Das könnte Ihnen auch gefallen
- Lecture 5Dokument14 SeitenLecture 5Waseem AbbasNoch keine Bewertungen
- Seismic Refraction LabDokument8 SeitenSeismic Refraction Labmemo alfaisal100% (1)
- Math BookletDokument77 SeitenMath BookletAhmed el-fekyNoch keine Bewertungen
- Capacitor 0.1 UfDokument3 SeitenCapacitor 0.1 UfAndrés JassoNoch keine Bewertungen
- Lecture # 1Dokument22 SeitenLecture # 1Muddassar AliNoch keine Bewertungen
- 25 Mattekim (Version 1)Dokument4 Seiten25 Mattekim (Version 1)Andre DianataNoch keine Bewertungen
- Anexo 3Dokument8 SeitenAnexo 3Lendy Parra100% (1)
- Assignment 2 PDFDokument9 SeitenAssignment 2 PDFsarNoch keine Bewertungen
- 2022-09-12 Tutorial 2 Life Insurance MathsDokument3 Seiten2022-09-12 Tutorial 2 Life Insurance MathshimeshNoch keine Bewertungen
- Topic 1 - Numbers and Operation - Year 4 (KSSR)Dokument25 SeitenTopic 1 - Numbers and Operation - Year 4 (KSSR)Mahshadevi VijayanNoch keine Bewertungen
- CAED101 - DE CASTRO - ACN1 - Network Model Transshipment Problem QuizDokument3 SeitenCAED101 - DE CASTRO - ACN1 - Network Model Transshipment Problem QuizIra Grace De CastroNoch keine Bewertungen
- 6-Egyptian Code For LoadsDokument13 Seiten6-Egyptian Code For Loadsebrahimmousa9999Noch keine Bewertungen
- Mechanical Operations (CH31007 and CH21205) Assignment: InstructionsDokument5 SeitenMechanical Operations (CH31007 and CH21205) Assignment: InstructionsHarsh GuptaNoch keine Bewertungen
- Digital Image Processing in MatlabDokument35 SeitenDigital Image Processing in MatlabHira MazharNoch keine Bewertungen
- Rounding NumbersDokument2 SeitenRounding Numbersputera81Noch keine Bewertungen
- Jec Cie 1 7th SemDokument4 SeitenJec Cie 1 7th SemNaheed SaikiaNoch keine Bewertungen
- Polinoame' PDFDokument3 SeitenPolinoame' PDFBercea Paul CatalinNoch keine Bewertungen
- Analysis of concrete strength and prestressing design for precast concrete plankDokument50 SeitenAnalysis of concrete strength and prestressing design for precast concrete plankJesús Rodríguez RodríguezNoch keine Bewertungen
- Spreaderflex enDokument4 SeitenSpreaderflex enARTMehr Eng. GroupNoch keine Bewertungen
- Testing Concrete Blocks - 2Dokument4 SeitenTesting Concrete Blocks - 2yasir_mushtaq786Noch keine Bewertungen
- Logarithms New JMSDokument4 SeitenLogarithms New JMSKashif ShahNoch keine Bewertungen
- Monte Carlo Simulation: MATH 182Dokument18 SeitenMonte Carlo Simulation: MATH 182Roland ToledoNoch keine Bewertungen
- Eclipse Tutorial 2 Jan 2018Dokument10 SeitenEclipse Tutorial 2 Jan 2018Konul AlizadehNoch keine Bewertungen
- Model Digital Signal ProcessingDokument4 SeitenModel Digital Signal ProcessingnjmnjkNoch keine Bewertungen
- Squares Cubes Powers and RootsDokument12 SeitenSquares Cubes Powers and RootsDavid ReesNoch keine Bewertungen
- Lecture 6-7Dokument46 SeitenLecture 6-7misbahNoch keine Bewertungen
- KYM332 11. HaftaDokument8 SeitenKYM332 11. HaftaHande KorkmazNoch keine Bewertungen
- IISC Lecture on ARIMA Models for Stochastic HydrologyDokument78 SeitenIISC Lecture on ARIMA Models for Stochastic HydrologyTamene AdugnaNoch keine Bewertungen
- Timepix4 SpecsDokument16 SeitenTimepix4 Specsw96ppcqyknNoch keine Bewertungen
- Robotics CT 1Dokument2 SeitenRobotics CT 1Ashutosh SharmaNoch keine Bewertungen
- Summed Area TablesDokument29 SeitenSummed Area TablesDhillonvNoch keine Bewertungen
- FItts' Law - Data AnalysisDokument3 SeitenFItts' Law - Data AnalysisAlexandreNoch keine Bewertungen
- Column DesignDokument36 SeitenColumn DesignDuaa SalehNoch keine Bewertungen
- Time vs Depth and Vrms AnalysisDokument12 SeitenTime vs Depth and Vrms AnalysisOsamah Abdul KadirNoch keine Bewertungen
- 2A Data Description (A)Dokument16 Seiten2A Data Description (A)SEVITHARNE A/P HARI SHANKERNoch keine Bewertungen
- Lab1: Introduction To R: Islr2Dokument10 SeitenLab1: Introduction To R: Islr2rusoNoch keine Bewertungen
- Measuring Diffusivity of Carbon Tetrachloride Using TemperatureDokument19 SeitenMeasuring Diffusivity of Carbon Tetrachloride Using TemperatureSohini RoyNoch keine Bewertungen
- ADokument8 SeitenAJ'son FredNoch keine Bewertungen
- Apparent DipDokument10 SeitenApparent Diptri darma adi waluyoNoch keine Bewertungen
- REPORTDokument12 SeitenREPORTAndi Azis RusdiNoch keine Bewertungen
- # Experiment Name: Introduction To MATLABDokument10 Seiten# Experiment Name: Introduction To MATLABOmor Hasan Al BoshirNoch keine Bewertungen
- Self Assessment 1-2021: Eight Hundred and TwentyDokument3 SeitenSelf Assessment 1-2021: Eight Hundred and TwentyGHANTHIMATHI A/P GOVINDASAMY MoeNoch keine Bewertungen
- J. Am. Chem. Soc. 2017, 139, 18142 18145 - SIDokument23 SeitenJ. Am. Chem. Soc. 2017, 139, 18142 18145 - SIelderwanNoch keine Bewertungen
- Sources of ErrorDokument22 SeitenSources of ErrorHiraya HaeldrichNoch keine Bewertungen
- Math Grade 7Dokument162 SeitenMath Grade 7Abdikhadar Mohamed Ali GadhleNoch keine Bewertungen
- Qbase Isolation DesignDokument27 SeitenQbase Isolation Designprraaddeej chatelNoch keine Bewertungen
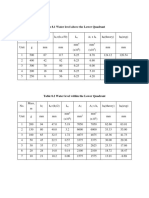
- Water Level Experiment Results AnalysisDokument5 SeitenWater Level Experiment Results AnalysislucasNoch keine Bewertungen
- Pile Settlement Estimator Using Imaginary Footing MethodDokument7 SeitenPile Settlement Estimator Using Imaginary Footing MethodCivilax.comNoch keine Bewertungen
- Building Inspection Report Structure AnalysisDokument6 SeitenBuilding Inspection Report Structure AnalysisSiti Noer FatimahNoch keine Bewertungen
- Assignment 2 SolutionDokument5 SeitenAssignment 2 SolutionRaza KazmiNoch keine Bewertungen
- Plaxis Fahmi Arief Penarosa F11222034Dokument13 SeitenPlaxis Fahmi Arief Penarosa F11222034Andi Azis RusdiNoch keine Bewertungen
- Solution Manual For Applied Numerical Methods With Matlab For Engineers and Science Chapra 3rd EditionDokument25 SeitenSolution Manual For Applied Numerical Methods With Matlab For Engineers and Science Chapra 3rd EditionAndrewMuellerabpom100% (82)
- A Process of Testing Mathematics - Level 2 - Answer KeyDokument6 SeitenA Process of Testing Mathematics - Level 2 - Answer KeyMariaNoch keine Bewertungen
- CLUSTER ANALYSISDokument9 SeitenCLUSTER ANALYSISDevi AfsanahNoch keine Bewertungen
- DSS CATIA ELFINI Verification ManualDokument33 SeitenDSS CATIA ELFINI Verification ManualPabloNoch keine Bewertungen
- Solutions Final Exam June 2019Dokument8 SeitenSolutions Final Exam June 2019Shantha Kumar G CNoch keine Bewertungen
- Lecture-5-Characterization of Collection of Particles-2Dokument21 SeitenLecture-5-Characterization of Collection of Particles-2DikshithaNoch keine Bewertungen
- Plaxis Fahmi Arief Penarosa F11222034Dokument13 SeitenPlaxis Fahmi Arief Penarosa F11222034Andi Azis RusdiNoch keine Bewertungen
- Chapter01 ArtDokument25 SeitenChapter01 Artapi-3717234100% (1)
- CH03 Image+Enhancement+in+the+Spatial+DomainDokument42 SeitenCH03 Image+Enhancement+in+the+Spatial+Domainapi-3717234100% (1)
- CH 14Dokument33 SeitenCH 14api-3717234Noch keine Bewertungen
- CH 09Dokument30 SeitenCH 09api-3717234Noch keine Bewertungen
- CH 17Dokument15 SeitenCH 17api-3717234Noch keine Bewertungen
- CH 07Dokument17 SeitenCH 07api-3717234Noch keine Bewertungen
- CH 15Dokument24 SeitenCH 15api-3717234Noch keine Bewertungen
- CH 20Dokument25 SeitenCH 20api-3717234Noch keine Bewertungen
- CH 18Dokument19 SeitenCH 18api-3717234Noch keine Bewertungen
- CH 16Dokument15 SeitenCH 16api-3717234Noch keine Bewertungen
- Software Engineering: A Practitioner's Approach, 6/eDokument18 SeitenSoftware Engineering: A Practitioner's Approach, 6/ebasit qamar100% (2)
- Software Engineering: A Practitioner's Approach, 6/eDokument42 SeitenSoftware Engineering: A Practitioner's Approach, 6/ebasit qamar100% (2)
- CH 05Dokument19 SeitenCH 05api-3717234Noch keine Bewertungen
- Software Engineering: A Practitioner's Approach, 6/eDokument74 SeitenSoftware Engineering: A Practitioner's Approach, 6/ebasit qamar100% (2)
- CH 06Dokument18 SeitenCH 06api-3717234Noch keine Bewertungen
- CH 03Dokument12 SeitenCH 03api-3717234Noch keine Bewertungen
- CH 02Dokument13 SeitenCH 02api-3717234Noch keine Bewertungen
- CH 04Dokument17 SeitenCH 04api-3717234Noch keine Bewertungen
- CH 01Dokument11 SeitenCH 01api-3717234Noch keine Bewertungen
- World Knowledge and Fuzzy Logic-2004Dokument14 SeitenWorld Knowledge and Fuzzy Logic-2004api-3717234Noch keine Bewertungen
- Fuzzy Probabilities 1984Dokument10 SeitenFuzzy Probabilities 1984api-3717234Noch keine Bewertungen
- Fuzzy Basics PDFDokument38 SeitenFuzzy Basics PDFSoumyadeep BoseNoch keine Bewertungen
- JCST Apr05 4Dokument6 SeitenJCST Apr05 4api-3717234Noch keine Bewertungen
- 37-The Concept of A Linguistic Variable and Its Applications To Approximate Reasoning II-1975Dokument57 Seiten37-The Concept of A Linguistic Variable and Its Applications To Approximate Reasoning II-1975Dr. Ir. R. Didin Kusdian, MT.Noch keine Bewertungen
- Recognizing ConceptDokument8 SeitenRecognizing Conceptapi-3717234Noch keine Bewertungen
- Fuzzy Image RetrievalDokument5 SeitenFuzzy Image Retrievalapi-3717234100% (1)
- The Concept of A Linguistic Variable and Its Applications To Approximate Reasoning I-1975Dokument51 SeitenThe Concept of A Linguistic Variable and Its Applications To Approximate Reasoning I-1975api-3717234100% (1)
- NLP NotesDokument31 SeitenNLP Notesapi-3717234100% (5)
- Image RetrievalDokument12 SeitenImage Retrievalapi-3717234Noch keine Bewertungen
- Image CategorizationDokument27 SeitenImage Categorizationapi-3717234Noch keine Bewertungen
- C86AS0015 - R0 - WorkSiteSecurityPlan PDFDokument38 SeitenC86AS0015 - R0 - WorkSiteSecurityPlan PDFLiou Will SonNoch keine Bewertungen
- Megaplex2100 ManualDokument326 SeitenMegaplex2100 Manualashraf.rahim139Noch keine Bewertungen
- TS80 Soldering Iron User Manual V1.1Dokument23 SeitenTS80 Soldering Iron User Manual V1.1nigger naggerNoch keine Bewertungen
- Mt8870 DTMF DecoderDokument17 SeitenMt8870 DTMF DecoderLawrence NgariNoch keine Bewertungen
- Implementation Guide C2MDokument127 SeitenImplementation Guide C2MLafi AbdellatifNoch keine Bewertungen
- UntitledDokument2 SeitenUntitledmoch bagas setya rahmanNoch keine Bewertungen
- LG CM8440 PDFDokument79 SeitenLG CM8440 PDFALEJANDRONoch keine Bewertungen
- Audio Encryption Optimization: Harsh Bijlani Dikshant Gupta Mayank LovanshiDokument5 SeitenAudio Encryption Optimization: Harsh Bijlani Dikshant Gupta Mayank LovanshiAman Kumar TrivediNoch keine Bewertungen
- Access Token Stealing On WindowsDokument11 SeitenAccess Token Stealing On Windows@4e4enNoch keine Bewertungen
- LENZE 8200 VectorDokument290 SeitenLENZE 8200 VectorAgus Itonk Suwardono100% (2)
- Guidline Nurse Education TodayDokument15 SeitenGuidline Nurse Education TodayaminNoch keine Bewertungen
- Hec RasDokument453 SeitenHec RasED Ricra CapchaNoch keine Bewertungen
- Wind Turbine Generator SoftwareDokument3 SeitenWind Turbine Generator SoftwareamitNoch keine Bewertungen
- Challenges of Emerging Office Technologies and Initiatives of Secretaries of Business Organisations in Lagos StateDokument108 SeitenChallenges of Emerging Office Technologies and Initiatives of Secretaries of Business Organisations in Lagos StateChiemerie Henry NwankwoNoch keine Bewertungen
- Jazler VideoStar 2 User ManualDokument28 SeitenJazler VideoStar 2 User ManualARSENENoch keine Bewertungen
- Labs: Introductio N To Spring 5 and Spring Mvc/Rest (Eclipse/Tom Cat)Dokument34 SeitenLabs: Introductio N To Spring 5 and Spring Mvc/Rest (Eclipse/Tom Cat)darwinvargas2011Noch keine Bewertungen
- Final Year Project Format - UnerDokument5 SeitenFinal Year Project Format - UnerDangyi GodSeesNoch keine Bewertungen
- Pod PDFDokument30 SeitenPod PDFnurten devaNoch keine Bewertungen
- Intel Inside.Dokument25 SeitenIntel Inside.Rashed550% (1)
- GSM WorkflowDokument1 SeiteGSM WorkflowFaisal CoolNoch keine Bewertungen
- GSM Technique Applied To Pre-Paid Energy MeterDokument9 SeitenGSM Technique Applied To Pre-Paid Energy MeterInternational Journal of Application or Innovation in Engineering & ManagementNoch keine Bewertungen
- Assessment Specifications Table (Ast) : Kementerian Pendidikan MalaysiaDokument6 SeitenAssessment Specifications Table (Ast) : Kementerian Pendidikan MalaysiaMohd raziffNoch keine Bewertungen
- A-FMS-1102-Organizational Roles, Responsibilities, Accountabilities, and AuthoritiesDokument2 SeitenA-FMS-1102-Organizational Roles, Responsibilities, Accountabilities, and AuthoritiesMazen FakhfakhNoch keine Bewertungen
- ABB ROBOT Training IRC5 Hardware PDFDokument97 SeitenABB ROBOT Training IRC5 Hardware PDFTensaigaNoch keine Bewertungen
- CD KEY Untuk PerusahaanDokument30 SeitenCD KEY Untuk PerusahaanAriagus BjoNoch keine Bewertungen
- EC20 HMI Connection GuideDokument3 SeitenEC20 HMI Connection GuideGabriel Villa HómezNoch keine Bewertungen
- SGSN ArchitectureDokument17 SeitenSGSN ArchitectureTejNoch keine Bewertungen
- How To Recover MSSQL From Suspect Mode Emergency Mode Error 1813Dokument3 SeitenHow To Recover MSSQL From Suspect Mode Emergency Mode Error 1813Scott NeubauerNoch keine Bewertungen
- June Exam 2018 Feedback.Dokument3 SeitenJune Exam 2018 Feedback.Jordan MorrisNoch keine Bewertungen
- Project Management Institute Indonesia Chapter: at A GlanceDokument37 SeitenProject Management Institute Indonesia Chapter: at A GlanceM R PatraputraNoch keine Bewertungen