Das könnte Ihnen auch gefallen
- Mat 540Dokument8 SeitenMat 540nequwan79Noch keine Bewertungen
- Hessian MatrixDokument3 SeitenHessian MatrixDesvia SafitriNoch keine Bewertungen
- Chapter 2 171Dokument118 SeitenChapter 2 171Wee Han ChiangNoch keine Bewertungen
- IGNOU - Lecture Notes - Linear AlgebraDokument29 SeitenIGNOU - Lecture Notes - Linear Algebraruchi21julyNoch keine Bewertungen
- Operation ManagementDokument202 SeitenOperation ManagementHimanshu Raj100% (1)
- Assignment-1 (Linear Algebra)Dokument3 SeitenAssignment-1 (Linear Algebra)DEBOJIT CHATTERJEENoch keine Bewertungen
- Ignou BCA Mathematics Block 2Dokument134 SeitenIgnou BCA Mathematics Block 2JaheerNoch keine Bewertungen
- Practice - Permutations and Combinations Problems - Ncert Chapter 7 Solutions Part - 50 SolutionsDokument14 SeitenPractice - Permutations and Combinations Problems - Ncert Chapter 7 Solutions Part - 50 Solutionsalroy dcruzNoch keine Bewertungen
- Sma2100 Discrete MathematicsDokument78 SeitenSma2100 Discrete MathematicsOloo Pundit100% (1)
- Sma 2101 Calculus IDokument4 SeitenSma 2101 Calculus ISambili TonnyNoch keine Bewertungen
- LP SolveDokument13 SeitenLP Solvediana.yanti100% (4)
- LPPDokument84 SeitenLPPmandy021190Noch keine Bewertungen
- W3 ProbabilityDokument55 SeitenW3 ProbabilityDanny MannoNoch keine Bewertungen
- Sample Problems in or and StatisticDokument6 SeitenSample Problems in or and StatisticHinata UzumakiNoch keine Bewertungen
- Assignment 1: Descriptive Statistics (10 Marks)Dokument4 SeitenAssignment 1: Descriptive Statistics (10 Marks)Malik Faizan100% (1)
- Laws of ProbabilityDokument31 SeitenLaws of ProbabilitySherazNoch keine Bewertungen
- MB0032 Operations ResearchDokument38 SeitenMB0032 Operations ResearchSaurabh MIshra12100% (1)
- OR PPT On AssignmentDokument20 SeitenOR PPT On AssignmentjanakNoch keine Bewertungen
- Lecture 11 Binomial Probability DistributionDokument10 SeitenLecture 11 Binomial Probability DistributionArshad AliNoch keine Bewertungen
- Seatwork 1Dokument3 SeitenSeatwork 1Ellaine NacisNoch keine Bewertungen
- Gauss Seidel MethodRTFDokument5 SeitenGauss Seidel MethodRTFChristed aljo barrogaNoch keine Bewertungen
- CHE 555 Numerical DifferentiationDokument9 SeitenCHE 555 Numerical DifferentiationHidayah Humaira100% (1)
- CH 02 Sec 02Dokument14 SeitenCH 02 Sec 02datdude1415Noch keine Bewertungen
- Linear ProgrammingDokument37 SeitenLinear ProgramminglaestatNoch keine Bewertungen
- GATE Problems in ProbabilityDokument12 SeitenGATE Problems in ProbabilitySureshNoch keine Bewertungen
- Defuzzification Techniques: Debasis Samanta (IIT Kharagpur)Dokument54 SeitenDefuzzification Techniques: Debasis Samanta (IIT Kharagpur)Foram PatelNoch keine Bewertungen
- Introduction To Machine Learning Week 2 AssignmentDokument8 SeitenIntroduction To Machine Learning Week 2 AssignmentAkash barapatreNoch keine Bewertungen
- Tutorial ProblemsDokument74 SeitenTutorial ProblemsBhaswar MajumderNoch keine Bewertungen
- Practice LPDokument9 SeitenPractice LPKetiNoch keine Bewertungen
- Practical Exercise Epipolar GeometryDokument3 SeitenPractical Exercise Epipolar GeometrydansileshiNoch keine Bewertungen
- LabNotes LatestDokument74 SeitenLabNotes LatestAniketRaikwarNoch keine Bewertungen
- BJJBDokument8 SeitenBJJBDewi silaenNoch keine Bewertungen
- LinearDokument46 SeitenLinearSheikh Riasat100% (1)
- Chapter 4Dokument27 SeitenChapter 4Chandrahasa Reddy ThatimakulaNoch keine Bewertungen
- Group 4: Answer Questions Number 1 To 6 Using The Given DataDokument4 SeitenGroup 4: Answer Questions Number 1 To 6 Using The Given DataDame Chala100% (1)
- Topic 6 Simple Linear RegressionDokument57 SeitenTopic 6 Simple Linear Regressionmilk teaNoch keine Bewertungen
- pt-1 PracticeDokument3 Seitenpt-1 PracticeAmal A SNoch keine Bewertungen
- Assignment 1-CalculusDokument3 SeitenAssignment 1-CalculusFarith AhmadNoch keine Bewertungen
- Observing Interaction - An Introduction To Sequential AnalysisDokument221 SeitenObserving Interaction - An Introduction To Sequential AnalysisVladimiro G. Lourenço100% (1)
- Lecture 2Dokument9 SeitenLecture 2fujinlim98Noch keine Bewertungen
- Special Topics Exam 8 Differential EquationDokument2 SeitenSpecial Topics Exam 8 Differential EquationEme DumlaoNoch keine Bewertungen
- List of Formula - Managerial StatisticsDokument6 SeitenList of Formula - Managerial Statisticsmahendra pratap singhNoch keine Bewertungen
- Numerical Methods Paper - 2013Dokument7 SeitenNumerical Methods Paper - 2013Sourav PandaNoch keine Bewertungen
- Matrices Solved ProblemsDokument19 SeitenMatrices Solved Problemsvivek patel100% (1)
- Arch Garch AssignmentDokument5 SeitenArch Garch AssignmentSurbhiVijhaniNoch keine Bewertungen
- Probability (Merged)Dokument39 SeitenProbability (Merged)Nilanjan KunduNoch keine Bewertungen
- RCBD Anova Notes (III)Dokument13 SeitenRCBD Anova Notes (III)yagnasreeNoch keine Bewertungen
- Gallery of Named Graphs: With Tkz-Berge - Sty by Alain MatthesDokument104 SeitenGallery of Named Graphs: With Tkz-Berge - Sty by Alain MatthesneoferneyNoch keine Bewertungen
- Pattern - Assigment1Dokument2 SeitenPattern - Assigment1gizemyarenNoch keine Bewertungen
- Encoded Problems (StatsFinals)Dokument4 SeitenEncoded Problems (StatsFinals)HueyNoch keine Bewertungen
- Data OrganizationDokument69 SeitenData OrganizationHazelNoch keine Bewertungen
- Lec 2Dokument43 SeitenLec 2Muhammad AbubakerNoch keine Bewertungen
- Statistical Analysis With Software Application - Week2Dokument76 SeitenStatistical Analysis With Software Application - Week2Danny WeeNoch keine Bewertungen
- Chapter 2part1Dokument74 SeitenChapter 2part1Waikin YongNoch keine Bewertungen
- Adv Stat Data PresentationDokument57 SeitenAdv Stat Data Presentationjhoana patunganNoch keine Bewertungen
- BBS11 PPT ch02Dokument42 SeitenBBS11 PPT ch02GUNJAN YADAVNoch keine Bewertungen
- Collecting Organizing and Presentation of DataDokument6 SeitenCollecting Organizing and Presentation of DataYumeko SNoch keine Bewertungen
- IntroductionDokument37 SeitenIntroductionzinmarNoch keine Bewertungen
- 4.1 Data ManagementDokument6 Seiten4.1 Data ManagementAngela 18 PhotosNoch keine Bewertungen
- Benefits of The Preservation TechniquesDokument4 SeitenBenefits of The Preservation TechniquesFadhlin SakinahNoch keine Bewertungen
- Result & Discussion - BlanchingDokument7 SeitenResult & Discussion - BlanchingFadhlin SakinahNoch keine Bewertungen
- Result & Discussion - BlanchingDokument7 SeitenResult & Discussion - BlanchingFadhlin SakinahNoch keine Bewertungen
- CITATION Mas19 /L 1033Dokument3 SeitenCITATION Mas19 /L 1033Fadhlin SakinahNoch keine Bewertungen
- Benefits of The Preservation TechniquesDokument4 SeitenBenefits of The Preservation TechniquesFadhlin SakinahNoch keine Bewertungen
- Chapter 3 MethodDokument3 SeitenChapter 3 MethodFadhlin SakinahNoch keine Bewertungen
- Exp 1 Complete - JAMDokument14 SeitenExp 1 Complete - JAMFadhlin Sakinah50% (2)
- Result & Discussion - BlanchingDokument7 SeitenResult & Discussion - BlanchingFadhlin SakinahNoch keine Bewertungen
- Final Lab Report - SeparationDokument11 SeitenFinal Lab Report - SeparationFadhlin SakinahNoch keine Bewertungen
- Method On How To Perform Pour Plate Method (No Need Dilution)Dokument1 SeiteMethod On How To Perform Pour Plate Method (No Need Dilution)Fadhlin SakinahNoch keine Bewertungen
- Report-Food ChemDokument13 SeitenReport-Food ChemFadhlin SakinahNoch keine Bewertungen
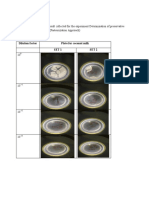
- The Data Below Shows The Result Collected For The Experiment Determination of Preservative Effect On Microbial Growth (Pasteurization Approach)Dokument4 SeitenThe Data Below Shows The Result Collected For The Experiment Determination of Preservative Effect On Microbial Growth (Pasteurization Approach)Fadhlin SakinahNoch keine Bewertungen
- Description of Food Addtictive Used in Cheese MakingDokument3 SeitenDescription of Food Addtictive Used in Cheese MakingFadhlin SakinahNoch keine Bewertungen
- Food MicroDokument1 SeiteFood MicroFadhlin SakinahNoch keine Bewertungen
- Universiti Kuala Lumpur: Attach This Coversheet As The Cover of Your Submission. All Sections Must Be CompletedDokument12 SeitenUniversiti Kuala Lumpur: Attach This Coversheet As The Cover of Your Submission. All Sections Must Be CompletedFadhlin SakinahNoch keine Bewertungen
- OBJECTIVE - Yeast and MouldDokument1 SeiteOBJECTIVE - Yeast and MouldFadhlin SakinahNoch keine Bewertungen
- Last Lab ReportDokument20 SeitenLast Lab ReportFadhlin SakinahNoch keine Bewertungen
- Universiti Kuala Lumpur: Malaysian Institute of Chemical & Bioengineering TechnologyDokument8 SeitenUniversiti Kuala Lumpur: Malaysian Institute of Chemical & Bioengineering TechnologyFadhlin SakinahNoch keine Bewertungen
- Test Food AnalysisDokument12 SeitenTest Food AnalysisFadhlin SakinahNoch keine Bewertungen
- Lab Reports Submission Form Jan 2020Dokument15 SeitenLab Reports Submission Form Jan 2020Fadhlin SakinahNoch keine Bewertungen
- OBJECTIVE - Exp 1Dokument1 SeiteOBJECTIVE - Exp 1Fadhlin SakinahNoch keine Bewertungen
- Normal Distribution FunctionDokument1 SeiteNormal Distribution FunctionFadhlin SakinahNoch keine Bewertungen
- Lab Reports Submission Form Jan 2020Dokument15 SeitenLab Reports Submission Form Jan 2020Fadhlin SakinahNoch keine Bewertungen
- Separation For LifeDokument1 SeiteSeparation For LifeFadhlin SakinahNoch keine Bewertungen
- Lab Technical Report Template 2019Dokument2 SeitenLab Technical Report Template 2019Fadhlin SakinahNoch keine Bewertungen
- Universiti Kuala Lumpur Malaysian Institute of Chemical & Bioengineering TechnologyDokument5 SeitenUniversiti Kuala Lumpur Malaysian Institute of Chemical & Bioengineering TechnologyFadhlin SakinahNoch keine Bewertungen
- Vitamin CDokument7 SeitenVitamin CFadhlin SakinahNoch keine Bewertungen
- Chapter 2 Introduction To ProbabilityDokument40 SeitenChapter 2 Introduction To ProbabilityFadhlin SakinahNoch keine Bewertungen
- Food ChemDokument2 SeitenFood ChemFadhlin SakinahNoch keine Bewertungen
- Using Impact IX49 and 61 With Nektar DAW Integration 1.1Dokument21 SeitenUsing Impact IX49 and 61 With Nektar DAW Integration 1.1Eko SeynNoch keine Bewertungen
- Plane TrigonometryDokument545 SeitenPlane Trigonometrygnavya680Noch keine Bewertungen
- Logarithms Functions: Background Information Subject: Grade Band: DurationDokument16 SeitenLogarithms Functions: Background Information Subject: Grade Band: DurationJamaica PondaraNoch keine Bewertungen
- Kazi Shafikull IslamDokument3 SeitenKazi Shafikull IslamKazi Shafikull IslamNoch keine Bewertungen
- Libro INGLÉS BÁSICO IDokument85 SeitenLibro INGLÉS BÁSICO IRandalHoyos100% (1)
- Pressure-Dependent Leak Detection Model and Its Application To A District Water SystemDokument13 SeitenPressure-Dependent Leak Detection Model and Its Application To A District Water SystemManjul KothariNoch keine Bewertungen
- Zilog Z80-SIO Technical Manual TextDokument58 SeitenZilog Z80-SIO Technical Manual Textprada.rizzoplcNoch keine Bewertungen
- Lesson 2 (Probability of An Event)Dokument4 SeitenLesson 2 (Probability of An Event)MarlNoch keine Bewertungen
- Changing Historical Perspectives On The Nazi DictatorshipDokument9 SeitenChanging Historical Perspectives On The Nazi Dictatorshipuploadimage666Noch keine Bewertungen
- Swanand 2009Dokument3 SeitenSwanand 2009maverick2929Noch keine Bewertungen
- ADAMS/View Function Builder: Run-Time FunctionsDokument185 SeitenADAMS/View Function Builder: Run-Time FunctionsSrinivasarao YenigallaNoch keine Bewertungen
- Zoom g2 1nu Manual Do Utilizador PDFDokument56 SeitenZoom g2 1nu Manual Do Utilizador PDFEliude Gonçalves FerreiraNoch keine Bewertungen
- Tree Based Machine Learning Algorithms Decision Trees Random Forests and Boosting B0756FGJCPDokument109 SeitenTree Based Machine Learning Algorithms Decision Trees Random Forests and Boosting B0756FGJCPJulio Davalos Vasquez100% (1)
- Help SIMARIS Project 3.1 enDokument61 SeitenHelp SIMARIS Project 3.1 enVictor VignolaNoch keine Bewertungen
- Distillation Column DesignDokument42 SeitenDistillation Column DesignAakanksha Raul100% (1)
- ITP - Plaster WorkDokument1 SeiteITP - Plaster Workmahmoud ghanemNoch keine Bewertungen
- Tensile Strength of Ferro Cement With Respect To Specific SurfaceDokument3 SeitenTensile Strength of Ferro Cement With Respect To Specific SurfaceheminNoch keine Bewertungen
- Column Buckling TestDokument8 SeitenColumn Buckling TestWiy GuomNoch keine Bewertungen
- Quemador BrahmaDokument4 SeitenQuemador BrahmaClaudio VerdeNoch keine Bewertungen
- AnimDessin2 User Guide 01Dokument2 SeitenAnimDessin2 User Guide 01rendermanuser100% (1)
- DICKSON KT800/802/803/804/856: Getting StartedDokument6 SeitenDICKSON KT800/802/803/804/856: Getting StartedkmpoulosNoch keine Bewertungen
- S010T1Dokument1 SeiteS010T1DUCNoch keine Bewertungen
- SR# Call Type A-Party B-Party Date & Time Duration Cell ID ImeiDokument12 SeitenSR# Call Type A-Party B-Party Date & Time Duration Cell ID ImeiSaifullah BalochNoch keine Bewertungen
- Review Rachna WasteDokument9 SeitenReview Rachna WasteSanjeet DuhanNoch keine Bewertungen
- Each Life Raft Must Contain A Few ItemsDokument2 SeitenEach Life Raft Must Contain A Few ItemsMar SundayNoch keine Bewertungen
- Planetary Yogas in Astrology: O.P.Verma, IndiaDokument7 SeitenPlanetary Yogas in Astrology: O.P.Verma, IndiaSaptarishisAstrology50% (2)
- Gastone Petrini: Strutture e Costruzioni Autarchiche Di Legno in Italia e Colonie Caratteri e CriterDokument9 SeitenGastone Petrini: Strutture e Costruzioni Autarchiche Di Legno in Italia e Colonie Caratteri e CriterPier Pasquale TrausiNoch keine Bewertungen
- Retirement 01Dokument2 SeitenRetirement 01Nonema Casera JuarezNoch keine Bewertungen
- Machine Design REE 302: CH 1: Introduction To Mechanical Engineering DesignDokument26 SeitenMachine Design REE 302: CH 1: Introduction To Mechanical Engineering DesignDull PersonNoch keine Bewertungen
- Barack ObamaDokument3 SeitenBarack ObamaVijay KumarNoch keine Bewertungen