDokument54 SeitenBab 3 Data Preprocessing: Arif DjunaidyMochammad Adji FirmansyahNoch keine Bewertungen
- Data MiningDokument7 SeitenData MiningManoNoch keine Bewertungen
- # Understanding DM IssuesDokument34 Seiten# Understanding DM IssuesDan MasangaNoch keine Bewertungen
- Notes - Unit01 - Data Science and Big Data AnalyticsDokument7 SeitenNotes - Unit01 - Data Science and Big Data AnalyticsAtharva GokhareNoch keine Bewertungen
- Data Science - Module 1.3Dokument34 SeitenData Science - Module 1.3Amisha ShettyNoch keine Bewertungen
- Intro To Data MinningDokument24 SeitenIntro To Data MinningAkshay MathurNoch keine Bewertungen
- Satyabhama BigdataDokument128 SeitenSatyabhama BigdataVijaya Kumar VadladiNoch keine Bewertungen
- DataPreprocessing 2Dokument68 SeitenDataPreprocessing 2Rehan KhalidNoch keine Bewertungen
- DATA MINING NotesDokument37 SeitenDATA MINING Notesblack smithNoch keine Bewertungen
- Data PreprocessingDokument33 SeitenData PreprocessingStephen PaulNoch keine Bewertungen
- Down 2Dokument61 SeitenDown 2pavunkumarNoch keine Bewertungen
- Data Preprocessing Part 4Dokument18 SeitenData Preprocessing Part 4new acc jeetNoch keine Bewertungen
- Unit 3 Data WarehouseDokument17 SeitenUnit 3 Data WarehouseVanshika ChauhanNoch keine Bewertungen
- M-Unit-2 R16Dokument21 SeitenM-Unit-2 R16JAGADISH MNoch keine Bewertungen
- Data PreprocessingDokument22 SeitenData PreprocessingPrashant SharmaNoch keine Bewertungen
- Assignment ShubhamDokument10 SeitenAssignment ShubhamShubham GuptaNoch keine Bewertungen
- DATA MINING Notes (Upate)Dokument25 SeitenDATA MINING Notes (Upate)black smithNoch keine Bewertungen
- Data BinningDokument9 SeitenData BinningNithish RajNoch keine Bewertungen
- CH 02 Data Preprocessing 2021Dokument47 SeitenCH 02 Data Preprocessing 2021PRIYA RATHORENoch keine Bewertungen
- Down 3Dokument129 SeitenDown 3pavunkumarNoch keine Bewertungen
- JAVA Advanced 3Dokument19 SeitenJAVA Advanced 3Lucky MahantoNoch keine Bewertungen
- CSC 3301-Lecture06 Introduction To Machine LearningDokument56 SeitenCSC 3301-Lecture06 Introduction To Machine LearningAmalienaHilmyNoch keine Bewertungen
- BECE352E Module 2Dokument58 SeitenBECE352E Module 2zistavodroNoch keine Bewertungen
- WINSEM2023-24 - BECE352E - ETH - VL2023240504409 - 2024-02-03 - Reference-Material-I 2Dokument16 SeitenWINSEM2023-24 - BECE352E - ETH - VL2023240504409 - 2024-02-03 - Reference-Material-I 2Aditya Bonnerjee 21BEC0384Noch keine Bewertungen
- Assignment 1: Aim: Preprocess Data Using Python. ObjectiveDokument7 SeitenAssignment 1: Aim: Preprocess Data Using Python. ObjectiveAbhinay SurveNoch keine Bewertungen
- DWM Unit-IDokument32 SeitenDWM Unit-IBabuRao GanpatRaoNoch keine Bewertungen
- Unit-Ii DW&DMDokument24 SeitenUnit-Ii DW&DMthe sinha'sNoch keine Bewertungen
- Term PaperDokument5 SeitenTerm PaperAkash SudanNoch keine Bewertungen
- Behavioral Patterns part-II Introduction Mediator Memento Observer State Strategy Template Method Visitor ReferenceDokument86 SeitenBehavioral Patterns part-II Introduction Mediator Memento Observer State Strategy Template Method Visitor ReferenceKarthik KompelliNoch keine Bewertungen
- DWDMDokument41 SeitenDWDMKarthik KompelliNoch keine Bewertungen
- Slides For Textbook - Chapter 7 - : March 6, 2014 Data Mining: Concepts and Techniques 1Dokument23 SeitenSlides For Textbook - Chapter 7 - : March 6, 2014 Data Mining: Concepts and Techniques 1Karthik KompelliNoch keine Bewertungen
- CH 4Dokument30 SeitenCH 4Karthik KompelliNoch keine Bewertungen
- A Spectral Color Imaging System For Estimating Spectral Reflectance of PaintDokument28 SeitenA Spectral Color Imaging System For Estimating Spectral Reflectance of PaintKarthik KompelliNoch keine Bewertungen
- TocDokument108 SeitenTocNaveen NagalingamNoch keine Bewertungen
- ID 2187539.1Dokument1 SeiteID 2187539.1jkgggvghNoch keine Bewertungen
- Postgresql Programmer'S Guide: The Postgresql Development TeamDokument331 SeitenPostgresql Programmer'S Guide: The Postgresql Development TeamArmin_Vera_Bec_5685Noch keine Bewertungen
- Management Information System Ch-6 Data Flow Diagrams: 0-Level DFDDokument6 SeitenManagement Information System Ch-6 Data Flow Diagrams: 0-Level DFDHamid BashirNoch keine Bewertungen
- HANA and AbapDokument11 SeitenHANA and AbapWaseem100% (1)
- Oracle Database 12c New Features For Administrators Ed 2 NEW - D77758GC20 - 1080544 - USDokument6 SeitenOracle Database 12c New Features For Administrators Ed 2 NEW - D77758GC20 - 1080544 - USJinendraabhiNoch keine Bewertungen
- Nosql DatawarehouseDokument11 SeitenNosql DatawarehouseGunjan chandwaniNoch keine Bewertungen
- Apache Nifi For Dummies EbookDokument72 SeitenApache Nifi For Dummies EbookHome SmartNoch keine Bewertungen
- Cia 1 Part BDokument29 SeitenCia 1 Part BSukhee SakthivelNoch keine Bewertungen
- Fusion SCM Professor Extensible Flexfields EffDokument11 SeitenFusion SCM Professor Extensible Flexfields Effapi-365943980Noch keine Bewertungen
- LMSWDokument15 SeitenLMSWHouda BoussettaNoch keine Bewertungen
- HRF - Design Document - V2.0Dokument33 SeitenHRF - Design Document - V2.0AbhilashMadalaNoch keine Bewertungen
- DbintfcDokument80 SeitenDbintfchnr.uninstallNoch keine Bewertungen
- AlGhushaimi. نهائي قواعد بيانات 2020Dokument9 SeitenAlGhushaimi. نهائي قواعد بيانات 2020Anas SadiqNoch keine Bewertungen
- Backing Up Your VIOS Configuration With ViosbrDokument9 SeitenBacking Up Your VIOS Configuration With ViosbrMainak DasNoch keine Bewertungen
- Compusoft, 2 (12), 396-399 PDFDokument4 SeitenCompusoft, 2 (12), 396-399 PDFIjact EditorNoch keine Bewertungen
- SQL NotesDokument18 SeitenSQL NotesBaljit KaurNoch keine Bewertungen
- XPath Extension FunctionsDokument69 SeitenXPath Extension FunctionsAlfaNoch keine Bewertungen
- Fundamentals of DBS - CH - 2Dokument28 SeitenFundamentals of DBS - CH - 2DesyilalNoch keine Bewertungen
- 20-1 - Upgrade From Oracle 12.2 To 19c With Container PluggableDokument38 Seiten20-1 - Upgrade From Oracle 12.2 To 19c With Container Pluggablemohammad zubairNoch keine Bewertungen
- IBM - Big Data AnalyticsDokument22 SeitenIBM - Big Data AnalyticsJohn AngelopoulosNoch keine Bewertungen
- Data Selection and Queries in ArcGISDokument10 SeitenData Selection and Queries in ArcGISMohamedAlaminNoch keine Bewertungen
- Introduction To Data Models: Dr. Jenila Livingston L.M. ScseDokument13 SeitenIntroduction To Data Models: Dr. Jenila Livingston L.M. Scsebhumika.verma00Noch keine Bewertungen
- DBMS MiniInstagram CE108 CE111 B 2Dokument12 SeitenDBMS MiniInstagram CE108 CE111 B 2CE127 MEET SHAHNoch keine Bewertungen
- SQL Server Security (Logins, Users - Fixed Roles)Dokument3 SeitenSQL Server Security (Logins, Users - Fixed Roles)niaamNoch keine Bewertungen
- Techlog 2018-2 SynchronizationTool DeploymentGuideDokument20 SeitenTechlog 2018-2 SynchronizationTool DeploymentGuidec_b_umashankarNoch keine Bewertungen
- Nareshkumari Choudhary: Career ObjectiveDokument2 SeitenNareshkumari Choudhary: Career Objectivemd khajaNoch keine Bewertungen