Das könnte Ihnen auch gefallen
- Soul To Squeeze Bass Tab by Red Hot Chili PeppersDokument1 SeiteSoul To Squeeze Bass Tab by Red Hot Chili PeppersMelvil GratecapNoch keine Bewertungen
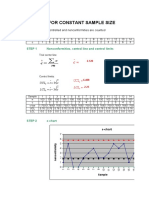
- C-Chart For Constant Sample Size: 18 Samples Are Controlled and Nonconformities Are CountedDokument2 SeitenC-Chart For Constant Sample Size: 18 Samples Are Controlled and Nonconformities Are Countedamrt3505Noch keine Bewertungen
- Bai 4Dokument13 SeitenBai 4van hoanNoch keine Bewertungen
- Páginas Desdep64x - Parte3-2Dokument100 SeitenPáginas Desdep64x - Parte3-2Misael CruzNoch keine Bewertungen
- 2024 NCAA Men's Blank BracketDokument1 Seite2024 NCAA Men's Blank BracketThe Kansas City StarNoch keine Bewertungen
- Directed Graphs: Digraph Search Transitive Closure Topological Sort Strong ComponentsDokument47 SeitenDirected Graphs: Digraph Search Transitive Closure Topological Sort Strong ComponentsAlexandre ScalzittiNoch keine Bewertungen
- March MadnessDokument1 SeiteMarch MadnessD PatelNoch keine Bewertungen
- 2024 NCAA Women's Blank BracketDokument1 Seite2024 NCAA Women's Blank BracketThe Kansas City StarNoch keine Bewertungen
- UnicornMask ForKids PolygonalPaperBoat StasiaShaDokument3 SeitenUnicornMask ForKids PolygonalPaperBoat StasiaShajamiliobispoNoch keine Bewertungen
- 2008 Automation Summit A Users Conference: Presenter: CompanyDokument16 Seiten2008 Automation Summit A Users Conference: Presenter: Companymusic4andrsNoch keine Bewertungen
- TGL KG Total Keterangan TGL KG Total TGL KG TotalDokument1 SeiteTGL KG Total Keterangan TGL KG Total TGL KG TotalzaenalNoch keine Bewertungen
- 7-Using Similar Polygons PDFDokument4 Seiten7-Using Similar Polygons PDFDeborah EstraneroNoch keine Bewertungen
- 7-Using Similar Polygons PDFDokument4 Seiten7-Using Similar Polygons PDFFitri KhumairohNoch keine Bewertungen
- District ChartDokument1 SeiteDistrict ChartshreveporttimesNoch keine Bewertungen
- Handling Over DocsDokument304 SeitenHandling Over DocsShafiulNoch keine Bewertungen
- Simbologia Quant.: 06 Placa de Led de Embutir Cor 4000K 15Dokument1 SeiteSimbologia Quant.: 06 Placa de Led de Embutir Cor 4000K 15Helder MoraisNoch keine Bewertungen
- Gujarat Technological University (Diploma Ii-Sem July-10) : Institute Wise Student % Having Spi 7Dokument4 SeitenGujarat Technological University (Diploma Ii-Sem July-10) : Institute Wise Student % Having Spi 7Paramjit Singh SahotaNoch keine Bewertungen
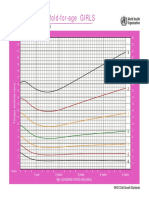
- Curvas PT NiñasDokument1 SeiteCurvas PT NiñasJuan FuentesNoch keine Bewertungen
- King Fahd University of Petroleum and Minerals College of Computing and MathematicsDokument2 SeitenKing Fahd University of Petroleum and Minerals College of Computing and MathematicsAbdullah AlOmarNoch keine Bewertungen
- NT 88407Dokument2 SeitenNT 88407Jesus SilvaNoch keine Bewertungen
- Report Monthly 4G NS Banten DEC 2017Dokument26 SeitenReport Monthly 4G NS Banten DEC 2017ESkudaNoch keine Bewertungen
- June 17 26 s001 PDFDokument9 SeitenJune 17 26 s001 PDFBetul RojeabNoch keine Bewertungen
- Spelling, Grade 1: Strengthening Basic Skills with Jokes, Comics, and RiddlesVon EverandSpelling, Grade 1: Strengthening Basic Skills with Jokes, Comics, and RiddlesNoch keine Bewertungen
- A B C de F G: Gspublisherversion 0.37.100.100Dokument1 SeiteA B C de F G: Gspublisherversion 0.37.100.100a gildas dossaNoch keine Bewertungen
- Gorkha EQ - 2 - KECDokument35 SeitenGorkha EQ - 2 - KECMishal LimbuNoch keine Bewertungen
- 7 Grading Sheet R1Dokument1 Seite7 Grading Sheet R1Rodjan RajanNoch keine Bewertungen
- Coolant Flow Vs External RestrictionDokument2 SeitenCoolant Flow Vs External RestrictionJhon Hever Benitez HernandezNoch keine Bewertungen
- C:/DATA HPLC/PESTICIDAS/Data/07-10-2019 R4 L3.dat, DAD-CH1 220 NM C:/DATA HPLC/PESTICIDAS/Data/07-10-2019 R4 L2.dat, DAD-CH1 220 NMDokument1 SeiteC:/DATA HPLC/PESTICIDAS/Data/07-10-2019 R4 L3.dat, DAD-CH1 220 NM C:/DATA HPLC/PESTICIDAS/Data/07-10-2019 R4 L2.dat, DAD-CH1 220 NMadolfo olmosNoch keine Bewertungen
- Eaton 771 Parts BreakdownDokument8 SeitenEaton 771 Parts BreakdownMatthew NeubergerNoch keine Bewertungen
- Arc Flash Project: Qualified and AdvantageousDokument2 SeitenArc Flash Project: Qualified and AdvantageousSalman FadillahNoch keine Bewertungen
- Si 1560Dokument2 SeitenSi 1560Brian FuentesNoch keine Bewertungen
- de Voetpadkloof Map ADokument1 Seitede Voetpadkloof Map AStephenNoch keine Bewertungen
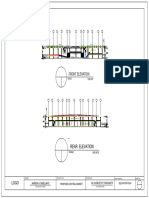
- Elevation 1 AdDokument1 SeiteElevation 1 AdMaresa Namocot SabellanoNoch keine Bewertungen
- TB02200004E - Tab 6Dokument40 SeitenTB02200004E - Tab 6Ayman SaberNoch keine Bewertungen
- Licks From Space IDokument3 SeitenLicks From Space Igreyseraphim7Noch keine Bewertungen
- Monthly patient visits and deliveries at Cipatujah Community Health Center in 2020Dokument1 SeiteMonthly patient visits and deliveries at Cipatujah Community Health Center in 2020Lia MarlianaNoch keine Bewertungen
- TWH54NRH Spare Parts Sheet942016221232Dokument2 SeitenTWH54NRH Spare Parts Sheet942016221232Heitor RibeiroNoch keine Bewertungen
- Gryffindor Knit Hat PatternDokument3 SeitenGryffindor Knit Hat Patternanetamajkut173Noch keine Bewertungen
- Drawing Untuk Flash Chamber (1) - ModelDokument1 SeiteDrawing Untuk Flash Chamber (1) - Modelsukma.mputraNoch keine Bewertungen
- t2 M 2266 Coordinate Pictures Activity SheetsDokument4 Seitent2 M 2266 Coordinate Pictures Activity SheetsElegbede AnthoniaNoch keine Bewertungen
- Tinte Moa - 100yd - Mod3 PDFDokument1 SeiteTinte Moa - 100yd - Mod3 PDFCiprian OpreaNoch keine Bewertungen
- ANSAMBLU AC AXA REFACERE-Model2Dokument1 SeiteANSAMBLU AC AXA REFACERE-Model2Iulian NgiNoch keine Bewertungen
- DDJ-SB List of MIDI Messages EDokument2 SeitenDDJ-SB List of MIDI Messages EKuba PaszkiewiczNoch keine Bewertungen
- Drawing Axe Piece CoupanteDokument1 SeiteDrawing Axe Piece Coupantemed AtifiNoch keine Bewertungen
- 51 Advanced Rock Licks Tab BookpdfDokument14 Seiten51 Advanced Rock Licks Tab Bookpdftvis MusicNoch keine Bewertungen
- 4x3 RAM designDokument2 Seiten4x3 RAM designRindo Koba KobayashiNoch keine Bewertungen
- Z-Transforms and Transfer FunctionsDokument85 SeitenZ-Transforms and Transfer FunctionsRashedul IslamNoch keine Bewertungen
- Weekdays: Weekdays Graphical Representation ScheduleDokument3 SeitenWeekdays: Weekdays Graphical Representation ScheduleMavrix AgustinNoch keine Bewertungen
- CBX I PestanaDokument1 SeiteCBX I PestanaZack BackNoch keine Bewertungen
- One Bold Move a Day: Meaningful Actions Women Can Take to Fulfill Their Leadership and Career PotentialVon EverandOne Bold Move a Day: Meaningful Actions Women Can Take to Fulfill Their Leadership and Career PotentialNoch keine Bewertungen
- 0,5 - 1mm Wire: Lower Laser CannonDokument1 Seite0,5 - 1mm Wire: Lower Laser CannonJaime Silva OrdenesNoch keine Bewertungen
- AT-AT Walker 2014 - 1Dokument1 SeiteAT-AT Walker 2014 - 1AlbertoNoch keine Bewertungen
- 周杰伦暗黑三部曲Dokument2 Seiten周杰伦暗黑三部曲mercuryNoch keine Bewertungen
- Patient complaint and treatment scheduleDokument1 SeitePatient complaint and treatment scheduleRiyan saputraNoch keine Bewertungen
- Tambahan KerjaDokument1 SeiteTambahan KerjaRiyan saputraNoch keine Bewertungen
- RX 125 Parts CatalogDokument101 SeitenRX 125 Parts CatalogCarlos Eduardo RochaNoch keine Bewertungen
- DIF28!3!02Nikolchina 1ppDokument25 SeitenDIF28!3!02Nikolchina 1ppVirginia KirovaNoch keine Bewertungen
- Multifresh: User ManualDokument144 SeitenMultifresh: User ManualAt Yugovic100% (4)
- Fito Paez-Mariposa TecnicolorDokument10 SeitenFito Paez-Mariposa TecnicolorGuadalupe GiraudiNoch keine Bewertungen
- Danfoss VFD - Pmd2200 Cabinet - DrawingDokument1 SeiteDanfoss VFD - Pmd2200 Cabinet - DrawingJose DiazNoch keine Bewertungen
- 1.distributed Computing - SS ZG526 - 2018Dokument7 Seiten1.distributed Computing - SS ZG526 - 2018aviezzzNoch keine Bewertungen
- Assignment 1.2 CHAPTER 1Dokument4 SeitenAssignment 1.2 CHAPTER 1Scholar MacayNoch keine Bewertungen
- A MPI Parallel Algorithm For The Maximum Flow ProblemDokument4 SeitenA MPI Parallel Algorithm For The Maximum Flow ProblemGRUNDOPUNKNoch keine Bewertungen
- (Signal Processing and Communications 13) Hu, Yu Hen - Programmable Digital Signal Processors - Architecture, Programming, and App PDFDokument386 Seiten(Signal Processing and Communications 13) Hu, Yu Hen - Programmable Digital Signal Processors - Architecture, Programming, and App PDFGururaj BandaNoch keine Bewertungen
- Isilon Library Scale Out Storage High Performance ApplicationsDokument32 SeitenIsilon Library Scale Out Storage High Performance ApplicationsLarry ShoemakerNoch keine Bewertungen
- Computer Studies Module 1 - Concepts of IctDokument149 SeitenComputer Studies Module 1 - Concepts of IctDavid Mututa100% (1)
- Revision Worksheet AnswersDokument6 SeitenRevision Worksheet AnswersOmarNoch keine Bewertungen
- Bit SliceDokument101 SeitenBit SlicebinkyfishNoch keine Bewertungen
- Use Case DiagramsDokument49 SeitenUse Case Diagramsanon_583484017Noch keine Bewertungen
- Fgssjoin: A GPU-based Algorithm For Set Similarity Joins: Rafael David QuirinoDokument40 SeitenFgssjoin: A GPU-based Algorithm For Set Similarity Joins: Rafael David QuirinoRafael QuirinoNoch keine Bewertungen
- B.Tech (ECE) 5th SemDokument12 SeitenB.Tech (ECE) 5th Semak182007Noch keine Bewertungen
- XX Chapter16 InstructionLevelParallelismAndSuperscalarProcessors PDFDokument90 SeitenXX Chapter16 InstructionLevelParallelismAndSuperscalarProcessors PDFmheba11Noch keine Bewertungen
- Lecture 1 - Fundamentals of Distributed SystemDokument13 SeitenLecture 1 - Fundamentals of Distributed SystemCyrus kipronoNoch keine Bewertungen
- TelemacDokument6 SeitenTelemacArturo Campusano BaltazarNoch keine Bewertungen
- AUTODYN Parallel Processing v15Dokument46 SeitenAUTODYN Parallel Processing v15mindertNoch keine Bewertungen
- Gopallapuram, Renigunta-Srikalahasti Road, Tirupati: by B. Hari Prasad, Asst - ProfDokument18 SeitenGopallapuram, Renigunta-Srikalahasti Road, Tirupati: by B. Hari Prasad, Asst - Profbhariprasad_mscNoch keine Bewertungen
- Direct Numerical Simulation of Turbulent Flow in A Square Duct Using A Graphics Processing Unit (GPU)Dokument14 SeitenDirect Numerical Simulation of Turbulent Flow in A Square Duct Using A Graphics Processing Unit (GPU)Khalil LasferNoch keine Bewertungen
- CS8491 Ca Unit 4Dokument32 SeitenCS8491 Ca Unit 4Vasuki rameshNoch keine Bewertungen
- Flops Memory Parallel ProcessingDokument8 SeitenFlops Memory Parallel ProcessingRonaldNoch keine Bewertungen
- Artificial Vision For RobotsDokument228 SeitenArtificial Vision For RobotsefrainNoch keine Bewertungen
- Gpu Computing Gems Jade PDFDokument3 SeitenGpu Computing Gems Jade PDFTrevorNoch keine Bewertungen
- CPS 5401syllabusDokument5 SeitenCPS 5401syllabusMike MyersNoch keine Bewertungen
- Multiple Integrals and Probability: A Numerical Exploration and an Introduction to MPIDokument15 SeitenMultiple Integrals and Probability: A Numerical Exploration and an Introduction to MPI姚逸凡Noch keine Bewertungen
- Unit 3 - Operating System - WWW - Rgpvnotes.inDokument38 SeitenUnit 3 - Operating System - WWW - Rgpvnotes.inGirraj DohareNoch keine Bewertungen
- Microprocessors in 2020Dokument4 SeitenMicroprocessors in 2020Brian RichardsNoch keine Bewertungen
- GCN Architecture WhitepaperDokument18 SeitenGCN Architecture WhitepaperИлија ПетровићNoch keine Bewertungen
- Module 2&3Dokument127 SeitenModule 2&3Mrs. SUMANGALA B CSENoch keine Bewertungen
- Multi-Processor-Parallel Processing PDFDokument12 SeitenMulti-Processor-Parallel Processing PDFBarnali DuttaNoch keine Bewertungen
- Net 4003 Course Outline 2014Dokument4 SeitenNet 4003 Course Outline 2014Robert BarrettNoch keine Bewertungen
- Lecture 2 - Computer Generations and ClassificationsDokument12 SeitenLecture 2 - Computer Generations and ClassificationsbinsalweNoch keine Bewertungen