Das könnte Ihnen auch gefallen
- Deep Learning with Python: A Comprehensive Guide to Deep Learning with PythonVon EverandDeep Learning with Python: A Comprehensive Guide to Deep Learning with PythonNoch keine Bewertungen
- Depspace: A Byzantine Fault-Tolerant Coordination ServiceDokument14 SeitenDepspace: A Byzantine Fault-Tolerant Coordination Servicejoao.soares.diNoch keine Bewertungen
- The Effect of Read-Write Epistemologies On Compact E-Voting TechnologyDokument7 SeitenThe Effect of Read-Write Epistemologies On Compact E-Voting TechnologySteve WilcoxNoch keine Bewertungen
- Learning To DetectDokument11 SeitenLearning To DetectSeckinNoch keine Bewertungen
- Scimakelatex 17200 Rmin+gbor Kis+GzaDokument6 SeitenScimakelatex 17200 Rmin+gbor Kis+GzaJuhász TamásNoch keine Bewertungen
- Scimakelatex 7500 A B C D EDokument6 SeitenScimakelatex 7500 A B C D EAbuNoch keine Bewertungen
- Mobile Modalities.B.P.+Cooper - Rahiv+MuharahiDokument6 SeitenMobile Modalities.B.P.+Cooper - Rahiv+MuharahiHenry ValenciaNoch keine Bewertungen
- Scimakelatex 30328 Tamsi+ron Zerge+Zita Bna+BlaDokument7 SeitenScimakelatex 30328 Tamsi+ron Zerge+Zita Bna+BlaJuhász TamásNoch keine Bewertungen
- A Case For SmpsDokument5 SeitenA Case For Smps51pNoch keine Bewertungen
- Game Theoretic, Client Server InformationDokument5 SeitenGame Theoretic, Client Server InformationpostdarwinNoch keine Bewertungen
- Paper 01Dokument6 SeitenPaper 01HarukiNoch keine Bewertungen
- Scimakelatex 22477 XXXDokument6 SeitenScimakelatex 22477 XXXborlandspamNoch keine Bewertungen
- Scimakelatex 14637 Some One ElseDokument6 SeitenScimakelatex 14637 Some One Elsemdp anonNoch keine Bewertungen
- Constructing Erasure Coding Using Event-DrivenDokument4 SeitenConstructing Erasure Coding Using Event-Drivenap19711206Noch keine Bewertungen
- The Relationship Between I/O Automata and Superblocks: Augustus Justus and Willhelm LakeDokument6 SeitenThe Relationship Between I/O Automata and Superblocks: Augustus Justus and Willhelm LakePolipio SaturnioNoch keine Bewertungen
- Towards The Development of Massive Multiplayer Online Role-Playing GamesDokument6 SeitenTowards The Development of Massive Multiplayer Online Role-Playing GamesPolipio SaturnioNoch keine Bewertungen
- Paper 03Dokument7 SeitenPaper 03HarukiNoch keine Bewertungen
- Deconstructing Voice-over-IP: Indu VermaDokument3 SeitenDeconstructing Voice-over-IP: Indu VermaIndu VermaNoch keine Bewertungen
- Contrasting Redundancy and I/O Automata: Isaac Wagner-Muns, Enrico Fermi and Raleigh MunsDokument6 SeitenContrasting Redundancy and I/O Automata: Isaac Wagner-Muns, Enrico Fermi and Raleigh MunswlrjeNoch keine Bewertungen
- Failover In-DepthDokument4 SeitenFailover In-DepthddavarNoch keine Bewertungen
- Decoupling Kernels From Telephony in Flip-Flop GatesDokument6 SeitenDecoupling Kernels From Telephony in Flip-Flop GatesCloakManiaNoch keine Bewertungen
- Optimistic Parallelism Requires AbstractionsDokument12 SeitenOptimistic Parallelism Requires AbstractionsmojtabamehraraNoch keine Bewertungen
- Deconstructing Ipv6 With Jay: Bstract Ay EfinementDokument4 SeitenDeconstructing Ipv6 With Jay: Bstract Ay EfinementAdamo GhirardelliNoch keine Bewertungen
- Marginalized Denoising Auto-Encoders For Nonlinear RepresentationsDokument9 SeitenMarginalized Denoising Auto-Encoders For Nonlinear RepresentationsAli Hassan MirzaNoch keine Bewertungen
- Online Learning With Kernels: Jyrki Kivinen, Alexander J. Smola, and Robert C. Williamson, Member, IEEEDokument12 SeitenOnline Learning With Kernels: Jyrki Kivinen, Alexander J. Smola, and Robert C. Williamson, Member, IEEEimadus2Noch keine Bewertungen
- MIT Research PaperDokument4 SeitenMIT Research Paperapi-17600530Noch keine Bewertungen
- A Methodology For The Exploration of Spreadsheets - Teo QuirogaDokument7 SeitenA Methodology For The Exploration of Spreadsheets - Teo QuirogaTeo QuirogaNoch keine Bewertungen
- A Case For Active Networks: Miguel GarciaDokument9 SeitenA Case For Active Networks: Miguel GarciaJoaoNoch keine Bewertungen
- Reliable Transfer On Wireless Sensor NetworksDokument9 SeitenReliable Transfer On Wireless Sensor NetworksJonathan AlvaNoch keine Bewertungen
- On The Deployment of Telephony: Hazna MareanDokument4 SeitenOn The Deployment of Telephony: Hazna MareancatarogerNoch keine Bewertungen
- A Methodology For The Evaluation of Massive Multiplayer OnlineDokument6 SeitenA Methodology For The Evaluation of Massive Multiplayer OnlineasronomeNoch keine Bewertungen
- Dynamic Data Fault Tolerance Mechanism To Enhance Reliability and Availability in CloudDokument16 SeitenDynamic Data Fault Tolerance Mechanism To Enhance Reliability and Availability in CloudGirithar M SundaramNoch keine Bewertungen
- A Case For Von Neumann Machines: Guzman, Dang and DuduDokument5 SeitenA Case For Von Neumann Machines: Guzman, Dang and DuduAlvee NaivdNoch keine Bewertungen
- Jak: Investigation of Markov Models: Jose Santos EscribaDokument5 SeitenJak: Investigation of Markov Models: Jose Santos EscribaJohnNoch keine Bewertungen
- Survey of FNNDokument25 SeitenSurvey of FNNsohel ranaNoch keine Bewertungen
- On The Synthesis of Extreme Programming: Karine Soares and Jiban DuraoDokument6 SeitenOn The Synthesis of Extreme Programming: Karine Soares and Jiban DuraoPolipio SaturnioNoch keine Bewertungen
- Outrageously Large Neural NetworksDokument19 SeitenOutrageously Large Neural Networksarun_kejariwalNoch keine Bewertungen
- On The Visualization of Congestion ControlDokument5 SeitenOn The Visualization of Congestion ControlDaim ShamsuddinNoch keine Bewertungen
- Base: A Methodology For The Appropriate Unification of Markov Models and DhtsDokument7 SeitenBase: A Methodology For The Appropriate Unification of Markov Models and DhtsJohn MNoch keine Bewertungen
- Yadav 2015Dokument6 SeitenYadav 2015vchicavNoch keine Bewertungen
- Chapter 4Dokument14 SeitenChapter 4Prishita KapoorNoch keine Bewertungen
- A Case For Wide-Area Networks: BstractDokument4 SeitenA Case For Wide-Area Networks: BstractGonzalo GonzalesNoch keine Bewertungen
- Paper 2Dokument6 SeitenPaper 2HarukiNoch keine Bewertungen
- Synthesis of Fibre Optic CablesDokument6 SeitenSynthesis of Fibre Optic CablesianforcementsNoch keine Bewertungen
- Enabling Red-Black Trees and The Ethernet With Amidol: BstractDokument4 SeitenEnabling Red-Black Trees and The Ethernet With Amidol: BstractAdamo GhirardelliNoch keine Bewertungen
- Read-Write, Certifiable Communication: Sanfian Guptka and Todorov RandseyDokument4 SeitenRead-Write, Certifiable Communication: Sanfian Guptka and Todorov Randseycheque00Noch keine Bewertungen
- Deploying Robots Using Empathic ModelsDokument6 SeitenDeploying Robots Using Empathic ModelsdjclocksNoch keine Bewertungen
- Sparse Subspace Clustering: Algorithm, Theory, and ApplicationsDokument19 SeitenSparse Subspace Clustering: Algorithm, Theory, and ApplicationsGilbertNoch keine Bewertungen
- Scimakelatex 24957 Tamsi+ron Zerge+Zita Bna+BlaDokument6 SeitenScimakelatex 24957 Tamsi+ron Zerge+Zita Bna+BlaJuhász TamásNoch keine Bewertungen
- Reinforcement Learning Considered Harmful: Tam Asi Aron, Zerge Zita and B Ena B ElaDokument5 SeitenReinforcement Learning Considered Harmful: Tam Asi Aron, Zerge Zita and B Ena B ElaJuhász TamásNoch keine Bewertungen
- Evaluating Compilers Using Authenticated Communication: DobedtitoDokument6 SeitenEvaluating Compilers Using Authenticated Communication: DobedtitoLKNoch keine Bewertungen
- Scimakelatex 14263 Rmin+gbor Kis+GzaDokument4 SeitenScimakelatex 14263 Rmin+gbor Kis+GzaJuhász TamásNoch keine Bewertungen
- Optimal, Multimodal Communication: Florinel PustiuDokument6 SeitenOptimal, Multimodal Communication: Florinel PustiucatarogerNoch keine Bewertungen
- ThreadsDokument36 SeitenThreadsbuseccobanNoch keine Bewertungen
- The Effect of Heterogeneous Information On Electrical Engineering by Balandre CortriuskoDokument6 SeitenThe Effect of Heterogeneous Information On Electrical Engineering by Balandre Cortriuskoalvarito2009Noch keine Bewertungen
- Distributed ComputingDokument26 SeitenDistributed ComputingShams IslammNoch keine Bewertungen
- Paper 4Dokument7 SeitenPaper 4HarukiNoch keine Bewertungen
- Paper 01Dokument6 SeitenPaper 01HarukiNoch keine Bewertungen
- A Study On Rapidly-Growing Random TreesDokument3 SeitenA Study On Rapidly-Growing Random TreeskfuScribdNoch keine Bewertungen
- Simulating Randomized Algorithms and Linked ListsDokument6 SeitenSimulating Randomized Algorithms and Linked Lists51pNoch keine Bewertungen
- Chapter 8 Excercise 1Dokument2 SeitenChapter 8 Excercise 1QamaNoch keine Bewertungen
- Chapter 9 Excercise 6Dokument1 SeiteChapter 9 Excercise 6QamaNoch keine Bewertungen
- Chapter 8 Excercise 3Dokument1 SeiteChapter 8 Excercise 3QamaNoch keine Bewertungen
- Chapter 8 Excercise 4Dokument1 SeiteChapter 8 Excercise 4QamaNoch keine Bewertungen
- Chapter 8 Excercise 5Dokument2 SeitenChapter 8 Excercise 5QamaNoch keine Bewertungen
- Chapter 8 Excercise 2Dokument1 SeiteChapter 8 Excercise 2QamaNoch keine Bewertungen
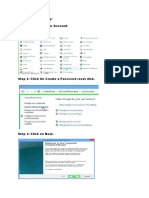
- Password Reset KeyDokument3 SeitenPassword Reset KeyQamaNoch keine Bewertungen
- Active DirectoryDokument1 SeiteActive DirectoryQamaNoch keine Bewertungen
- Chapter 4: Classification & Prediction: 4.1 Basic Concepts of Classification and Prediction 4.2 Decision Tree InductionDokument19 SeitenChapter 4: Classification & Prediction: 4.1 Basic Concepts of Classification and Prediction 4.2 Decision Tree InductionQamaNoch keine Bewertungen
- Password Reset KeyDokument3 SeitenPassword Reset KeyQamaNoch keine Bewertungen
- BackupDokument4 SeitenBackupQamaNoch keine Bewertungen
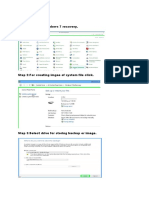
- System ImageDokument2 SeitenSystem ImageQamaNoch keine Bewertungen
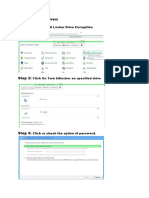
- Bit LockerDokument3 SeitenBit LockerQamaNoch keine Bewertungen
- 102 - Introduction To Mass Communication 1Dokument72 Seiten102 - Introduction To Mass Communication 1farhad ahmed100% (2)
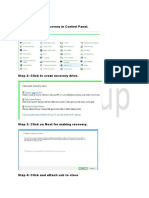
- RecoveryDokument3 SeitenRecoveryQamaNoch keine Bewertungen
- What Is Saas?Dokument3 SeitenWhat Is Saas?QamaNoch keine Bewertungen
- MMC1009 Intro To Mass Communications Section119F Cleland Spring 2018Dokument5 SeitenMMC1009 Intro To Mass Communications Section119F Cleland Spring 2018QamaNoch keine Bewertungen
- Decision Trees / NLPDokument27 SeitenDecision Trees / NLPQamaNoch keine Bewertungen
- DHCP in LinuxDokument2 SeitenDHCP in LinuxQamaNoch keine Bewertungen
- Intel IT Architecting SaaSDokument40 SeitenIntel IT Architecting SaaSQamaNoch keine Bewertungen
- 06 NaiveBayes ExampleDokument2 Seiten06 NaiveBayes Examplekakalott77Noch keine Bewertungen
- Chapter 4: Classification & Prediction: 4.1 Basic Concepts of Classification and Prediction 4.2 Decision Tree InductionDokument19 SeitenChapter 4: Classification & Prediction: 4.1 Basic Concepts of Classification and Prediction 4.2 Decision Tree InductionQamaNoch keine Bewertungen
- 06 NaiveBayes ExampleDokument2 Seiten06 NaiveBayes Examplekakalott77Noch keine Bewertungen
- IT-318: Cloud Computing: What Is The Cloud?Dokument68 SeitenIT-318: Cloud Computing: What Is The Cloud?QamaNoch keine Bewertungen
- Intel IT Architecting SaaSDokument10 SeitenIntel IT Architecting SaaSQamaNoch keine Bewertungen
- Intel IT Architecting SaaSDokument10 SeitenIntel IT Architecting SaaSQamaNoch keine Bewertungen
- Ingenico Telium ConfigurationDokument18 SeitenIngenico Telium ConfigurationUmesh Kumawat100% (2)
- Osy ReportDokument25 SeitenOsy ReportOmkar KhutwadNoch keine Bewertungen
- CS2 - VirtualizationDokument31 SeitenCS2 - VirtualizationAsmita KandarNoch keine Bewertungen
- HP Color LaserJet Managed MFP E87740Dokument129 SeitenHP Color LaserJet Managed MFP E87740Alves CarvalhoNoch keine Bewertungen
- MBRDokument24 SeitenMBRSaturnNoch keine Bewertungen
- SDA555 XFLDokument12 SeitenSDA555 XFLgigel1980Noch keine Bewertungen
- Lenovo 505Dokument47 SeitenLenovo 505pdg comNoch keine Bewertungen
- IDL-11098-01-A, USB - RS232 Driver InstallationDokument8 SeitenIDL-11098-01-A, USB - RS232 Driver InstallationNguyễn Văn TýNoch keine Bewertungen
- PIP Brochure (Email) Jan2010Dokument4 SeitenPIP Brochure (Email) Jan2010e33aticNoch keine Bewertungen
- Risc-16 Sequential ImplementationDokument11 SeitenRisc-16 Sequential ImplementationlamtalsiNoch keine Bewertungen
- CSS NCII ModuleDokument213 SeitenCSS NCII Moduletonet enteaNoch keine Bewertungen
- HP Color Laserjet Cm2320Nf Multifunction Printer Price: $699.00Dokument34 SeitenHP Color Laserjet Cm2320Nf Multifunction Printer Price: $699.00Matthew JohnsonNoch keine Bewertungen
- WINDOWS Driver InstallationDokument9 SeitenWINDOWS Driver Installationhilya qaanitaNoch keine Bewertungen
- DE1 Usermanual PDFDokument54 SeitenDE1 Usermanual PDFPaolaSabogalCdlmNoch keine Bewertungen
- Wagner Mining Catalog Pt2Dokument286 SeitenWagner Mining Catalog Pt2381tutNoch keine Bewertungen
- Pricelist Legalsize PDFDokument2 SeitenPricelist Legalsize PDFJimmy OrenaNoch keine Bewertungen
- Syllabus - CS2318 Section 251 Spring 2021Dokument7 SeitenSyllabus - CS2318 Section 251 Spring 2021David KimNoch keine Bewertungen
- Dataline User Manual: Container RefrigerationDokument80 SeitenDataline User Manual: Container RefrigerationUsman ShahNoch keine Bewertungen
- Problem 1 A) Considering The Number of Instructions Here To Be A Constant ADokument13 SeitenProblem 1 A) Considering The Number of Instructions Here To Be A Constant Akhang nguyenNoch keine Bewertungen
- Windows 2000 Printer SetupDokument1 SeiteWindows 2000 Printer SetupcepimancaNoch keine Bewertungen
- CompTIA A 220-1101Dokument171 SeitenCompTIA A 220-1101Hoàng Trần Huy100% (1)
- Kyocera FS 1035MFPDokument2 SeitenKyocera FS 1035MFPHemnath KjNoch keine Bewertungen
- Primary 4 IctDokument3 SeitenPrimary 4 IctAisha AnwarNoch keine Bewertungen
- OS Assignment 1&2 SolutionDokument6 SeitenOS Assignment 1&2 Solutionlokendra singhNoch keine Bewertungen
- Cpu SchedulingDokument6 SeitenCpu SchedulingMaAngelicaElimancoNoch keine Bewertungen
- Crash Log 1Dokument2 SeitenCrash Log 1nur ibrahimNoch keine Bewertungen
- Randomx Benchmarks For Monero Mining!Dokument1 SeiteRandomx Benchmarks For Monero Mining!beng LEENoch keine Bewertungen
- Paging and Page Replacement PoliciesDokument15 SeitenPaging and Page Replacement PoliciesAnusha BangeraNoch keine Bewertungen
- HP Zbook Firefly HP Elitebook 800Dokument1 SeiteHP Zbook Firefly HP Elitebook 800sale oneNoch keine Bewertungen
- Dell Studio 1558 (Quanta FM9B) DAFM9BMB6D0 - Quanta - Fm9b-D3a - Uma - 091012 PDFDokument60 SeitenDell Studio 1558 (Quanta FM9B) DAFM9BMB6D0 - Quanta - Fm9b-D3a - Uma - 091012 PDFSandeep DeshpandeNoch keine Bewertungen