Das könnte Ihnen auch gefallen
- Major PPT Batch - 13Dokument28 SeitenMajor PPT Batch - 13Vasanth PerniNoch keine Bewertungen
- Approximate Radix-8 Booth MultipliersDokument7 SeitenApproximate Radix-8 Booth Multipliersezhilarasi ezhilarsiNoch keine Bewertungen
- A Review of Different Methods For Booth Multiplier: Jyoti Kalia, Vikas MittalDokument4 SeitenA Review of Different Methods For Booth Multiplier: Jyoti Kalia, Vikas Mittaldivya_cestNoch keine Bewertungen
- Reference 9Dokument4 SeitenReference 9Ramesh NairNoch keine Bewertungen
- 2Tue4B Controlo18 Submission 2Dokument7 Seiten2Tue4B Controlo18 Submission 2Văn Nghĩa NguyễnNoch keine Bewertungen
- Design and Implementation of HighDokument6 SeitenDesign and Implementation of Highsohan kambleNoch keine Bewertungen
- Adaptive Approximation in Arithmetic Circuits A Low-Power Unsigned Divider DesignDokument6 SeitenAdaptive Approximation in Arithmetic Circuits A Low-Power Unsigned Divider DesignShweta RaoNoch keine Bewertungen
- HW MultisectorDokument22 SeitenHW MultisectorengineerdandayoNoch keine Bewertungen
- Design of Efficient Serial Divider Using HAN CARLSON AdderDokument3 SeitenDesign of Efficient Serial Divider Using HAN CARLSON AdderInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Reference 7Dokument4 SeitenReference 7Ramesh NairNoch keine Bewertungen
- High-Performance Speed Measurement by Suppression of Systematic Resolver and Encoder ErrorsDokument5 SeitenHigh-Performance Speed Measurement by Suppression of Systematic Resolver and Encoder ErrorsGoran MiljkovicNoch keine Bewertungen
- Design of Approximate Radix-4 Booth Multipliers For Error-Tolerant ComputingDokument7 SeitenDesign of Approximate Radix-4 Booth Multipliers For Error-Tolerant ComputingBilal KhanNoch keine Bewertungen
- FINAL PresentationDokument31 SeitenFINAL Presentationsrinithi20032005Noch keine Bewertungen
- Low Latency Floating-Point Division and Square Root UnitDokument14 SeitenLow Latency Floating-Point Division and Square Root Unitpradipta.sarkarNoch keine Bewertungen
- Huawei ACPDokument18 SeitenHuawei ACPmlmb tuhNoch keine Bewertungen
- Ieee VlsiDokument7 SeitenIeee VlsiSwarupa ReddyNoch keine Bewertungen
- Block-Based Carry Speculative Approximate Adder For Energy-Efficient ApplicationsDokument5 SeitenBlock-Based Carry Speculative Approximate Adder For Energy-Efficient Applicationskrishna sNoch keine Bewertungen
- Training Course - 5G RAN3.0 High Speed MobilityDokument15 SeitenTraining Course - 5G RAN3.0 High Speed MobilityVVLNoch keine Bewertungen
- Icssit48917 2020 9214270Dokument6 SeitenIcssit48917 2020 9214270Janani MunisamyNoch keine Bewertungen
- Data AccelerationDokument18 SeitenData AccelerationpoteNoch keine Bewertungen
- A 14 Bit, 30 MS/S, 38 MW SAR ADC Using Noise Filter Gear ShiftingDokument5 SeitenA 14 Bit, 30 MS/S, 38 MW SAR ADC Using Noise Filter Gear ShiftingMa SeenivasanNoch keine Bewertungen
- Roba MulDokument56 SeitenRoba MulNishitha NishiNoch keine Bewertungen
- Ballani PDFDokument14 SeitenBallani PDFAadan CaddeNoch keine Bewertungen
- Ijser: Design of A High Speed AdderDokument4 SeitenIjser: Design of A High Speed AdderadiNoch keine Bewertungen
- Shanthi Pavan - CT Audio DSM With FIR - JSSC 2014Dokument11 SeitenShanthi Pavan - CT Audio DSM With FIR - JSSC 2014Saleh Heidary ShalmanyNoch keine Bewertungen
- Enhancement of Analytical OBRDokument6 SeitenEnhancement of Analytical OBRIJAERS JOURNALNoch keine Bewertungen
- Bien Tan Fuji Frenic Multi Series 21072017101433Dokument44 SeitenBien Tan Fuji Frenic Multi Series 21072017101433Nguyen VuNoch keine Bewertungen
- (Raktim Roy)Dokument3 Seiten(Raktim Roy)Soutik DeyNoch keine Bewertungen
- 1 s2.0 S0026269219303799 MainDokument13 Seiten1 s2.0 S0026269219303799 MainShylu SamNoch keine Bewertungen
- Multi Layer Service Triggered MobilityDokument31 SeitenMulti Layer Service Triggered MobilityArturo GarzaNoch keine Bewertungen
- 10 1109@tcsii 2019 2901060Dokument5 Seiten10 1109@tcsii 2019 2901060HemanthNoch keine Bewertungen
- HSDPA Multi CarrierDokument21 SeitenHSDPA Multi Carrierpote100% (1)
- Nisarg Project Final YearDokument59 SeitenNisarg Project Final Yearsoheb ShaikhNoch keine Bewertungen
- Basic Characteristics of LeadDokument3 SeitenBasic Characteristics of LeadsbhaleshNoch keine Bewertungen
- Approximate Radix-8 Booth Multipliers For Low-Power and High-Performance OperationDokument8 SeitenApproximate Radix-8 Booth Multipliers For Low-Power and High-Performance OperationMeet MehtaNoch keine Bewertungen
- Criterion Directional Guidance System Slide Sheet BrochureDokument2 SeitenCriterion Directional Guidance System Slide Sheet BrochuretxcrudeNoch keine Bewertungen
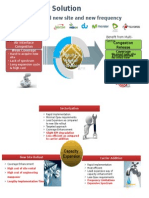
- Multi-Sector Solution: No Need New Site and New FrequencyDokument2 SeitenMulti-Sector Solution: No Need New Site and New FrequencyMuhammad Jamil AwanNoch keine Bewertungen
- 3rd Unit CSDDokument60 Seiten3rd Unit CSDYeswanth Manikanta MNoch keine Bewertungen
- Control Tutorials For MATLAB and Simulink - Introduction - Frequency Domain Methods For Controller DesignDokument12 SeitenControl Tutorials For MATLAB and Simulink - Introduction - Frequency Domain Methods For Controller DesigncesarinigillasNoch keine Bewertungen
- FAA Overview On PBNDokument65 SeitenFAA Overview On PBNDian ChristaNoch keine Bewertungen
- Adaptive Equalizer: Extension To Communication System: XXX-X-XXXX-XXXX-X/XX/$XX.00 ©20XX IEEEDokument8 SeitenAdaptive Equalizer: Extension To Communication System: XXX-X-XXXX-XXXX-X/XX/$XX.00 ©20XX IEEESIMRAN GUPTANoch keine Bewertungen
- Performance, Analysis and Comparison of Digital Adders: Jasmine Saini Somya Agarwal, Aditi KansalDokument4 SeitenPerformance, Analysis and Comparison of Digital Adders: Jasmine Saini Somya Agarwal, Aditi Kansalssabinayaa12Noch keine Bewertungen
- FinalDokument26 SeitenFinalKarthiga MuruganNoch keine Bewertungen
- 17 OEP100320 LTE Radio Network Capacity Dimensioning ISSUE 1.11Dokument34 Seiten17 OEP100320 LTE Radio Network Capacity Dimensioning ISSUE 1.11MashaalNoch keine Bewertungen
- IJETR032733Dokument4 SeitenIJETR032733erpublicationNoch keine Bewertungen
- A Comparative Study On Ripple Carry Adder and Modified Square Root Carry Select Adder in Radix-4 8 8 Booth MultiplierDokument4 SeitenA Comparative Study On Ripple Carry Adder and Modified Square Root Carry Select Adder in Radix-4 8 8 Booth MultiplierInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- 1-Tc Fit Telu Basic 4g LteDokument64 Seiten1-Tc Fit Telu Basic 4g LteNur Chairil SyamNoch keine Bewertungen
- (Eng) Zx890lch 5a Ks En316Dokument13 Seiten(Eng) Zx890lch 5a Ks En316MC TAK LEENoch keine Bewertungen
- Mahesh 2010Dokument14 SeitenMahesh 2010Syfunnisa ShaikNoch keine Bewertungen
- 11.3 Pipelining: Flip FlopsDokument1 Seite11.3 Pipelining: Flip FlopsAnonymous YsVh1JJY9TNoch keine Bewertungen
- Network Load ManagerDokument124 SeitenNetwork Load Managerprince jhaNoch keine Bewertungen
- Srikant H 2016Dokument4 SeitenSrikant H 2016venkat301485Noch keine Bewertungen
- 20mt8307 Term PaperDokument27 Seiten20mt8307 Term Papernaga DaminiNoch keine Bewertungen
- LFC v8 msc2013 Final PDFDokument7 SeitenLFC v8 msc2013 Final PDFdimas sandiNoch keine Bewertungen
- Ccie Ei Lab Exam: Module 1Dokument54 SeitenCcie Ei Lab Exam: Module 1Red FlagNoch keine Bewertungen
- Improvisation of Gabor Filter Design Using Verilog HDLDokument4 SeitenImprovisation of Gabor Filter Design Using Verilog HDLVijay KannamallaNoch keine Bewertungen
- Flyer Fanuc LVCDokument2 SeitenFlyer Fanuc LVCTonyPChNoch keine Bewertungen
- 11 Chapter 4Dokument7 Seiten11 Chapter 4Paramesh WaranNoch keine Bewertungen
- Reversible Data Hiding PDFDokument12 SeitenReversible Data Hiding PDFParamesh WaranNoch keine Bewertungen
- QAMDokument6 SeitenQAMphe19okt06nyotNoch keine Bewertungen
- KeyStep Manual 1 0 0 enDokument71 SeitenKeyStep Manual 1 0 0 ensdfsdfsdfsdfNoch keine Bewertungen
- 07 Chapter 1Dokument85 Seiten07 Chapter 1Paramesh WaranNoch keine Bewertungen
- 15V42Dokument9 Seiten15V42Paramesh WaranNoch keine Bewertungen
- Image Processing Using MatlabDokument19 SeitenImage Processing Using MatlabParamesh WaranNoch keine Bewertungen
- Wireless Sensor Network (WSN) Control For Industry MonitoringDokument3 SeitenWireless Sensor Network (WSN) Control For Industry MonitoringParamesh WaranNoch keine Bewertungen
- Solar Hybrid CarDokument4 SeitenSolar Hybrid CarParamesh WaranNoch keine Bewertungen
- A Crop Growth ReportDokument28 SeitenA Crop Growth ReportParamesh WaranNoch keine Bewertungen
- Cooperative Downlink TransmissionDokument1 SeiteCooperative Downlink TransmissionParamesh WaranNoch keine Bewertungen
- Detection and Inpainting of Facial Wrinkles Using Texture Orientation Fields and Markov Random Field ModelingDokument3 SeitenDetection and Inpainting of Facial Wrinkles Using Texture Orientation Fields and Markov Random Field ModelingParamesh WaranNoch keine Bewertungen
- Multiple Diseases Classification and Identification of Blood Bleeding in Endoscopy VideoDokument2 SeitenMultiple Diseases Classification and Identification of Blood Bleeding in Endoscopy VideoParamesh WaranNoch keine Bewertungen
- Introduction To MATLAB and Image ProcessingDokument14 SeitenIntroduction To MATLAB and Image ProcessingParamesh WaranNoch keine Bewertungen
- Toll CollectionDokument5 SeitenToll CollectionParamesh WaranNoch keine Bewertungen
- AndDokument1 SeiteAndParamesh WaranNoch keine Bewertungen
- A Probabilistic Approach For Color CorrectionDokument16 SeitenA Probabilistic Approach For Color CorrectionParamesh WaranNoch keine Bewertungen
- 1409 0875Dokument16 Seiten1409 0875Paramesh WaranNoch keine Bewertungen
- V3i11 Ijertv3is110404Dokument3 SeitenV3i11 Ijertv3is110404Paramesh WaranNoch keine Bewertungen
- Lowpowervlsidesignbook 140426055029 Phpapp02Dokument326 SeitenLowpowervlsidesignbook 140426055029 Phpapp02sivapothiNoch keine Bewertungen
- 5695 45 136 Sensorless Detection Rotor SRMDokument15 Seiten5695 45 136 Sensorless Detection Rotor SRMParamesh WaranNoch keine Bewertungen
- Tamilnadu PEC DetailsDokument75 SeitenTamilnadu PEC Detailsinfosrig100% (1)
- Elimination of Carbon Particles From Exhaust GasDokument4 SeitenElimination of Carbon Particles From Exhaust GasParamesh WaranNoch keine Bewertungen
- SPOC - A Secure and Privacy-Preserving Opportunistic Computing Framework For Mobile-Healthcare EmergencyDokument10 SeitenSPOC - A Secure and Privacy-Preserving Opportunistic Computing Framework For Mobile-Healthcare Emergencyaman.4uNoch keine Bewertungen
- Chapter01 - An Overview of VLSIDokument12 SeitenChapter01 - An Overview of VLSIParamesh WaranNoch keine Bewertungen
- Ver I Log Coding GuidelinesDokument29 SeitenVer I Log Coding GuidelinesParamesh WaranNoch keine Bewertungen
- ManualDokument38 SeitenManualParamesh WaranNoch keine Bewertungen
- ReadmeDokument4 SeitenReadmeParamesh WaranNoch keine Bewertungen
- Belt Conveyor 2Dokument27 SeitenBelt Conveyor 2muruganNoch keine Bewertungen
- FIREBASE Edited PresentationDokument12 SeitenFIREBASE Edited PresentationNiraj MirgalNoch keine Bewertungen
- ARIIX - Clean - Eating - Easy - Ecipes - For - A - Healthy - Life - Narx PDFDokument48 SeitenARIIX - Clean - Eating - Easy - Ecipes - For - A - Healthy - Life - Narx PDFAnte BaškovićNoch keine Bewertungen
- Diagnosis ListDokument1 SeiteDiagnosis ListSenyorita KHayeNoch keine Bewertungen
- The Future of FinanceDokument30 SeitenThe Future of FinanceRenuka SharmaNoch keine Bewertungen
- Asus x453Dokument5 SeitenAsus x453Rhiry Ntuh AthryNoch keine Bewertungen
- PCM Cables: What Is PCM Cable? Why PCM Cables? Application?Dokument14 SeitenPCM Cables: What Is PCM Cable? Why PCM Cables? Application?sidd_mgrNoch keine Bewertungen
- Art Appreciation Chapter 3 SummaryDokument6 SeitenArt Appreciation Chapter 3 SummaryDiego A. Odchimar IIINoch keine Bewertungen
- Capgemini - 2012-06-13 - 2012 Analyst Day - 3 - Michelin - A Better Way ForwardDokument12 SeitenCapgemini - 2012-06-13 - 2012 Analyst Day - 3 - Michelin - A Better Way ForwardAvanish VermaNoch keine Bewertungen
- Kiraan Supply Mesin AutomotifDokument6 SeitenKiraan Supply Mesin Automotifjamali sadatNoch keine Bewertungen
- OB and Attendance PolicyDokument2 SeitenOB and Attendance PolicyAshna MeiNoch keine Bewertungen
- API RP 7C-11F Installation, Maintenance and Operation of Internal Combustion Engines.Dokument3 SeitenAPI RP 7C-11F Installation, Maintenance and Operation of Internal Combustion Engines.Rashid Ghani100% (1)
- Domesticity and Power in The Early Mughal WorldDokument17 SeitenDomesticity and Power in The Early Mughal WorldUjjwal Gupta100% (1)
- 15 Miscellaneous Bacteria PDFDokument2 Seiten15 Miscellaneous Bacteria PDFAnne MorenoNoch keine Bewertungen
- JIMMA Electrical&ComputerEngDokument219 SeitenJIMMA Electrical&ComputerEngTewodros71% (7)
- Kortz Center GTA Wiki FandomDokument1 SeiteKortz Center GTA Wiki FandomsamNoch keine Bewertungen
- Agenda - 2 - Presentation - MS - IUT - Thesis Proposal PPT Muhaiminul 171051001Dokument13 SeitenAgenda - 2 - Presentation - MS - IUT - Thesis Proposal PPT Muhaiminul 171051001Tanvir AhmadNoch keine Bewertungen
- A Project On "Automatic Water Sprinkler Based On Wet and Dry Conditions"Dokument28 SeitenA Project On "Automatic Water Sprinkler Based On Wet and Dry Conditions"Srínívas SrínuNoch keine Bewertungen
- Extraction of Mangiferin From Mangifera Indica L. LeavesDokument7 SeitenExtraction of Mangiferin From Mangifera Indica L. LeavesDaniel BartoloNoch keine Bewertungen
- FluteDokument13 SeitenFlutefisher3910% (1)
- Outlook of PonDokument12 SeitenOutlook of Ponty nguyenNoch keine Bewertungen
- 1KHW001492de Tuning of ETL600 TX RF Filter E5TXDokument7 Seiten1KHW001492de Tuning of ETL600 TX RF Filter E5TXSalvador FayssalNoch keine Bewertungen
- Eje Delantero Fxl14 (1) .6Dokument2 SeitenEje Delantero Fxl14 (1) .6Lenny VirgoNoch keine Bewertungen
- Ethical Hacking IdDokument24 SeitenEthical Hacking IdSilvester Dian Handy PermanaNoch keine Bewertungen
- Advanced Oil Gas Accounting International Petroleum Accounting International Petroleum Operations MSC Postgraduate Diploma Intensive Full TimeDokument70 SeitenAdvanced Oil Gas Accounting International Petroleum Accounting International Petroleum Operations MSC Postgraduate Diploma Intensive Full TimeMoheieldeen SamehNoch keine Bewertungen
- Ships Near A Rocky Coast With Awaiting Landing PartyDokument2 SeitenShips Near A Rocky Coast With Awaiting Landing PartyFouaAj1 FouaAj1Noch keine Bewertungen
- Not CE 2015 Version R Series 1t-3.5t Operating Manua 2015-08Dokument151 SeitenNot CE 2015 Version R Series 1t-3.5t Operating Manua 2015-08hocine gherbiNoch keine Bewertungen
- Kallatam of Kallatar (In Tamil Script Tscii Format)Dokument78 SeitenKallatam of Kallatar (In Tamil Script Tscii Format)rprabhuNoch keine Bewertungen
- Investment Analysis and Portfolio Management: Frank K. Reilly & Keith C. BrownDokument113 SeitenInvestment Analysis and Portfolio Management: Frank K. Reilly & Keith C. BrownWhy you want to knowNoch keine Bewertungen
- Post Renaissance Architecture in EuropeDokument10 SeitenPost Renaissance Architecture in Europekali_007Noch keine Bewertungen
- Dependent ClauseDokument28 SeitenDependent ClauseAndi Febryan RamadhaniNoch keine Bewertungen