Das könnte Ihnen auch gefallen
- Five Dangers of Keeping Poor Network TimeDokument5 SeitenFive Dangers of Keeping Poor Network TimesonicefuNoch keine Bewertungen
- Computer Science SSCDokument20 SeitenComputer Science SSCsonicefuNoch keine Bewertungen
- Default Open Ports LinuxDokument1 SeiteDefault Open Ports LinuxsonicefuNoch keine Bewertungen
- Resolve 1418 SQL Server ErrorDokument1 SeiteResolve 1418 SQL Server ErrorsonicefuNoch keine Bewertungen
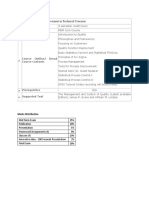
- Course Contents and Marks DistributionDokument1 SeiteCourse Contents and Marks DistributionsonicefuNoch keine Bewertungen
- Opening A Port On LinuxDokument5 SeitenOpening A Port On LinuxsonicefuNoch keine Bewertungen
- Oracle Database 11g - Administration Workshop IIDokument5 SeitenOracle Database 11g - Administration Workshop IIsonicefuNoch keine Bewertungen
- Interna Audit ModuleDokument37 SeitenInterna Audit ModulesonicefuNoch keine Bewertungen
- Oracle Database 11g Administration Workshop I Release 2 - D50102GC20 - 1080544 - USDokument5 SeitenOracle Database 11g Administration Workshop I Release 2 - D50102GC20 - 1080544 - USJinendraabhiNoch keine Bewertungen
- Management System Auditing by David HoyleDokument35 SeitenManagement System Auditing by David HoylesonicefuNoch keine Bewertungen
- Management Review Form Simple ExampleDokument1 SeiteManagement Review Form Simple Examplesonicefu100% (1)
- Annex SL PresentationDokument22 SeitenAnnex SL PresentationsonicefuNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- ClientDokument3 SeitenClientvg_mrtNoch keine Bewertungen
- Rock Smith ConfigurationDokument20 SeitenRock Smith ConfigurationRaúlÁlvarezMNoch keine Bewertungen
- CCBoot Manual - TroubleshootsDokument272 SeitenCCBoot Manual - TroubleshootsHasnan IbrahimNoch keine Bewertungen
- Machine Report FinnalDokument6 SeitenMachine Report FinnalRana FaisalNoch keine Bewertungen
- PN-VC841H: Intelligent Touch BoardDokument3 SeitenPN-VC841H: Intelligent Touch BoardMohamed ShawkyNoch keine Bewertungen
- Ecc R12.2.XDokument118 SeitenEcc R12.2.XDM100% (1)
- Win7 AllkeysDokument9 SeitenWin7 AllkeysWalter Alexandre Dos Santos SilvaNoch keine Bewertungen
- Creat The Browser Program Using Visual Basic 6.0Dokument4 SeitenCreat The Browser Program Using Visual Basic 6.0suv_fame100% (8)
- CCB V2.2.0 Windows Installation Checklist PDFDokument4 SeitenCCB V2.2.0 Windows Installation Checklist PDFWilliansNoch keine Bewertungen
- ??????? ??? ?????? ?? ???????? ???????? ????? ?????Dokument206 Seiten??????? ??? ?????? ?? ???????? ???????? ????? ?????Abhishek MishraNoch keine Bewertungen
- Course Instructor Dr.M.K.Kavitha Devi, Professor/CSE, TCEDokument43 SeitenCourse Instructor Dr.M.K.Kavitha Devi, Professor/CSE, TCEbaby sivakumarNoch keine Bewertungen
- Study Finds That To Fully Understand Potential Cloud Performance Requires Looking at More Than SPECrate 2017 Integer ScoresDokument3 SeitenStudy Finds That To Fully Understand Potential Cloud Performance Requires Looking at More Than SPECrate 2017 Integer ScoresPR.comNoch keine Bewertungen
- JPR Java Programming 22412 Msbte Microproject - Msbte Micro Projects - I SchemeDokument12 SeitenJPR Java Programming 22412 Msbte Microproject - Msbte Micro Projects - I SchemeAtul GaikwadNoch keine Bewertungen
- Unit-Iii Wireless Telecommunication Systems: GSM, GPRS, Umts, Satellite Systems, GPS, Lte/Wimax 2G, 3G, 4GDokument93 SeitenUnit-Iii Wireless Telecommunication Systems: GSM, GPRS, Umts, Satellite Systems, GPS, Lte/Wimax 2G, 3G, 4GMerlin Linda GNoch keine Bewertungen
- Ds Gs78lxx (F) Rev 1.0Dokument9 SeitenDs Gs78lxx (F) Rev 1.0Juan Manuel Ibarra ZapataNoch keine Bewertungen
- API To Inactive Customer AccountDokument3 SeitenAPI To Inactive Customer AccountRaza HassanNoch keine Bewertungen
- Vlsi Lesson PlanDokument3 SeitenVlsi Lesson Planeshwar_worldNoch keine Bewertungen
- SKR4307-Mobile Application: Lab 3b - Android ServiceDokument6 SeitenSKR4307-Mobile Application: Lab 3b - Android ServiceAisya ZuhudiNoch keine Bewertungen
- DPSKDokument3 SeitenDPSKరాహుల్ దేవ్Noch keine Bewertungen
- Nirma: UniversityDokument3 SeitenNirma: UniversityBHENSDADIYA KEVIN PRABHULALNoch keine Bewertungen
- Natural System VariablesDokument68 SeitenNatural System VariablesEVANGELION20150% (1)
- Iraf GuideDokument71 SeitenIraf GuidebhishanNoch keine Bewertungen
- Arithmetic Logic UnitDokument5 SeitenArithmetic Logic UnitNarendra AchariNoch keine Bewertungen
- Arquitectura de SoftwareDokument6 SeitenArquitectura de SoftwareDiego Alejandro Muñoz ToroNoch keine Bewertungen
- Epo 510 RG Log Files 0-00 En-UsDokument10 SeitenEpo 510 RG Log Files 0-00 En-UsabbuasherNoch keine Bewertungen
- Energy Saving System Using IotDokument38 SeitenEnergy Saving System Using IotJigishaNoch keine Bewertungen
- Metal A&C Standalone MK Series User Manual (ID)Dokument1 SeiteMetal A&C Standalone MK Series User Manual (ID)Viorel GutanuNoch keine Bewertungen
- Java RingDokument29 SeitenJava RingAjay Gupta50% (4)
- 9618 Cambridge International As and A Level Computer ScienceDokument576 Seiten9618 Cambridge International As and A Level Computer Science陈湛明100% (29)