Das könnte Ihnen auch gefallen
- Marklogic Server: Xquery and XSLT Reference GuideDokument98 SeitenMarklogic Server: Xquery and XSLT Reference GuideAbdullah YahyaNoch keine Bewertungen
- SCADA System Architecture, Types and ApplicationsDokument21 SeitenSCADA System Architecture, Types and ApplicationsVidya SisaleNoch keine Bewertungen
- PIC-Module 1 - Part 2Dokument32 SeitenPIC-Module 1 - Part 2ParameshNoch keine Bewertungen
- Mini Project I: Literature SearchDokument5 SeitenMini Project I: Literature SearchFernando GalindoNoch keine Bewertungen
- Hibernate ORM NotesDokument215 SeitenHibernate ORM Notesfarooq100% (1)
- Java Class Syntax, Inheritance, Interfaces, Abstract Classes, Inner ClassesDokument3 SeitenJava Class Syntax, Inheritance, Interfaces, Abstract Classes, Inner ClassesKönczöl BoldizsárNoch keine Bewertungen
- Assigment 1 C#Dokument18 SeitenAssigment 1 C#Rishi 86Noch keine Bewertungen
- C Programming For LoopDokument3 SeitenC Programming For LoopslspaNoch keine Bewertungen
- Glossary of Computer TermsDokument37 SeitenGlossary of Computer TermshkgraoNoch keine Bewertungen
- C Programing PDFDokument298 SeitenC Programing PDFAy ENoch keine Bewertungen
- AT&FL Lab 11Dokument6 SeitenAT&FL Lab 11paloNoch keine Bewertungen
- AZ-104.prepaway - Premium.exam.234q: Number: AZ-104 Passing Score: 800 Time Limit: 120 Min File Version: 7.0Dokument254 SeitenAZ-104.prepaway - Premium.exam.234q: Number: AZ-104 Passing Score: 800 Time Limit: 120 Min File Version: 7.0Mustapha FOUAD100% (1)
- Chap4-Loaders-And-LinkersDokument25 SeitenChap4-Loaders-And-Linkersblessy thomasNoch keine Bewertungen
- Notes For PHPDokument113 SeitenNotes For PHPcoding.addict007Noch keine Bewertungen
- Compiler DesignDokument47 SeitenCompiler DesignLearn UpNoch keine Bewertungen
- Cousins of Compiler: Preprocessor, Assembler, Loader and Link-editorDokument7 SeitenCousins of Compiler: Preprocessor, Assembler, Loader and Link-editorMuhammad Fayaz0% (1)
- CS 349 Assignment 1 (Spring - 2019) PDFDokument2 SeitenCS 349 Assignment 1 (Spring - 2019) PDFsahilNoch keine Bewertungen
- UNIT I Basics of C ProgrammingDokument40 SeitenUNIT I Basics of C Programmingyasmeen banuNoch keine Bewertungen
- Stqa Unit 3 NotesDokument22 SeitenStqa Unit 3 Noteschandan kumar giriNoch keine Bewertungen
- Visual Programming - Question BankDokument15 SeitenVisual Programming - Question BankSyedkareem_hkgNoch keine Bewertungen
- Solutions&Notes On Imp TopicsDokument15 SeitenSolutions&Notes On Imp TopicsMarwan AhmedNoch keine Bewertungen
- Macro ProcessorDokument44 SeitenMacro ProcessorDanielLuci100% (1)
- Fundamentals of Algorithmic Problem Solving: B.B. Karki, LSU 2.1 CSC 3102Dokument4 SeitenFundamentals of Algorithmic Problem Solving: B.B. Karki, LSU 2.1 CSC 3102Syed JabeerNoch keine Bewertungen
- Section - A: 1. Define System ProgrammingDokument23 SeitenSection - A: 1. Define System ProgrammingAdarsh RaoNoch keine Bewertungen
- CH03 Loaders and LinkersDokument20 SeitenCH03 Loaders and LinkersTedo Ham100% (4)
- Chapter 1 RaptorDokument59 SeitenChapter 1 Raptorfredsaint100% (1)
- Operating System: Operating Systems: Internals and Design PrinciplesDokument81 SeitenOperating System: Operating Systems: Internals and Design PrinciplesRamadan ElhendawyNoch keine Bewertungen
- System Software 10CS52Dokument206 SeitenSystem Software 10CS52Firomsa TesfayeNoch keine Bewertungen
- Ecs-Unit IDokument29 SeitenEcs-Unit Idavid satyaNoch keine Bewertungen
- 21CSS101J Programming For Problem SolvingDokument135 Seiten21CSS101J Programming For Problem SolvingPratyush DekaNoch keine Bewertungen
- Memory Management TechniquesDokument21 SeitenMemory Management Techniquessrijan consultancyNoch keine Bewertungen
- Case Study Comparison of X85 and X86 AssemblersDokument6 SeitenCase Study Comparison of X85 and X86 AssemblersRiteshNoch keine Bewertungen
- Stm-Lecture Notes - 0 PDFDokument120 SeitenStm-Lecture Notes - 0 PDFDikshith kumar Chilukuru100% (1)
- Software Engineering Question BankDokument3 SeitenSoftware Engineering Question BankNikhil DeshpandeNoch keine Bewertungen
- Unit No 4 Slides FullDokument133 SeitenUnit No 4 Slides Full18JE0254 CHIRAG JAINNoch keine Bewertungen
- Unit 2 The Art of Assembly Language ProgrammingDokument13 SeitenUnit 2 The Art of Assembly Language ProgrammingManofwarriorNoch keine Bewertungen
- T00160030120134075 (L) Pert 1 - Algorithm & Programming and Introduction To C ProgrammingDokument46 SeitenT00160030120134075 (L) Pert 1 - Algorithm & Programming and Introduction To C ProgrammingtermaponNoch keine Bewertungen
- U-Boot Porting GuideDokument7 SeitenU-Boot Porting GuideimioNoch keine Bewertungen
- 1.Q and A Compiler DesignDokument20 Seiten1.Q and A Compiler DesignSneha SathiyamNoch keine Bewertungen
- UNIX Case Study PDFDokument10 SeitenUNIX Case Study PDFaditya pratap singhNoch keine Bewertungen
- GTU Java OOP Course Code 4341602Dokument10 SeitenGTU Java OOP Course Code 4341602Devam Rameshkumar Rana0% (1)
- Unit 3 Ooad 2020Dokument43 SeitenUnit 3 Ooad 2020LAVANYA KARTHIKEYANNoch keine Bewertungen
- One Pass Multi Pass Assembler and Implementation ExamplesDokument17 SeitenOne Pass Multi Pass Assembler and Implementation ExamplesShikha Jamwal67% (3)
- Assembler Directive in Microprocesser 8086Dokument18 SeitenAssembler Directive in Microprocesser 8086Karan MoudgilNoch keine Bewertungen
- Compiler and Interpreter - PresentationDokument10 SeitenCompiler and Interpreter - Presentationjsreevasu100% (1)
- Ssad Notes-Ii BcaDokument68 SeitenSsad Notes-Ii Bcaraj kumarNoch keine Bewertungen
- Assignment-1 and 2Dokument11 SeitenAssignment-1 and 2kansagaratushar67% (3)
- Core PythonDokument11 SeitenCore PythonNagarjuna ReddyNoch keine Bewertungen
- CA 2marksDokument41 SeitenCA 2marksJaya ShreeNoch keine Bewertungen
- Compiler Design Challenges and TechniquesDokument16 SeitenCompiler Design Challenges and Techniquestrupti.kodinariya9810Noch keine Bewertungen
- Ee8551 8085 NotesDokument31 SeitenEe8551 8085 NotesKUMARANSCRNoch keine Bewertungen
- Compiler Design Chapter-1Dokument41 SeitenCompiler Design Chapter-1Vuggam VenkateshNoch keine Bewertungen
- OOP - Java - Session 1Dokument44 SeitenOOP - Java - Session 1gauravlkoNoch keine Bewertungen
- Computer Organization NotesDokument115 SeitenComputer Organization NotesEbbaqhbqNoch keine Bewertungen
- Compiler Design PhasesDokument85 SeitenCompiler Design PhasesMohammed ThawfeeqNoch keine Bewertungen
- RFID Security System Privacy RisksDokument25 SeitenRFID Security System Privacy RisksAbdullah SarwarNoch keine Bewertungen
- Turbo C++ Quick Start GuideDokument6 SeitenTurbo C++ Quick Start GuideRahul DubeyNoch keine Bewertungen
- Mother BoardDokument29 SeitenMother BoardSwayamprakash PatelNoch keine Bewertungen
- SSCDNotes PDFDokument53 SeitenSSCDNotes PDFshreenathk_n100% (1)
- Subprogram Sequence Control Attributes of Data Control Parameter Passing Explicit Common EnvironmentsDokument32 SeitenSubprogram Sequence Control Attributes of Data Control Parameter Passing Explicit Common EnvironmentsSawan KarnNoch keine Bewertungen
- Real Time Operating System A Complete Guide - 2020 EditionVon EverandReal Time Operating System A Complete Guide - 2020 EditionNoch keine Bewertungen
- Network Management System A Complete Guide - 2020 EditionVon EverandNetwork Management System A Complete Guide - 2020 EditionBewertung: 5 von 5 Sternen5/5 (1)
- IO Software LayersDokument11 SeitenIO Software LayersVidya SisaleNoch keine Bewertungen
- Chap 1 DhamdhereDokument84 SeitenChap 1 DhamdhereVidya SisaleNoch keine Bewertungen
- Getting Started with Google ClassroomDokument18 SeitenGetting Started with Google ClassroomVidya Sisale100% (3)
- Types of Switches - Electrical TechnologyDokument15 SeitenTypes of Switches - Electrical TechnologyVidya SisaleNoch keine Bewertungen
- Image Processing For Driver Vigilance System Using ANNDokument85 SeitenImage Processing For Driver Vigilance System Using ANNVidya SisaleNoch keine Bewertungen
- Understanding Skip Rule and Stop Recurring RuleDokument5 SeitenUnderstanding Skip Rule and Stop Recurring RuleBalamurugan Natesan100% (1)
- Introduction to Programming LanguagesDokument10 SeitenIntroduction to Programming Languagesnegash belihuNoch keine Bewertungen
- Avamar Backup Clients User Guide 19.3Dokument86 SeitenAvamar Backup Clients User Guide 19.3manish.puri.gcpNoch keine Bewertungen
- Genesys Pulse: Manage Your Service Level Objectives and Improve Employee PerformanceDokument2 SeitenGenesys Pulse: Manage Your Service Level Objectives and Improve Employee PerformanceAhmad JamalNoch keine Bewertungen
- C# CodingDokument41 SeitenC# CodingPrakash PhondeNoch keine Bewertungen
- IT232 - ProjectDokument10 SeitenIT232 - ProjectwazirkqasemNoch keine Bewertungen
- Pharmacy Management System Class DiagramDokument4 SeitenPharmacy Management System Class DiagramSatyam Singh100% (1)
- Project Report On Multiplex - Ticket Booking SystemDokument32 SeitenProject Report On Multiplex - Ticket Booking SystemGaurav Pathak50% (2)
- Getting Started With NetMiner ScriptDokument26 SeitenGetting Started With NetMiner ScriptCamilo HernandezNoch keine Bewertungen
- Android Mobile Note Taking Optimization Using Hybrid TechniquesDokument6 SeitenAndroid Mobile Note Taking Optimization Using Hybrid TechniquesEditor IJTSRDNoch keine Bewertungen
- Oops All Programs 1 1Dokument39 SeitenOops All Programs 1 1Sourabh SumanNoch keine Bewertungen
- Robux Code (Console Code)Dokument5 SeitenRobux Code (Console Code)Kzu100% (1)
- SQL Sales ManagementDokument6 SeitenSQL Sales ManagementDIVYANSHMUDGAL RA1711003020646Noch keine Bewertungen
- code ERESOLVEDokument1 Seitecode ERESOLVEapps.ian2Noch keine Bewertungen
- Complex Problems PythonDokument12 SeitenComplex Problems Pythonjs9118164Noch keine Bewertungen
- G 2 RelnotesDokument290 SeitenG 2 Relnotesapi-3805119Noch keine Bewertungen
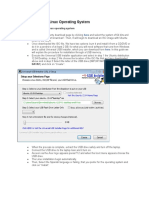
- Installation of The Linux Operating SystemDokument4 SeitenInstallation of The Linux Operating Systemkevin louisNoch keine Bewertungen
- Subprograms (Functions) in Python: Grade 09 - Topic 02 - Programming and Development Note - Part IvDokument3 SeitenSubprograms (Functions) in Python: Grade 09 - Topic 02 - Programming and Development Note - Part IvShehan MorawakaNoch keine Bewertungen
- SE05 Designing The ArchitectureDokument77 SeitenSE05 Designing The ArchitectureHabibur Rahman NabilNoch keine Bewertungen
- Rosinski SoftDokument2 SeitenRosinski SoftManuel Alvarez GarroNoch keine Bewertungen
- 22 Mca 1075 Adid BakerDokument4 Seiten22 Mca 1075 Adid BakerORBIT GUYNoch keine Bewertungen
- Week 01-Theory Slides-S1Dokument16 SeitenWeek 01-Theory Slides-S1Luis peter ShinyalaNoch keine Bewertungen
- Easy Ways To Activate Windows 11 For FREE Without A Product KeyDokument14 SeitenEasy Ways To Activate Windows 11 For FREE Without A Product KeyEMAPU PUBLICIDAD Y MARKETINGNoch keine Bewertungen
- G-Series Lua API V8.45 Overview and ReferenceDokument44 SeitenG-Series Lua API V8.45 Overview and ReferenceNijat MahmudovNoch keine Bewertungen
- BMS ReportDokument40 SeitenBMS Reportsafura aliyaNoch keine Bewertungen
- SAP Note 976195 MR8M M8 186 For Document Containing InvoiceDokument3 SeitenSAP Note 976195 MR8M M8 186 For Document Containing InvoiceyogihNoch keine Bewertungen
- Step by Step Automation Using Zerodha API Python Version by Tewani, PuneetDokument171 SeitenStep by Step Automation Using Zerodha API Python Version by Tewani, PuneetArpit MaheshwariNoch keine Bewertungen