Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Barossa ATV - Quaterback 250 E - Spare Parts List PDFDokument45 SeitenBarossa ATV - Quaterback 250 E - Spare Parts List PDFgabysurfNoch keine Bewertungen
- Name: Amir Bin Rossaifuddin Id: 2016307153 Group: Emd2M2ADokument2 SeitenName: Amir Bin Rossaifuddin Id: 2016307153 Group: Emd2M2AamirossaifuddinNoch keine Bewertungen
- Seismic Assessment of RC Building According To ATC 40, FEMA 356 and FEMA 440Dokument10 SeitenSeismic Assessment of RC Building According To ATC 40, FEMA 356 and FEMA 440sobah assidqiNoch keine Bewertungen
- Is 7098 P-1 (1988) PDFDokument21 SeitenIs 7098 P-1 (1988) PDFAmar PatwalNoch keine Bewertungen
- AZ-Edit User ManualDokument288 SeitenAZ-Edit User Manualdjjd40Noch keine Bewertungen
- Yousif Yassin PDFDokument124 SeitenYousif Yassin PDFJAVIYAROSNoch keine Bewertungen
- Ultimate Holding Capacity Drag mx5Dokument1 SeiteUltimate Holding Capacity Drag mx5Luana MarchioriNoch keine Bewertungen
- Phase IIIDokument11 SeitenPhase IIIAjun FranklinNoch keine Bewertungen
- Reverse LogisticsDokument18 SeitenReverse Logisticsiazeem2401630Noch keine Bewertungen
- Water Cooled Flooded Vertical Screw ChillersDokument96 SeitenWater Cooled Flooded Vertical Screw ChillersaftabNoch keine Bewertungen
- Cruise Control (3RZ-FE)Dokument6 SeitenCruise Control (3RZ-FE)Esteban LefontNoch keine Bewertungen
- True 63Dokument2 SeitenTrue 63stefanygomezNoch keine Bewertungen
- S11ES Ig 16Dokument4 SeitenS11ES Ig 16allanrnmanalotoNoch keine Bewertungen
- ExpertFit Student Version OverviewDokument23 SeitenExpertFit Student Version Overviewlucas matheusNoch keine Bewertungen
- Century Lookbook CatalogueDokument162 SeitenCentury Lookbook Cataloguefwd2datta50% (2)
- York R410ADokument2 SeitenYork R410AArabiat76Noch keine Bewertungen
- Syntel Mock 2Dokument18 SeitenSyntel Mock 2Ashutosh MauryaNoch keine Bewertungen
- 24 - Counting of Bottles - Solution - ENGDokument3 Seiten24 - Counting of Bottles - Solution - ENGhaftu gideyNoch keine Bewertungen
- Six Stroke EngineDokument19 SeitenSix Stroke EngineSai deerajNoch keine Bewertungen
- Arduino Water Flow Sensor CodeDokument6 SeitenArduino Water Flow Sensor CodeNasruddin AVNoch keine Bewertungen
- 378 and 378 HT SeriesDokument2 Seiten378 and 378 HT SeriesTim Stubbs100% (2)
- DeltaBox Catalogue UK 2021Dokument37 SeitenDeltaBox Catalogue UK 2021Philip G. SantiagoNoch keine Bewertungen
- Reference Letter of DR Zaka EmadDokument2 SeitenReference Letter of DR Zaka EmadRMRE UETNoch keine Bewertungen
- 2c - Types of Stone, Brick and Block MasonryDokument20 Seiten2c - Types of Stone, Brick and Block MasonryZeeshan ShoukatNoch keine Bewertungen
- Artemis Data SheetDokument2 SeitenArtemis Data SheetmahmoudNoch keine Bewertungen
- WS 4 Minutes - 2.9.2019Dokument3 SeitenWS 4 Minutes - 2.9.2019Andrea KakuruNoch keine Bewertungen
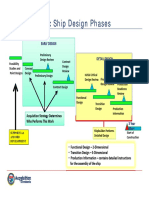
- Basic Ship Design PhasesDokument1 SeiteBasic Ship Design PhasesJhon GreigNoch keine Bewertungen
- ANCAP Corporate Design GuidelinesDokument20 SeitenANCAP Corporate Design GuidelineshazopmanNoch keine Bewertungen
- PanasonicBatteries NI-MH HandbookDokument25 SeitenPanasonicBatteries NI-MH HandbooktlusinNoch keine Bewertungen
- I Know Many BeginnersDokument5 SeitenI Know Many BeginnersOsmar Tavares JuNoch keine Bewertungen